KEP-6122: Configurable Scaling Delay with Pod Resource Exposure
KEP-6122: Configurable Scaling Delay with Pod Resource Exposure
- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- 1. LIFO (Last-In, First-Out) CPU Release
- 2. CPU Release Based on Real-Time Usage
- 3. Immediate Actuation (No Delay)
- 4. Handshake-Based Synchronization
- 5. Node Declared Features as Opt-Out Mechanism
- 6. Pod-Level Grace Period (Opt-In/Opt-Out Mechanism)
- 7. Hook-Based Synchronization Approach
- 8. Generalizing Scale-Down Delay to Other Resource Types
- Infrastructure Needed (Optional)
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests within one minor version of promotion to GA
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
This proposal introduces a new option, scale-delay-time, in the CPU Manager static policy. The scale-delay-time option ensures the updated cpuset is not applied sooner than the specified delay after a container scale-down event.
This proposal also extends the downward API volume to expose the CPUs assigned to containers. This extension is controlled by the new DownwardAPIAssignedResources feature gate.
Together, these two features allow latency-sensitive applications to obtain the assigned cpuset in advance via the downward API. This enables workloads to prepare for CPU removal triggered by scale-down within the guaranteed delay window scale-delay-time. As a result, performance degradation caused by sudden CPU loss is avoided.
Motivation
Latency-sensitive applications often require exclusive CPUs to achieve predictable performance and resource isolation. These applications commonly use CPU affinity to minimize performance degradation caused by CPU migration.
When scaling down, guaranteed QoS pods need to know in advance which CPUs will be removed from their cpuset. This allows latency-sensitive applications to take preparatory actions — such as migrating workloads away from affected CPUs — and avoid performance degradation caused by CPU migration and core sharing during the removal of active CPUs.
This KEP depends on KEP-1287 , which allows Pods (without exclusive CPUs) to update their resource requests and limits in-place, and KEP-5554 , which extends this feature to support guaranteed QoS Pods with exclusive CPUs to resize without restarts. The scale-down delay feature only applies to in-place resize enabled by KEP-1287 and exclusive CPUs resize enabled by KEP-5554.
Note: This KEP was originally considered as part of KEP-5554 but was separated to keep KEP-5554 focused on the core scaling functionality. This KEP introduces two complementary features: configurable scale-down delay and exposure of assigned CPU sets via the Downward API. These features are independent of the basic scaling mechanism and can be implemented and adopted separately.
Note: This KEP depends on three feature gates. Two of them (
InPlacePodVerticalScalingExclusiveCPUsandCPUManagerPolicyAlphaOptions) are already available in Kubernetes. This KEP only introduces one new feature gate:DownwardAPIAssignedResources.
Goals
- Expose CPUSet assignments to containers via the downward API volume with
DownwardAPIAssignedResourcesfeature gate enabled:assigned.cpuset: the desired exclusive cpuset (Linux cpuset format, e.g.0-3,7,12-15). Empty string when no exclusive CPUs are assigned.
- Wait at least the configured
scale-delay-timebefore applying the new cpuset configuration when a container scales down. - The
scale-delay-timeoption applies to the entire kubelet. Its value must be between 0s and 10s. Setting it to 0s preserves the existing behavior (no delay before applying the cpuset), whereas 10s is the maximum allowed value.
Non-Goals
- Add new CPU manager policies.
- Allow containers to specify which CPUs to remove during scale-down.
- Scale-down delay for PodLevelResourceManagers: The scale-down delay introduced by this KEP does not apply to resources managed by
PodLevelResourceManagers(KEP-5526).PodLevelResourceManagersdoes not support In-Place scaling for pod-level resources. Additionally, KEP-5554 (which enables In-Place scaling of exclusive CPU at the container level) excludes scaling for pods that define pod-level resources.
Proposal
This proposal introduces a new scale-delay-time option for the CPU Manager static policy. The option specifies the minimum delay before applying an updated cpuset when a container has its CPU allocation scaled down.
During the delay window, the container continues to use the current cpuset for at least the configured scale-delay-time. This allows latency-sensitive workloads to monitor and prepare for the upcoming CPUSet change before CPU(s) are removed from the container. The minimum delay must be guaranteed at all times, including during kubelet restarts.
This proposal also extends the Downward API volume to expose CPU Manager cpuset information through a new assigned.cpuset resource field. During the delay window, assigned.cpuset exposes the desired cpuset so that workloads can prepare for the upcoming change. Exposition of new field is gated by the DownwardAPIAssignedResources feature gate.
This proposal does not require a handshake (acknowledgment) from the workload, because the scale-delay-time is configured based on the workload’s needed reaction time, providing a guaranteed time window for the workload to react to the upcoming cpuset change.
Use Cases
- A Pod with one container is allocated 4 CPUs: {1, 2, 11, 12}, where {1, 11} are the initially assigned CPUs. DPDK workers are deployed on each core.
- When the container’s CPU request scales down from 4 to 3, the CPU manager assigns a new cpuset {1, 2, 11}. Subsequently, the Downward API Volume (/etc/podinfo/assigned_cpuset) within the container is updated with the CPU Manager’s state information (cpuset allocated in the CPU manager).
- After waiting at least
scale-delay-time, the new cpuset {1, 2, 11} is applied to the container. And later, once applied, kubelet marks the container resize as successful. - During the interval between the update of the Downward API Volume and the new cpuset application, the container can perform necessary preparations for the DPDK workers.
