KEP-693: Node Topology Manager
KEP-693: Node Topology Manager
- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- References
- Drawbacks
- Alternatives
- Infrastructure Needed (Optional)
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
An increasing number of systems leverage a combination of CPUs and hardware accelerators to support latency-critical execution and high-throughput parallel computation. These include workloads in fields such as telecommunications, scientific computing, machine learning, financial services and data analytics. Such hybrid systems comprise a high performance environment.
In order to extract the best performance, optimizations related to CPU isolation and memory and device locality are required. However, in Kubernetes, these optimizations are handled by a disjoint set of components.
This proposal provides a mechanism to coordinate fine-grained hardware resource assignments for different components in Kubernetes.
Motivation
Multiple components in the Kubelet make decisions about system topology-related assignments:
- CPU manager
- The CPU manager makes decisions about the set of CPUs a container is allowed to run on. The only implemented policy as of v1.8 is the static one, which does not change assignments for the lifetime of a container.
- Device manager
- The device manager makes concrete device assignments to satisfy container resource requirements. Generally devices are attached to one peripheral interconnect. If the device manager and the CPU manager are misaligned, all communication between the CPU and the device can incur an additional hop over the processor interconnect fabric.
- Container Network Interface (CNI)
- NICs including SR-IOV Virtual Functions have affinity to one socket, with measurable performance ramifications.
Related Issues:
- Hardware topology awareness at node level (including NUMA)
- Discover nodes with NUMA architecture
- Support VF interrupt binding to specified CPU
- Proposal: CPU Affinity and NUMA Topology Awareness
Note that all of these concerns pertain only to multi-socket systems. Correct behavior requires that the kernel receive accurate topology information from the underlying hardware (typically via the SLIT table). See section 5.2.16 and 5.2.17 of the ACPI Specification for more information.
Goals
- Arbitrate preferred NUMA Node affinity for containers based on input from CPU Manager and Device Manager.
- Provide an internal interface and pattern to integrate additional topology-aware Kubelet components.
Non-Goals
- Inter-device connectivity: Decide device assignments based on direct device interconnects. This issue can be separated from socket locality. Inter-device topology can be considered entirely within the scope of the Device Manager, after which it can emit possible socket affinities. The policy to reach that decision can start simple and iterate to include support for arbitrary inter-device graphs.
- HugePages: This proposal assumes that pre-allocated HugePages are spread among the available memory nodes in the system. We further assume the operating system provides best-effort local page allocation for containers (as long as sufficient HugePages are free on the local memory node.
- CNI: Changing the Container Networking Interface is out of scope for this proposal. However, this design should be extensible enough to accommodate network interface locality if the CNI adds support in the future. This limitation is potentially mitigated by the possibility to use the device plugin API as a stopgap solution for specialized networking requirements.
Proposal
Main idea: Two phase topology coherence protocol
Topology affinity is tracked at the container level, similar to devices and CPU affinity. At pod admission time, a new component called the Topology Manager collects possible configurations for each container in the pod from the Device Manager and the CPU Manager. The Topology Manager acts as an oracle for local alignment by those same components when they make concrete resource allocations. We expect the consulted components to use the inferred QoS class of each pod in order to prioritize the importance of fulfilling optimal locality.
New Component: Topology Manager
This proposal is focused on a new component in the Kubelet called the
Topology Manager. The Topology Manager implements the pod admit handler
interface and participates in Kubelet pod admission. When the Admit()
function is called, the Topology Manager collects topology hints from other
Kubelet components on either a pod-by-pod, or a container-by-container basis,
depending on the scope that has been set via a kubelet flag.
If the hints are not compatible, the Topology Manager may choose to
reject the pod. Behavior in this case depends on a new Kubelet configuration
value to choose the topology policy. The Topology Manager supports four
policies: none(default), best-effort, restricted and single-numa-node.
A topology hint indicates a preference for some well-known local resources. The Topology Hint currently consists of
- A list of bitmasks denoting the possible NUMA Nodes where a request can be satisfied.
- A preferred field.
- This field is defined as follows:
- For each Hint Provider, there is a possible resource assignment that satisfies the request, such that the least possible number of NUMA nodes is involved (caculated as if the node were empty.)