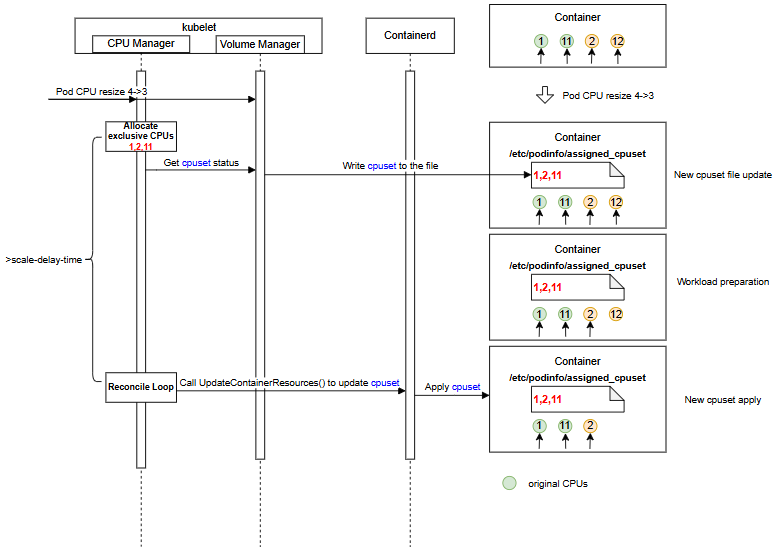
Risks and Mitigations
When scale-delay-time is configured on a node, the delay applies to all guaranteed pods with exclusive CPUs — not only those that need it. This means even pods without latency-sensitive workloads will experience the delayed cpuset application during scale-down.
Mitigation in Alpha: Operators are recommended to taint nodes that have scale-delay-time configured, so that only pods with corresponding tolerations are scheduled to those nodes. This effectively provides an opt-in mechanism at the node level.
Future improvement: In Alpha2/Beta, a more granular opt-out mechanism will be investigated, such as using taints, labels/annotations or other mechanisms to allow pods to opt out of the scale-down delay at the pod level.
Workload may not complete preparations within the delay window: The kubelet guarantees only that the cpuset will not be applied before scale-delay-time has elapsed. There is no synchronization mechanism between the workload and kubelet — if the workload fails to complete its preparations (e.g., workload migration, draining tasks) within the delay window, the cpuset change is applied anyway. This is an inherent limitation of keeping kubelet independent from workload state.
Mitigation: Operators should configure scale-delay-time based on the worst-case preparation time required by their latency-sensitive workloads. Workloads should be designed to handle premature CPU removal gracefully (e.g., by quickly migrating tasks to remaining CPUs or tolerating brief performance degradation). The assigned.cpuset field in the Downward API provides early notification of the upcoming change, giving workloads the maximum possible preparation time.
Security Considerations: Exposing assigned.cpuset via Downward API does not introduce new security risks. The same CPU assignment information is already accessible to applications from inside the container via /proc/self/cgroup controllers and from the node level. The assigned.cpuset field only exposes CPU IDs (e.g., 0-3,7,12-15), not NUMA topology information. This KEP simply exposes the assigned CPUset in advance (during the scale-down delay window) without creating new data recipients or adding new security risks.
Design Details
Implementation
The overview of the design:
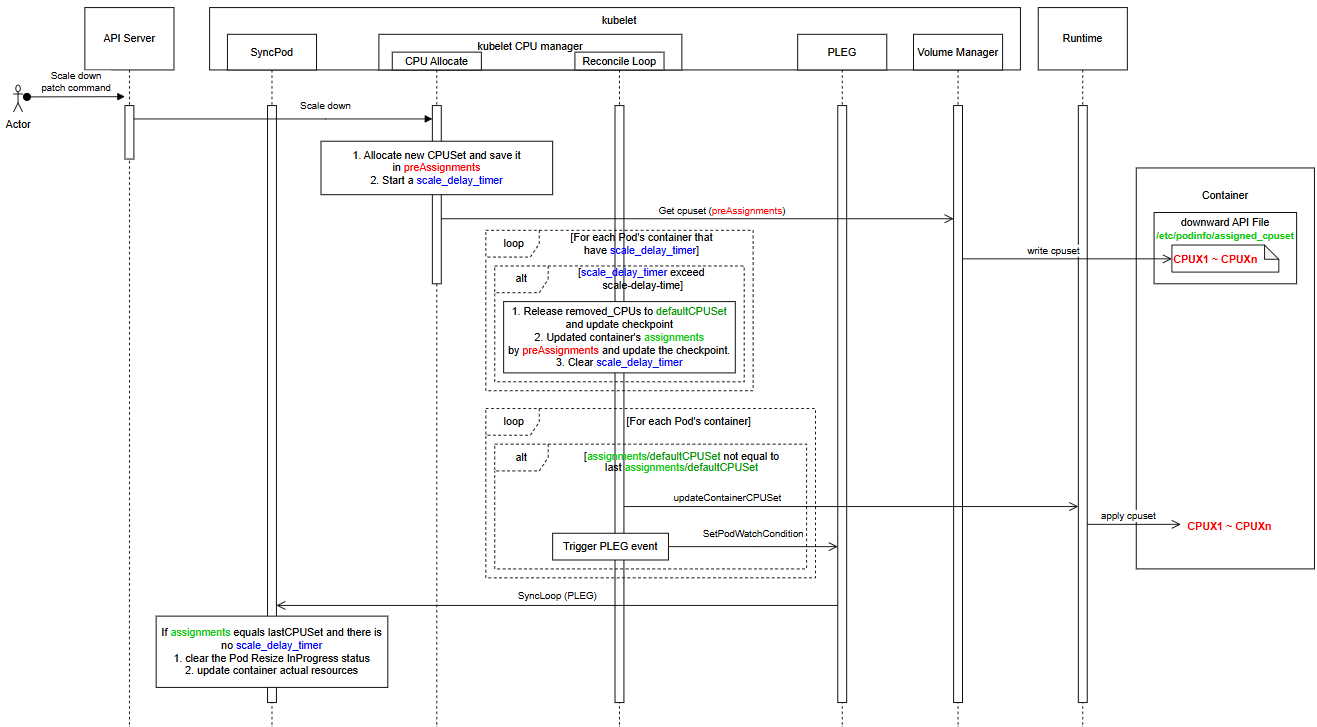
The basic flow shown in the diagram is as follows:
- During allocation of new CPUSets, changes are not applied to assignments immediately but kept in preAssignments, and scale_delay_timers are started.
- Downward API exposes the new CPUSets in preAssignments to the container.
- During cpuset actuation, containers scaling down (with active
scale_delay_timer) are skipped if the scale-delay-time has not yet elapsed. For those where the time has passed, preAssignments are written to assignments and actuated in containers. - The SyncPod processes two actions after there are no active scale_delay_timer on the pod, and actuated states equal the allocated ones:
- Marking the resize as completed
- Updating the actual resources
When a scale-down operation is started and accepted for processing, it is handled by the AllocationManager. The AllocationManager delegates allocation of new CPUSets to the CPUManager. The CPUManager allocates new CPUs, and at this point the synchronous control of resize is completed.
There are 2 more asynchronous actions:
- The CPUManager actuates the cpuset in the container to reflect the allocated state.
- The SyncPod loop updates actual resources and marks the pod resize as completed when all actuated states equal the allocated ones.
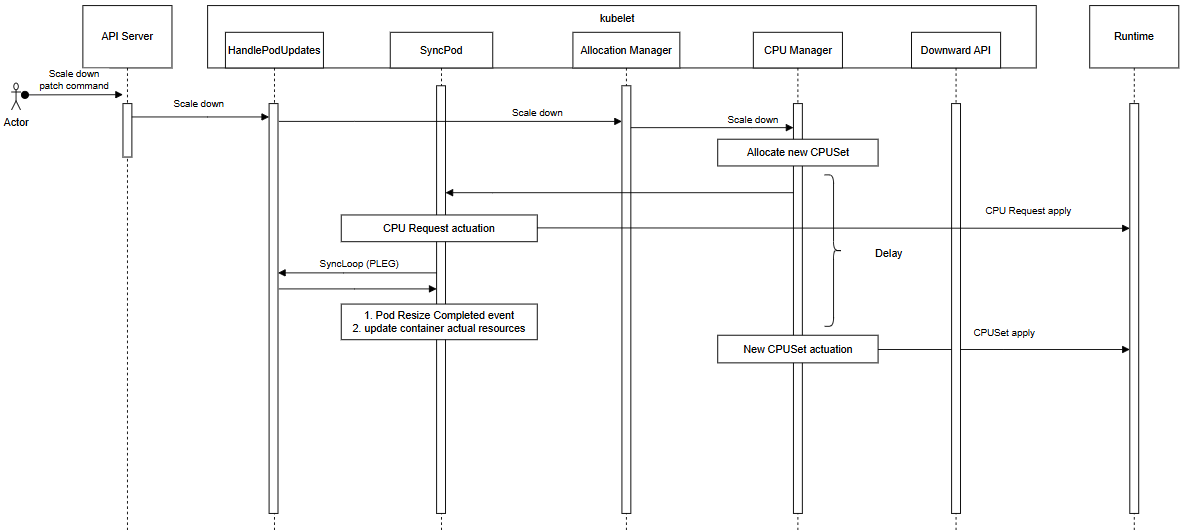
The existing flow (before applying this KEP) among AllocationManager, CPUManager, and SyncPod is as follows:
The flow after the modifications introduced by this KEP is as follows:
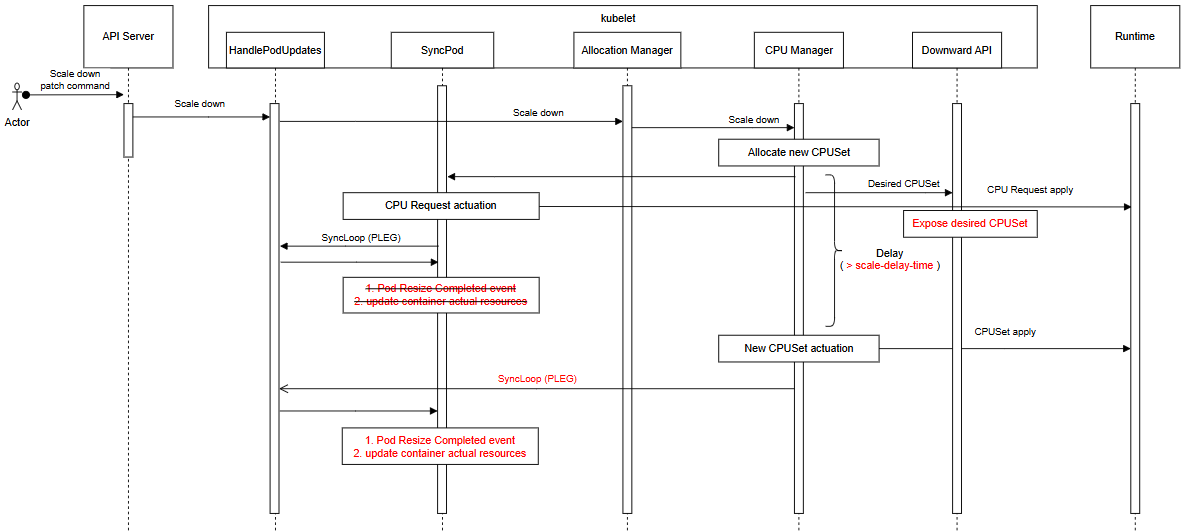
Regarding the ownership of resize:
- AllocationManager is responsible for accepting resize and triggering the allocation phase. This KEP does not modify this part.
- CPUManager is responsible for:
- Allocating CPUs (with this KEP, when scaling down, starting a scale_delay_timer and saving the new cpuset in preAssignments).
- Actuating cpuset in containers (with this KEP, after the scale_delay_timer expires, applying the new cpuset).
- SyncPod loop is responsible for
- Updating pod resize status (with this KEP, clears PodResizeInProgress when all actuated states equal the allocated ones).
- Updating container actual resources (with this KEP, update actual resources when actuated states equal the allocated ones).
Scale Down Delay in CPU Manager
Add an option scale-delay-time in the CPU Manager’s static policy
const (
FullPCPUsOnlyOption string = "full-pcpus-only"
DistributeCPUsAcrossNUMAOption string = "distribute-cpus-across-numa"
AlignBySocketOption string = "align-by-socket"
DistributeCPUsAcrossCoresOption string = "distribute-cpus-across-cores"
StrictCPUReservationOption string = "strict-cpu-reservation"
PreferAlignByUnCoreCacheOption string = "prefer-align-cpus-by-uncorecache"
// ⚠️ new option
ScaleDelayTimeOption string = "scale-delay-time"
)
The scale-delay-time value must be in the range [0s, 10s]. Negative values are not allowed. It can be specified in seconds or milliseconds, for example: ‘5s’, or ‘500ms’.