- There is a possible assignment where the union of involved NUMA nodes for all such resource is no larger than the width required for any single resource.
- This field is defined as follows:
The Effective Resource Request/Limit of a Pod
All Hint Providers should consider the effective resource request/limit to calculate reliable topology hints, this rule is defined by the concept of init containers .
The effective resource request/limit of a pod is determined by the larger of :
- The highest of any particular resource request or limit defined on all init containers.
- The sum of all app containers request/limit for a resource.
The below example shows how it works briefly.
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: appContainer1
resources:
requests:
cpu: 2
memory: 1G
- name: appContainer2
resources:
requests:
cpu: 1
memory: 1G
initContainers:
- name: initContainer1
resources:
requests:
cpu: 2
memory: 1G
- name: initContainer2
resources:
requests:
cpu: 2
memory: 3G
#Effective resource request: CPU: 3, Memory: 3G
The debug /ephemeral containers are not able to specify resource limit/request, so it does not affect topology hint generation.
Scopes
The Topology Manager will attempt to align resources on either a pod-by-pod or a container-by-container basis depending on the value of a new kubelet flag, --topology-manager-scope. The values this flag can take on are detailed below:
container (default): The Topology Manager will collect topology hints from all Hint Providers on a container-by-container basis. Individual policies will then attempt to align resources for each container individually, and pod admission will be based on whether all containers were able to achieve their individual alignments or not.
pod: The Topology Manager will collect topology hints from all Hint Providers on a pod-by-pod basis. Individual policies will then attempt to align resources for all containers collectively, and pod admission will be based on whether all containers are able to achieve a common alignment or not.
Policies
none (default): Kubelet does not consult Topology Manager for placement decisions.
best-effort: Topology Manager will provide the preferred allocation based on the hints provided by the Hint Providers. If an undesirable allocation is determined, the pod will be admitted with this undesirable allocation.
restricted: Topology Manager will provide the preferred allocation based on the hints provided by the Hint Providers. If an undesirable allocation is determined, the pod will be rejected. This will result in the pod being in a
Terminatedstate, with a pod admission failure.single-numa-node: Topology mananager will enforce an allocation of all resources on a single NUMA Node. If such an allocation is not possible, the pod will be rejected. This will result in the pod being in a
Terminatedstate, with a pod admission failure.
The Topology Manager component will be disabled behind a feature gate until graduation from alpha to beta.
Computing Preferred Affinity
After collecting hints from all providers, the chosen Topology Manager policy performs the affinity calcuation to determine the best fit Topology Hint.
The chosen Topology Manager policy then decides to admit or reject the pod based on this hint.
Policy Affinity Calcuation:
- best-effort/restricted (same affinity calculation algorithm for both policies)
- Loops through the list of hint providers and saves an accumulated list of the hints returned by each hint provider.
- Iterates through all permutations of hints accumulated in Step 1. The hint affinites are merged to a single hint by performing a bitwise AND. The preferred field on the merged hint is set to false if any of the hints in the permutation returned a false preferred.
- The hint with the narrowest preferred affinity is returned.
- Narrowest in this case means the least number of NUMA nodes required to satisfy the resource request.
- If no hint with at least one NUMA Node set is found, return a default hint which is a hint with all NUMA Nodes set and preferred set to false.
- single-numa-node
- Loops through the list of hint providers and saves an accumulated list of the hints returned by each hint provider.
- Filters the list of hints accumulated in Step 1 to only include hints with a single NUMA node and nil NUMA nodes.
- Iterates through all permutations of hints filtered in Step 2. The hint affinites are merged to a single hint by performing a bitwise AND. The preferred field on the merged hint is set to false if any of the hints in the permutation returned a false preferred.
- If no hint with a single NUMA Node set is found, return a default hint which is a hint with all NUMA Nodes set and preferred set to false.
Policy Decisions:
- best-effort
- Admits the pod to the node regardless of the Topology Hint stored.
- restricted:
- Admits the pod to the node if the preferred field of the Topology Hint is set to true.
- single-numa-node:
- Admits the pod to the node if the preferred field of the Topology is set to true and the bitmask is set to a single NUMA node.