The default value of scale-delay-time is 0s, meaning the existing behavior is preserved — no guaranteed delay is enforced before the cpuset is applied.
When InPlacePodVerticalScalingExclusiveCPUs is disabled, scale-delay-time must be 0; otherwise, the kubelet will emit a warning and reject the configuration.
In the Allocate CPU stage: Allocate a new CPUSet based on the container’s assignments and defaultCPUset in the checkpoint (all references to “checkpoint” below refer to cpu_manager_state).
When a container scales down (If the CPU number of assignments in checkpoint > CPU request and limit for the container Pod Spec):
- If the
scale-delay-timeis 0, the container’s scale down behavior is the same as before, after reallocating the new cpuset:- The removed_CPUs (assignments in checkpoint - new cpuset) are added to the defaultCPUset
- The container’s assignments are updated to the new cpuset
- CPU manager checkpoint is updated immediately with new assignments and defaultCPUSet.
- If the
scale-delay-timeis not 0, after reallocating the new cpuset:- A scale_delay_timer starts after the new cpuset is allocated. (monotonic time should be considered)
- The new cpuset is saved in preAssignments, which is a local parameter in the CPU manager.
When a container scales up (If the CPU number of assignments in checkpoint <= CPU request and limit for the container in Pod Spec), after reallocating the new cpuset:
- The added_CPUs (new cpuset - assignments in checkpoint) are removed from the defaultCPUset.
- The container’s assignments are updated.
- CPU manager checkpoint is updated immediately with new assignments and defaultCPUSet.
- If the
scale-delay-timeis not 0:- The scale_delay_timer and preAssignment are cleared if they exist
When kubelet restarts during a pod scale-down delay time, the pod will restart the scale_delay_timer and reallocate the new cpuset.
- If the
When cpuset actuation time is reached: If scale_delay_timer exists for a container, and after the scale_delay_timer has expired:
- The removed_CPUs (assignments in checkpoint - preAssignments) are released to the defaultCPUset.
- The container’s assignments are updated to preAssignments.
- CPU manager checkpoint is updated immediately with new assignments and defaultCPUSet.
- The scale_delay_timer and preAssignments are cleared.
If the cpuset (assignments) differs from lastCPUSet for a container:
- The CPUSet(assignments) is applied to the container by the runtime.
- If the CPUSet(assignments) is an exclusive CPUSet, a PLEG event is triggered.
Note: If the kubelet restarts during a pending scale-down delay, the scale-down operation is restarted from the beginning with a fresh scale_delay_timer. This is because the CPU Manager does not persist preAssignments or active timers to the checkpoint — only the current assignments (the original cpuset before scale-down) are preserved. Upon restart, the kubelet observes a mismatch between the container’s desired CPU request (from the Pod spec) and the allocated CPUs (from the checkpoint), triggering a new allocation cycle. This results in new preAssignments being created and a new scale_delay_timer being started, ensuring the full scale-delay-time delay is guaranteed even after a restart.
Scale-Down Delay Timing
From the time a new cpuset is allocated to when it is actually applied, there is a delay. The minimum guaranteed delay before the new cpuset is applied is scale-delay-time. The actual delay may be longer than scale-delay-time depending on when the cpuset actuation occurs, but is guaranteed to be no less than scale-delay-time.
The following diagrams illustrate the two cases.
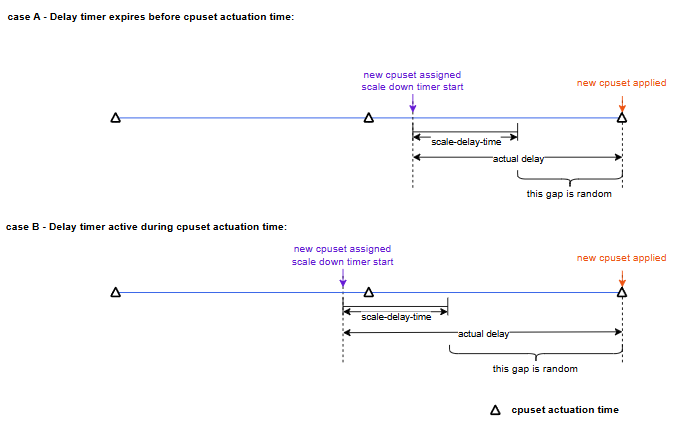
Case A: Timer expires before cpuset actuation time — The scale_delay_timer expires between two cpuset actuation times. Since the timer has already expired when the next actuation time arrives, the new cpuset is applied at that actuation time as it normally would. In this case, the scale_delay_timer does not affect the actual time when the cpuset is applied.
Case B: Timer active during cpuset actuation time — The scale_delay_timer is still active when the next cpuset actuation time arrives. The new cpuset cannot be applied at this actuation time because the timer has not yet expired. It is applied at the next actuation time after the timer expires. In this case, the actual delay is longer than the normal delay.
In both cases, the actual delay is at least scale-delay-time, but may be longer due to the gap between timer expiry and the cpuset actuation time.
Consecutive Scaling
When another scale-down request arrives while a scale-down is already in progress (i.e., the scale_delay_timer is active), the CPU Manager allocates a new cpuset (which is stored in preAssignments, replacing the previous one) and resets the timer, so the delay starts again from the beginning.
When a scale-up request arrives while a scale-down is in progress, the behavior depends on the resulting CPU count:
- If the new CPU count is greater than or equal to the original (pre-scale-down) CPU count, it is effectively a scale-up: the assignments are updated directly (not via preAssignments), and the scale_delay_timer and preAssignments are cleared.
- If the new CPU count is still lower than the original CPU count, it is effectively a scale-down: the preAssignments are updated with the new cpuset, and the scale_delay_timer is reset.
Resize Complete State
The pod resize completed event (Pod Lifecycle Event) is not emitted until the new cpuset has been successfully applied to all containers in the pod. Only then is the pod resize considered complete.