User Stories (Optional)
Story 1: Fast virtualized network functions
A user asks for a “fast network” and automatically gets all the various pieces coordinated (hugepages, cpusets, network device) in a preferred NUMA Node alignment, in most cases this will be the narrrowest possible set of NUMA Node(s).
Story 2: Accelerated neural network training
A user asks for an accelerator device and some number of exclusive CPUs in order to get the best training performance, due to NUMA Node alignment of the assigned CPUs and devices.
Notes/Constraints/Caveats (Optional)
Limitations
- The maximum number of NUMA nodes that Topology Manager will allow is 8, past this there will be a state explosion when trying to enumerate the possible NUMA affinities and generating their hints.
- The scheduler is not topology-aware, so it is possible to be scheduled on a node and then fail on the node due to the Topology Manager.
Risks and Mitigations
- Testing the Topology Manager in a continuous integration environment depends on cloud infrastructure to expose multi-node topologies to guest virtual machines.
- Implementing the
HintProviderinterface may prove challenging.
Design Details
New Interfaces
package bitmask
// BitMask interface allows hint providers to create BitMasks for TopologyHints
type BitMask interface {
Add(sockets ...int) error
Remove(sockets ...int) error
And(masks ...BitMask)
Or(masks ...BitMask)
Clear()
Fill()
IsEqual(mask BitMask) bool
IsEmpty() bool
IsSet(socket int) bool
IsNarrowerThan(mask BitMask) bool
String() string
Count() int
GetSockets() []int
}
func NewBitMask(sockets ...int) (BitMask, error) { ... }
package topologymanager
// Manager interface provides methods for Kubelet to manage pod topology hints
type Manager interface {
// Implements pod admit handler interface
lifecycle.PodAdmitHandler
// Adds a hint provider to manager to indicate the hint provider
//wants to be consoluted when making topology hints
AddHintProvider(HintProvider)
// Adds pod to Manager for tracking
AddContainer(pod *v1.Pod, containerID string) error
// Removes pod from Manager tracking
RemoveContainer(containerID string) error
// Interface for storing pod topology hints
Store
}
// TopologyHint encodes locality to local resources. Each HintProvider provides
// a list of these hints to the TopoologyManager for each container at pod
// admission time.
type TopologyHint struct {
NUMANodeAffinity bitmask.BitMask
// Preferred is set to true when the BitMask encodes a preferred
// allocation for the Container. It is set to false otherwise.
Preferred bool
}
// HintProvider is implemented by Kubelet components that make
// topology-related resource assignments. The Topology Manager consults each
// hint provider at pod admission time.
type HintProvider interface {
// GetTopologyHints returns a map of resource names with a list of possible
// resource allocations in terms of NUMA locality hints. Each hint
// is optionally marked "preferred" and indicates the set of NUMA nodes
// involved in the hypothetical allocation. The topology manager calls
// this function for each hint provider, and merges the hints to produce
// a consensus "best" hint. The hint providers may subsequently query the
// topology manager to influence actual resource assignment.
GetTopologyHints(pod v1.Pod, containerName string) map[string][]TopologyHint
// GetPodLevelTopologyHints returns a map of resource names with a list of
// possible resource allocations in terms of NUMA locality hints.
// The returned map contains TopologyHint of requested resource by all containers
// in a pod spec.
GetPodLevelTopologyHints(pod *v1.Pod) map[string][]TopologyHint
// Allocate triggers resource allocation to occur on the HintProvider after
// all hints have been gathered and the aggregated Hint is available via a
// call to Store.GetAffinity().
Allocate(pod *v1.Pod, container *v1.Container) error
}
// Store manages state related to the Topology Manager.
type Store interface {
// GetAffinity returns the preferred affinity as calculated by the
// TopologyManager across all hint providers for the supplied pod and
// container.
GetAffinity(podUID string, containerName string) TopologyHint
}
// Policy interface for Topology Manager Pod Admit Result
type Policy interface {
// Returns Policy Name
Name() string
// Returns a merged TopologyHint based on input from hint providers
// and a Pod Admit Handler Response based on hints and policy type
Merge(providersHints []map[string][]TopologyHint) (TopologyHint, lifecycle.PodAdmitResult)
}
Listing: Topology Manager and related interfaces (sketch).

Figure: Topology Manager components.