In SyncPod(), the Pod Resize InProgress status is cleared only when the allocated cpusets equal actuated ones and no scale_delay_timer is active for any container, in addition to the existing conditions. This indicates the pod resize is complete. These new conditions are evaluated by the CPU Manager, which is queried from SyncPod() via the Container Manager.
Actual Resources Update
The actual resources are used by the scheduler to calculate the available CPU number for the node (see KEP-1287 ). The actual resources reflect the container resource current state, reported by the runtime.
When a pod resize passes admission, the CPU request is applied immediately (updating cpu.weight in cgroup v2), but the cpuset is applied after a delay. Therefore, in convertToAPIContainerStatuses, before the cpuset is applied, the actual resources are not updated; after the cpuset is applied (i.e., after at least the scale-delay-time expires and the new cpuset is applied), the actual resources are converted to the current cpu.weight value.
Note: Before the checkpoint is updated and the cpuset is applied, if the runtime-reported CPU resource request (value from cpu.weight in cgroup v2) were used to update the actual resources during the delay, it would cause a mismatch between the available CPU number reported to the scheduler and the actual available CPUs in kubelet. This would result in a new pod being scheduled to the node but failing to allocate CPU resources, leading to an UnexpectedAdmissionError. Deferring the actual resources update until after cpuset application prevents this scenario from occurring.
Extend Downward API Volume to Expose CPU Manager Status
A new field assigned.cpuset is added to the existing ResourceFieldRef.Resource:
ResourceFieldRef.Resource
- resource: limits.cpu
- A container’s CPU limit
- resource: requests.cpu
- A container’s CPU request
- resource: limits.memory
- A container’s memory limit
- resource: requests.memory
- A container’s memory request
- resource: limits.hugepages-*
- A container’s hugepages limit
- resource: requests.hugepages-*
- A container’s hugepages request
- resource: limits.ephemeral-storage
- A container’s ephemeral-storage limit
- resource: requests.ephemeral-storage
- A container’s ephemeral-storage request
- resource: assigned.cpuset (NEW)
- A container’s CPU desired assignments
The Volume manager gets the CPU state from CPU manager, and writes it to the Downward API volume file assigned.cpuset, which exposes the CPUSet to the container:
- If the container has exclusive CPUs assigned, the value exposes the exclusive cpuset (If preAssignments exist (scale-down is pending), this exposes the preAssignments; otherwise, it exposes the assignments).
- Otherwise, the value is empty ("").
Test Plan
[X] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Prerequisite testing updates
Unit tests
We plan on adding/modifying functions to the following files:
pkg/kubelet/cm/cpumanager/policy_options_test.gopkg/kubelet/cm/cpumanager/policy_static_test.gopkg/volume/downwardapi/downwardapi_test.gopkg/apis/core/validation/validation_test.go
Integration tests
Integration tests are not necessary because all cases are covered by unit and e2e tests.
e2e tests
These cases will be added in the existing e2e_node tests to verify that CPU Manager works with scale-delay-time static policy option and downward API exposing CPU states.
Prerequisites:
- Enable the following feature gates:
InPlacePodVerticalScalingExclusiveCPUsCPUManagerPolicyAlphaOptionsDownwardAPIAssignedResources
- Configure the CPU Manager policy option to use
scale-delay-time.
The following scenarios will be tested:
| No | Test | Description | Expected Result |
|---|---|---|---|
| 1 | Validate Scale-Down Delay | Initiate a scale-down request for a container and verify the operation timing against the configured scale-delay-time. | • Verify the pod is successfully patched for scale-down • The downward API volume exposes the new cpuset before it is applied to the container • Verify the pod scales down only after the scale-delay timer has expired • Verify the final resources allocated to the pod after the resize |
| 2 | Resource Allocation Blocking | Initiate a scale-down request for Pod 1 and attempt to allocate the CPU resources being released from Pod 1 to Pod 2 before the delay timer expires. | • Verify Pod 1’s scale-down request is pending and new cpuset has not yet been applied • Verify Pod 2 cannot allocate the CPUs held by Pod 1 until the delay timer has fully elapsed • Verify Pod 2 successfully resizes and claims the CPUs only after Pod 1’s delay period expires |
| 3 | Validate Scale-Up Before Timer Expiry | Initiate a scale-down request and, before the delay timer expires, send a scale-up request for the container CPU. | • Verify the pending scale-down request is cleared • The downward API volume reflects the current (scaled-up) cpuset • Verify the pod scales up as requested • Verify the resources allocated to the pod match the latest requested scale-up configuration |
| 4 | Validate Repeated Scale-Down Before Timer Expiry | Initiate a scale-down request and, before the delay timer expires, send another, different scale-down request for the container CPU. | • Verify the initial pending scale-down request is cleared • The downward API volume reflects the cpuset from the latest scale-down request • Verify the pod scales down following the latest request after the timer expires • Verify the resources allocated to the pod match the final scaled-down configuration |
| 5 | Validate Kubelet Restart Before Timer Expiry | Initiate a scale-down request and restart the Kubelet before the delay timer expires. | • Verify the scale-down is reprocessed after the kubelet restarts • Once the Kubelet restarts, verify the downward API volume exposes the new cpuset for the pending scale-down • Verify the Pod scales down after the scale-delay-time has elapsed |
| 6 | Feature gate DownwardAPIAssignedResources Rollback | Enable the feature gate and initiate a scale-down request. After scale-down actuation, disable the feature gate and perform another scale-down request. | • Verify CPU manager states are exposed through the Downward API when the feature gate is enabled • Verify the pod scales down after timer expiry • Restart kubelet and kube-apiserver with the feature gate disabled, verify existing pods with assigned.cpuset continue running without errors (field is silently ignored)• Perform pod downscaling again and verify the pod still scales down after timer expiry (but assigned.cpuset is not exposed) |
| 7 | Feature gate DownwardAPIAssignedResources Rollout | Disable the feature gate and initiate a scale-down request. After scale-down actuation, enable the feature gate and perform another scale-down request. | • Verify the pod scales down after timer expiry • Restart kubelet and kube-apiserver with the feature gate enabled, patch the pod to add downwardAPI and verify the pod comes in Running state without errors • Perform pod downscaling again and verify CPU manager states are exposed through the Downward API, while the pod scales down after timer expiry • Verify pods created with assigned.cpuset while feature gate was disabled are admitted (field silently ignored) and start receiving correct values after enabling the feature gate |
| 8 | Kubelet Version Rollback | Start with version v1.37 and initiate a scale-down request. Before scale-down completes (i.e. before timer expiry), downgrade kubelet to v1.36. | Before Downgrade: • Verify CPU manager states are exposed through the Downward API After Downgrade: • Patch the pod to remove downward-API, verify the pod comes in Running state and the pending scale-down request is rejected since scaling exclusive cpus are not supported in v1.36 |
| 9 | Kubelet Version Rollout | Start with version v1.36, deploy a pod with exclusive cpu, upgrade to v1.37, enable the DownwardAPIAssignedResources feature gate, and initiate a scale-down request. | • Verify the pod remains in Running state • Patch the pod to add downward-API and verify CPU manager states are exposed through the Downward API • Verify the pod scales down after the scale-delay timer expires |
Graduation Criteria
Alpha
For scale down delay feature
- Feature implemented behind the existing static policy feature flag
- Feature is behind feature gate flags:
CPUManagerPolicyAlphaOptionsInPlacePodVerticalScalingExclusiveCPUs
- The
scale-delay-timefunctionality is implemented. - Unit and e2e tests are completed with sufficient coverage.