Figure: Topology Manager instantiation and inclusion in pod admit lifecycle.
Changes to Existing Components
- Kubelet consults Topology Manager for pod admission (discussed above.)
- Add two implementations of Topology Manager interface and a feature gate.
- As much Topology Manager functionality as possible is stubbed when the feature gate is disabled.
- Add a functional Topology Manager that queries hint providers in order to compute a preferred socket mask for each container.
- Add
GetTopologyHints()andGetPodLevelTopologyHints()method to CPU Manager.- CPU Manager static policy calls
GetAffinity()method of Topology Manager when deciding CPU affinity.
- CPU Manager static policy calls
- Add
GetTopologyHints()andGetPodLevelTopologyHints()method to Device Manager.- Add
TopologyInfoto Device structure in the device plugin interface. Plugins should be able to determine the NUMA Node(s) when enumerating supported devices. See the protocol diff below. - Device Manager calls
GetAffinity()method of Topology Manager when deciding device allocation.
- Add
diff --git a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
index efbd72c133..f86a1a5512 100644
--- a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
+++ b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
@@ -73,6 +73,10 @@ message ListAndWatchResponse {
repeated Device devices = 1;
}
+message TopologyInfo {
+ repeated NUMANode nodes = 1;
+}
+
+message NUMANode {
+ int64 ID = 1;
+}
+
/* E.g:
* struct Device {
* ID: "GPU-fef8089b-4820-abfc-e83e-94318197576e",
* State: "Healthy",
+ * Topology:
+ * Nodes:
+ * ID: 1
@@ -85,6 +89,8 @@ message Device {
string ID = 1;
// Health of the device, can be healthy or unhealthy, see constants.go
string health = 2;
+ // Topology details of the device
+ TopologyInfo topology = 3;
}
Listing: Amended device plugin gRPC protocol.

Figure: Topology Manager hint provider registration.
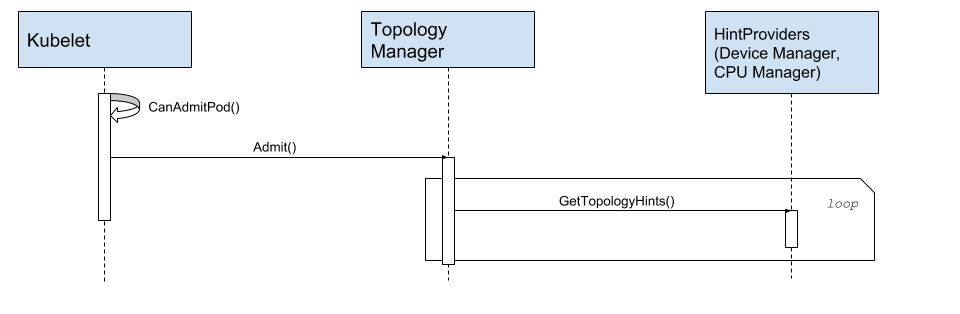
Figure: Topology Manager fetches affinity from hint providers.
Additionally, we propose an extension to the device plugin interface as a
“last-level” filter to help influence overall allocation decisions made by the
devicemanager. The diff below shows the proposed changes:
diff --git a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
index 758da317fe..1e55d9c541 100644
--- a/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
+++ b/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto
@@ -55,6 +55,11 @@ service DevicePlugin {
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
+ // GetPreferredAllocation returns a preferred set of devices to allocate
+ // from a list of available ones. The resulting preferred allocation is not
+ // guaranteed to be the allocation ultimately performed by the
+ // `devicemanager`. It is only designed to help the `devicemanager` make a
+ // more informed allocation decision when possible.
+ rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
+
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
@@ -99,6 +104,31 @@ message PreStartContainerRequest {
message PreStartContainerResponse {
}
+// PreferredAllocationRequest is passed via a call to
+// `GetPreferredAllocation()` at pod admission time. The device plugin should
+// take the list of `available_deviceIDs` and calculate a preferred allocation
+// of size `size` from them, making sure to include the set of devices listed
+// in `must_include_deviceIDs`.
+message PreferredAllocationRequest {
+ repeated string available_deviceIDs = 1;
+ repeated string must_include_deviceIDs = 2;
+ int32 size = 3;
+}
+
+// PreferredAllocationResponse returns a preferred allocation,
+// resulting from a PreferredAllocationRequest.