For downward API exposing CPU states feature
- Feature implemented behind the
DownwardAPIAssignedResources. - Validation logic is in-place in kube-apiserver
- Kubelet has support for CPU manager exposure in the pod
- unit testing and e2e testing for downward API enhancement for CPU exposure.
Alpha2
For scale down delay feature
- No unresolved critical bugs.
- Bugs reported by users have been addressed
- A pod-level opt-out mechanism for the scale-down delay has been analyzed and designed. This allows pods that do not require the delay to skip it, while still allowing latency-sensitive pods to benefit from the guaranteed preparation time.
- Generalization of scale down delay to another type of resources has been analyzed.
- New metrics or events will be considered to improve the observability of this feature.
For downward API exposing CPU states feature
- Exposing Memory Manager information (e.g.,
assigned.memset) via the Downward API. - unit testing and e2e testing for downward API enhancement for memory exposure.
Beta
- No unresolved critical bugs.
- Bugs reported by users have been addressed
GA
- Allow time for feedback (6+ months).
- Make sure all risks have been addressed.
Upgrade / Downgrade Strategy
The scale-down delay functionality doesn’t store any information in kubelet checkpoints or any other persistent storage. This makes upgrades and downgrades seamless.
The new field assigned.cpuset is exposed behind the DownwardAPIAssignedResources feature gate. Field validation in kube-api-server depends on this gate. Kubelet handles file creation and updates based on pod spec (no dependency on feature gate).
The feature gate is Alpha and disabled by default. The documentation states: “Only enable this feature gate when all kubelets in the cluster support this feature.” The operator must upgrade all kubelets first, then enable the feature gate.
This documentation entry guarantees that, in both upgrades and downgrades, if one of the kubelet versions does not yet support this feature, the feature gate must remain disabled.
Version Skew Strategy
The scale-delay-time functionality is local to kubelet only so it is not affected by skewness problems between components.
Exposition of the field assigned.cpuset is behind feature gate DownwardAPIAssignedResources. The feature gate is Alpha and disabled by default. The documentation states: “Only enable this feature gate when all kubelets in the cluster support this feature.” The operator must upgrade all kubelets first, then enable the feature gate.
Considering the following scenarios:
Cluster has kubelets both: without the feature (1.36-) and with feature implemented (1.37+) (mixed versions): The operator does not enable the feature gate. Nobody can use
assigned.cpuset.All kubelets upgraded to versions having feature implemented (1.37+): The operator enables the feature gate on the API server and kubelets.
assigned.cpusetcan be mounted as DownwardAPI volume files by pods.Operator enables the feature gate while some kubelets still don’t have feature implemented (1.36-): This is an operator error. The feature gate is Alpha and disabled by default. The documentation states: “Only enable this feature gate when all kubelets in the cluster support this feature.” The operator must upgrade all kubelets first, then enable the feature gate.
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
This feature requires enabling the following feature gates
- Feature gate (also fill in values in
kep.yaml)- Feature gate name:
InPlacePodVerticalScalingExclusiveCPUs - Feature gate name:
CPUManagerPolicyAlphaOptions - Feature gate name:
DownwardAPIAssignedResources - Requires
--cpu-manager-policykubelet configuration set tostatic - Requires
scale-delay-timekubelet configuration.
- Feature gate name:
The following table shows the effect of each feature gate combination:
| CPUManager PolicyAlpha Options | InPlacePod VerticalScaling ExclusiveCPUs | DownwardAPI Assigned Resources | Effect |
|---|---|---|---|
| ✗ | ✗ | ✗ | Legacy version: no scaling of exclusive CPUs, no minimum delay, no exposure of cpuset in downwardAPI |
| ✗ | ✗ | ✓ | No scaling of exclusive CPUs, no minimum delay, desired cpuset exposed in downwardAPI |
| ✗ | ✓ | ✗ | Scaling of exclusive CPUs, no minimum delay, no exposure of cpuset in downwardAPI |
| ✗ | ✓ | ✓ | Scaling of exclusive CPUs, no minimum delay, desired cpuset exposed in downwardAPI |
| ✓ | ✗ | ✗ | No scaling of exclusive CPUs, scale-delay-time > 0 rejected (warning emitted), no exposure of cpuset in downwardAPI |
| ✓ | ✗ | ✓ | No scaling of exclusive CPUs, scale-delay-time > 0 rejected (warning emitted), desired cpuset exposed in downwardAPI |
| ✓ | ✓ | ✗ | Scaling of exclusive CPUs, delay configurable and working, no exposure of cpuset in downwardAPI |
| ✓ | ✓ | ✓ | Full feature: scaling of exclusive CPUs, delay configurable and working, desired cpusets exposed in downwardAPI |
Does enabling the feature change any default behavior?