+message PreferredAllocationResponse {
+ ContainerAllocateRequest preferred_allocation = 1;
+}
+
// - Allocate is expected to be called during pod creation since allocation
// failures for any container would result in pod startup failure.
// - Allocate allows kubelet to exposes additional artifacts in a pod's
Using this new API call, the devicemanager will call out to a plugin at pod
admission time, asking it for a preferred device allocation of a given size
from a list of available devices. One call will be made per-container for each
pod.
The list of available devices passed to the GetPreferredAllocation() call
do not necessarily match the full list of available devices on the system.
Instead, the devicemanager treats the GetPreferredAllocation() call as
a “last-level” filter on the set of devices it has to choose from after taking
all TopologyHint information into consideration. As such, the list of
available devices passed to this call will already be pre-filtered by the
topology constraints encoded in the TopologyHint.
The preferred allocation is not guaranteed to be the allocation ultimately
performed by the devicemanager. It is only designed to help the
devicemanager make a more informed allocation decision when possible.
When deciding on a preferred allocation, a device plugin will likely take
internal topology-constraints into consideration, that the devicemanager is
unaware of. A good example of this is the case of allocating pairs of NVIDIA
GPUs that always include an NVLINK.
On an 8 GPU machine, with a request for 2 GPUs, the best connected pairs by NVLINK might be:
{{0,3}, {1,2}, {4,7}, {5,6}}
Using GetPreferredAllocation() the NVIDIA device plugin is able to forward
one of these preferred allocations to the device manager if the appropriate set
of devices are still available. Without this extra bit of information, the
devicemanager would end up picking GPUs at random from the list of GPUs
available after filtering by TopologyHint. This API, allows it to ultimately
perform a much better allocation, with minimal cost.
Noteworthy developments since Topology Manager introduction
- Update Topology Manager algorithm for selecting “best” non-preferred hint In case of best-effort policy for Topology Manager, non-prefferered allocations are considered in cases where resources need to be allocated from multiple NUMA nodes. For determining the best non-preferred hint, simply selecting the narrowest possible hint is not ideal and an improvement was made to handle scenarios where perfect alignment from a single NUMA node is not possible.
- Ability to take NUMA distances into consideration
A new topology manager option was introduced which when enabled with
prefer-closest-numa-nodesoption was fine tunes the behavior of existingrestrictedandbest-effortpolicies. NUMA nodes with shorter distance between them would be favored when making admission decisions.
Test Plan
There is a presubmit job for Topology Manager, that will be run on all PRs. This job is here: https://testgrid.k8s.io/wg-resource-management#pr-kubelet-serial-gce-e2e-topology-manager
There is a CI job for Topology Manager that will run periodically. This job is here: https://testgrid.k8s.io/wg-resource-management#pr-kubelet-serial-gce-e2e-topology-manager
The Topology Manager E2E test will enable the Topology Manager feature gate and set the CPU Manager policy to ‘static’.
At the beginning of the test, the code will determine if the system under test has support for single or multi-NUMA nodes.
Single NUMA Systems Tests
For each of the four topology manager policies, the tests will run a subset of the current CPU Manager tests. This includes spinning up non-guaranteed pods, guaranteed pods, and multiple guaranteed and non-guaranteed pods. As with the CPU Manager tests, CPU assignment is validated. Tests related to multi-NUMA systems will be skipped, and a log will be generated indicating such.
Multi-NUMA Systems Tests
For each of the four topology manager policies, the tests will spin up guaranteed pods and non-guaranteed pods, requesting CPU and device resources. When the policy is set to single-numa-node for guaranteed pods, the test will verify that guaranteed pods resources (CPU and devices) are aligned on the same NUMA node. Initially, the test will request SR-IOV devices, utilizing the SR-IOV device plugin.
Future Tests
It would be good to add additional devices, such as GPU, in the multi-NUMA systems test.
[X] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Prerequisite testing updates
Unit tests
k8s.io/kubernetes/pkg/kubelet/cm/topologymanager:20230116-92.6%
Integration tests
Not Applicable.
e2e tests
Device Manager and Device plugin node e2e tests:
Graduation Criteria
Alpha (v1.16) [COMPLETED]
- Feature gate is disabled by default.
- Alpha-level documentation.
- Unit test coverage.
- CPU Manager allocation policy takes topology hints into account.
- Device plugin interface includes NUMA Node ID.
- Device Manager allocation policy takes topology hints into account
Alpha (v1.17) [COMPLETED]
- Allow pods in all QoS classes to request aligned resources.
Beta (v1.18) [COMPLETED]
- Enable the feature gate by default.
- Provide beta-level documentation.
- Add node E2E tests.
- Additional tests are in Testgrid and linked in KEP
- Guarantee aligned resources for multiple containers in a pod.
- Refactor to easily support different merge strategies for different policies.
Beta (v1.20) [COMPLETED]
- Support pod-level resource alignment.
GA (stable) [COMPLETED]
- N examples of real-world usage
- N installs
- More rigorous forms of testing.
- Allowing time for user feedback.
- Support hugepages alignment.
Deprecation
- Announce deprecation and support policy of the existing flag
- Two versions passed since introducing the functionality that deprecates the flag (to address version skew)
- Address feedback on usage/changed behavior, provided on GitHub issues
- Deprecate the flag
Upgrade / Downgrade Strategy
Not Applicable.
Version Skew Strategy
This feature is kubelet specific, so version skew strategy is N/A.
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
- Feature gate (also fill in values in
kep.yaml)- Feature gate name: TopologyManager
- Components depending on the feature gate: kubelet
Kubelet Flag for the Topology Manager Policy, which is described above. The none policy will be the default policy.
- Proposed Policy Flag:
--topology-manager-policy=none|best-effort|restricted|single-numa-node
Based on the policy chosen, the following flag will determine the scope with which the policy is applied (i.e. either on a pod-by-pod or a container-by-container basis). The container scope will be the default scope.
- Proposed Scope Flag:
--topology-manager-scope=container|pod
Does enabling the feature change any default behavior?
If just the feature gate is enabled, there is no change in behavior as Topology Manager policy
defaults to none policy. In this case, kubelet does not consult Topology Manager and does not influence
the placement decision (which is the defult behavior).
If Topology Manager is configured with single-numa-node or restricted policy, the admission flow
changes for a pod where at least two of the following is true:
- Node is using the static CPU manager policy (if true, implies pod is Guaranteed QoS )
- Pod consumes some device A that exports locality hints
- Pod consumes some device B that exports locality hints
- Node is using the static Memory manager policy (if true, implies pod is Guaranteed QoS )
- Pod consuming pre-allocated hugepages
Topology Manager takes into account hints received from hint providers like CPU Manager, Memory Manager and Device Manager to either admit a pod to the node or reject it.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Since going to stable in 1.27, the feature gate is locked on as is the standard practice in Kubernetes.
What happens if we reenable the feature if it was previously rolled back?
No impact on running pods in the cluster. Subsequent pods that meet the requirement as explained above would go through admission check and aligned based on the configured policy.
Are there any tests for feature enablement/disablement?
Yes, covered by node e2e tests:
https://github.com/kubernetes/kubernetes/blob/master/test/e2e_node/topology_manager_test.go
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
A rollout can fail in case a bug is introduced in topology manager preventing already running pods from restarting or new pods to start.
What specific metrics should inform a rollback?
topology_manager_admission_errors_total can be used to determine the health of the
feature and can be be used to determine if a rollback needs to be performed. It is
worth noting that there could be valid cases where a pod is denied admission.
Example of a valid error is TopologyAffinityError which is returned when topology
manager is configured with single-numa-node but there are not enough resources
available on a single numa node.
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
No. Changes in behavior only affects pods meeting the conditions scheduled after the upgrade. Running pods will be unaffected by any change. This offers some degree of safety in both upgrade->rollback and upgrade->downgrade->upgrade scenarios.
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
No
Monitoring Requirements
Monitor the following metrics:
“topology_manager_admission_requests_total” “topology_manager_admission_errors_total” “topology_manager_admission_duration_seconds”
How can an operator determine if the feature is in use by workloads?
The operator can look at topology_manager_admission_requests_total, topology_manager_admission_errors_total and
topology_manager_admission_duration_seconds metrics to determine if topology manager is performing its admission check.