Enabling scale-delay-time, it will ensure a minimum delay before the cpuset is applied when the pod scales down.
Enabling DownwardAPIAssignedResources, it will expose the CPU states via downward API. Feature gate DownwardAPIAssignedResources only gates the kube-apiserver validation.
The feature gate behavior is as follows:
- Feature gate disabled (apiserver implements the feature but gate is off): The
assigned.cpusetfield in pod specs is silently ignored during validation. This allows pods withassigned.cpusetto be admitted, but the field has no effect. This enables seamless rollout/rollback scenarios where pods can be created with the field before enabling the feature gate. - Feature gate enabled: The
assigned.cpusetfield is validated and accepted in pod specs. - Feature not implemented (older apiserver version): The apiserver does not recognize the
assigned.cpusetfield and will reject pods using it with a validation error: “unsupported container resource: assigned.cpuset”. Operators must upgrade all apiservers before using this field in pod specs.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Yes.
Disabling scale-delay-time does not have any consequences.
Disabling DownwardAPIAssignedResources on kube-apiserver causes the assigned.cpuset field to be silently ignored during validation. Existing pods with assigned.cpuset continue to run without interruption. However, the field will have no effect until the feature gate is re-enabled. Operators should be aware that workloads relying on assigned.cpuset exposure will no longer receive updated CPU assignments via the Downward API while the feature gate is disabled.
What happens if we reenable the feature if it was previously rolled back?
The cpuset will be applied with a minimum delay again based on the configuration of scale-delay-time.
The assigned.cpuset will contain proper values.
Are there any tests for feature enablement/disablement?
Provided E2E tests cover rollout and rollback cases.
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
The feature gate DownwardAPIAssignedResources is Alpha and is disabled by default.
The upgrade and rollback of kubelet and kube-apiserver components can be conducted with feature gate enabled only if it does not break the rule written in documentation: “Only enable this feature gate when all kubelets in the cluster support this feature.”. See above sections for Upgrade / Downgrade Strategy and Version Skew Strategy
This feature ensures a minimum delay before applying the new cpuset during scale-down. A rollout or rollback can fail if the kubelet configuration is invalid (e.g., an invalid scale-delay-time value).
However, since this feature only affects the timing of cpuset changes and not the allocation itself, a failure does not impact already running workloads — their current cpuset remains in effect.
What specific metrics should inform a rollback?
N/A
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
Local Testing Plan:
Test DownwardAPIAssignedResources feature upgrade and rollback
Note: The DownwardAPIAssignedResources feature gate is configured on kube-apiserver (not kubelet). The kubelet always supports reading assigned.cpuset from pod specs and exposing CPU manager state via Downward API volumes. The feature gate only controls API server validation of the assigned.cpuset field.
- Deploy cluster with
DownwardAPIAssignedResourcesfeature gate disabled on kube-apiserver. - Create a pod with
assigned.cpusetdownward API volume.- Verify the pod is admitted (field is silently ignored by apiserver).
- Verify kubelet creates the downward API volume file (empty or with current cpuset).
- Initiate a pod downscaling request.
- Verify the pod scales down after timer expiry.
- Verify the downward API volume file is updated with the new cpuset by kubelet.
- Enable the feature gate on kube-apiserver (restart apiserver) and initiate another pod downscaling request.
- Verify the pod remains in
Runningstate without errors. - Verify CPU manager states are exposed through the Downward API.
- Verify new pods with
assigned.cpusetare accepted by apiserver.
- Verify the pod remains in
- Disable the feature gate on kube-apiserver again and initiate another pod downscaling request.
- Verify existing pods with
assigned.cpusetcontinue running without errors (field is silently ignored). - Verify the pod still scales down after timer expiry.
- Verify kubelet continues to update the downward API volume file (kubelet behavior is independent of the feature gate).
- Verify existing pods with
- Finally, re-enable the feature gate on kube-apiserver and initiate another pod downscaling request.
- Verify the pod remains in
Runningstate without errors. - Verify CPU manager states are exposed through the Downward API.
- Verify the pod remains in
Test scale-delay-time feature upgrade and rollback
- Deploy kubelet v1.36 with
scale-delay-timeas 0.- Do not verify the pod scale-down delay, as exclusive CPU resize is not supported in this version.
- Upgrade kubelet from v1.36 to v1.37, configure
scale-delay-timeas Xs (e.g. 5s), and initiate a pod scale up first and request scale-down.- Verify the pod remains in
Runningstate without errors. - Verify the pod scales down delay is greater than 5s.
- Verify the pod remains in
- Downgrade kubelet from v1.37 to v1.36, clear the
scale-delay-timeconfiguration.- Verify the pod remains in
Runningstate without errors. - Do not verify the pod scale-down delay, as exclusive CPU resize is not supported in this version.
- Verify the pod remains in
- Upgrade kubelet back to v1.37, configure
scale-delay-timeagain, and initiate a pod scale up first and request scale-down.- Verify the pod remains in
Runningstate without errors. - Verify the pod scales down delay is greater than 5s.
- Verify the pod remains in
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
N/A
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
Check the downward API volume in the pod. Files /etc/podinfo/cpuset should be present respectively for CPU info.
The kubelet configuration printed in kubelet’s logs shows non-zero scale-delay-time.
How can someone using this feature know that it is working for their instance?
Check whether there is a downward API volume of cpuset in the pod.
After scaling containers with exclusive CPUs assigned down there should be a temporary (for at least scale-delay-time) visible discrepancy between the /etc/podinfo/cpuset file (which already contains the new values) and the current cpuset settings in cgroups (still containing old CPUset).
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
- The downward API volume must reflect the new cpuset before the cpuset is applied, ensuring the workload has the full delay window to prepare.
- After at least
scale-delay-timehas elapsed, the new cpuset is applied to the container at the next cpuset actuation time. - Scale-up operations are not delayed by this feature and follow the existing behavior.
- The cpuset values exposed via the downward API must always be accurate:
assigned.cpusetmust reflect the allocated cpuset (preAssignments if scale-down is pending, otherwise assignments).
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
Time from the CPU manager determining the new cpuset to the downward API volume being updated. This indicates whether the workload receives timely notification of the upcoming change.