In addition to that, kubelet configuration of the nodes can be inspected to check feature gates and the policies
configured.
How can someone using this feature know that it is working for their instance?
Other (treat as last resort)
- Details:
By design, NUMA information is hidden from the end users and is only known to kubelet running on the node. In order to validate that the allocated resources are NUMA aligned, we need this information to be exposed. The only possible way is with the help of external tools that inspect the resource topology information and either expose it external to the node (e.g. NFD topology updater ) or use it to perform validation themselves (numaalign ). Here are a few possible options (with external help):
- In case Topology manger is configured with
single-numa-nodepolicy and CPU Manager withstatic policyUsing NFD topology updater, we can learn about the number of allocatable CPUs on a NUMA node and deploy a pod with CPUs greater than we have available on a single NUMA node. In that case, the pod would return aTopologyAffinityErrorand is visible to the end user. - Alternatively, we can use a tool like numaalign and run that within a pod to determine if a set of resources are aligned on the same NUMA node.
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
“topology_manager_admission_duration_seconds” (which will be added as this release) can be used to determine if the resource alignment logic performed at pod admission time is taking longer than expected.
Measurements haven’t been performed to determine the latency as this metric will be introduced in 1.27 development cycle but the duration is expected to be very short most likely in the ballpark of 50-100 ms.
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
- topology_manager_admission_requests_total
- topology_manager_admission_errors_total
- topology_manager_admission_duration_seconds
- Metric name:
Are there any missing metrics that would be useful to have to improve observability of this feature?
No.
Dependencies
No.
Does this feature depend on any specific services running in the cluster?
No.
Scalability
Topology Manager is a component within kubelet for alignment of resources based on resource distribution across NUMA nodes and configured policy. Since this is a node-local feature, there are no calls to the API server or to the cloud provider and hence does not impact scalability.
Will enabling / using this feature result in any new API calls?
No, this is a node-local feature.
Will enabling / using this feature result in introducing new API types?
No, this is a node-local feature.
Will enabling / using this feature result in any new calls to the cloud provider?
No, this is a node-local feature.
Will enabling / using this feature result in increasing size or count of the existing API objects?
No.
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
Yes
This feature would impact the pod startup latency as it is measured from the time pod object is created and the resource alignment logic is executed at pod admission time. The check at admission is to determine if the pod is suitable to be admitted on the node based on the configured policy. If considered suitable, the pod is deemed suitable to be admitted on a node followed by the pod startup where resources are allocated to it based on the NUMA node identified suitable to allocate resource. Since Topology Manager supports a maximum of 8 NUMA nodes, pod startup latency has an upper bound for the additional latency introduced by the Topology Manager admission check.
This feature is not impacted by the scale of the cluster (number of nodes in the cluster) as that is not relevant and is not factored into the alignment algorithm. It is the scheduler that has to deal with the scalability aspect and determine nodes that can fulfill the resources requested by the pod. If this feature is turned off, the scheduler would still have to perform the same computation as it would if this feature was enabled. Hence, this feature is not impacted by scale or impacts the scalability of a cluster.
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No reported or known increase in resource usage.
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No.
The feature is only responsble for alignment of resources. It does not use node resources like PIDs, sockets, inodes, etc. for running its alignment algorithm.
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
No impact. This feature is not impacted by unavailability of API Server and/or etcd as it is a node local feature.
What are other known failure modes?
No known failure modes.
What steps should be taken if SLOs are not being met to determine the problem?
Implementation History
- 2018-01-25: Topology Manager proposal submitted to the community repo (https://github.com/kubernetes/community/pull/1680) .
- 2019-01-08: Topology Manager proposal merged.
- 2019-01-30: Proposal moved to enhancement repo (https://github.com/kubernetes/enhancements/pull/781) .
- 2023-01-16: KEP ported to the most recent template and GA graduation.
References
Drawbacks
Not Applicable.
Alternatives
AutoNUMA : This kernel feature affects memory allocation and thread scheduling, but does not address device locality.
Infrastructure Needed (Optional)
Multi-NUMA hardware is needed for testing of this feature. Recently, support for multi-NUMA harware was added in Kubernetes test infrastructure.