Time from the
scale-delay-timeexpiring to the new cpuset being applied to the container. This indicates whether the cpuset change is applied promptly after the delay.Number of scale-down operations where the downward API volume was updated after the cpuset was applied (should be zero). This indicates whether the critical guarantee — that the workload is notified before the change — is being upheld.
Are there any missing metrics that would be useful to have to improve observability of this feature?
These can be measured via kubelet metrics and events. For example, a scale_delay_timer_fired event and a cpuset_applied timestamp allow computing the delay between notification and application.
These metrics won’t be implemented for alpha stage, but will be considered later for alpha2/beta
Dependencies
Does this feature depend on any specific services running in the cluster?
No
Scalability
Will enabling / using this feature result in any new API calls?
No
Will enabling / using this feature result in introducing new API types?
A new field assigned.cpuset is added to the existing ResourceFieldRef.Resource:
- resource: limits.cpu
- A container’s CPU limit
- resource: requests.cpu
- A container’s CPU request
- resource: limits.memory
- A container’s memory limit
- resource: requests.memory
- A container’s memory request
- resource: limits.hugepages-*
- A container’s hugepages limit
- resource: requests.hugepages-*
- A container’s hugepages request
- resource: limits.ephemeral-storage
- A container’s ephemeral-storage limit
- resource: requests.ephemeral-storage
- A container’s ephemeral-storage request
- resource: assigned.cpuset (NEW)
- A container’s CPU desired assignments
Will enabling / using this feature result in any new calls to the cloud provider?
No
Will enabling / using this feature result in increasing size or count of the existing API objects?
No
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
No
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
N/A
What are other known failure modes?
N/A
What steps should be taken if SLOs are not being met to determine the problem?
N/A
Implementation History
N/A
Drawbacks
Alternatives
This section summarizes the alternatives considered during the design phase. These discussions originated in the context of KEP-5554 (which enables in-place scaling of pods with exclusive CPUs) and continued during the design of this KEP (which adds configurable scale-down delay and Downward API exposure).
The following alternatives were discussed in SIG Node meetings and in the KEP review process. For more details, see:
- SIG Node Meeting Recording (March 2025) discussing static CPU policy support
- SIG Node Meeting Minutes (March 11, 2025)
- KEP Review Document (Google Doc)
- GitHub Discussion: kubernetes/kubernetes#131309
The following alternatives were considered:
1. LIFO (Last-In, First-Out) CPU Release
- Description: Track the order in which CPUs were allocated and release them in reverse order during scale-down.
- Why Rejected: This approach was discussed as a potential implementation detail for determining which CPUs to remove. However, KEP-5554 established the principle of preserving the Original CPUSet allocated during pod creation. The “never-remove-promised-CPUs” requirement means that the initial CPUs must remain in the actuated set throughout the pod’s lifetime. LIFO would add tracking complexity without providing additional guarantees. This was rejected during SIG Node meetings as an unnecessary complication.
2. CPU Release Based on Real-Time Usage
- Description: Monitor CPU utilization inside the container and release the least utilized or idle cores during scale-down.
- Why Rejected: This approach was briefly mentioned as a possibility but was rejected because:
- It deviates from Kubernetes’ deterministic resource management model.
- CPU usage fluctuates rapidly, making it unreliable for infrastructure decisions.
- It risks performance degradation for workloads that depend on specific cache topologies (NUMA, L3 caches).
3. Immediate Actuation (No Delay)
- Description: Apply the new cpuset immediately when the scale-down request is processed, without any delay.
- Why Rejected: This is the current behavior without this KEP. Immediate actuation does not give workloads time to prepare for CPU removal. Latency-sensitive applications (e.g., DPDK workloads) may experience performance degradation because they cannot migrate tasks away from CPUs being removed. This KEP addresses this gap by introducing a configurable delay window.
4. Handshake-Based Synchronization
- Description: Require the workload to send a signal to kubelet when it is ready for the cpuset change, rather than using a time-based delay.
- Why Rejected: This approach would create a dependency between kubelet and workload state, which violates Kubernetes’ design principle of keeping kubelet independent from application behavior. A workload could potentially block the scaling operation indefinitely. The time-based delay provides a guaranteed preparation window without introducing this coupling.
5. Node Declared Features as Opt-Out Mechanism
- Description: Use Node Declared Features to allow pods to opt out of the scale-down delay at the pod level.
- Why Rejected: Node Declared Features are intended to be temporary and tied to feature gates, to be removed at GA+3. They are not suitable as a permanent opt-out mechanism. Alternative approaches (such as pod annotations or node taints) will be evaluated for Beta graduation.
6. Pod-Level Grace Period (Opt-In/Opt-Out Mechanism)
Description: Introduce a
scaleDownGracePeriodSecondsfield at the Pod spec level (analogous toterminationGracePeriodSeconds). This approach, proposed by @natasha41575, would allow application developers to define the grace period on an opt-in, per-pod basis, completely decoupled from any specific resource manager (CPU Manager, Memory Manager, DRA, etc.).Why Deferred to Alpha2/Beta: This approach requires changes to the Pod API spec and broader SIG Node consensus. The current node-level
scale-delay-timeconfiguration was chosen for Alpha as it allows faster iteration and feedback collection without API changes. The pod-level approach remains a strong candidate for a more granular opt-in/opt-out mechanism in Beta.
7. Hook-Based Synchronization Approach
Description: Instead of using a time-based delay, implement a hook-based mechanism where the workload can register a pre-scale-down hook that the kubelet invokes before applying the cpuset change. The kubelet would wait for the hook to complete (or timeout) before proceeding with the actual cpuset actuation. This approach was suggested by @ffromani during the KEP review process as an alternative to the timer-based delay.
Future Consideration: The hook-based approach remains a candidate for Alpha2/Beta as one of the mechanisms to provide opt-in/opt-out capability at the pod or container level.
8. Generalizing Scale-Down Delay to Other Resource Types
Description: Extend the scale-down delay mechanism beyond exclusive CPUs to other resource types, such as memory, hugepages, ephemeral-storage, or dynamically allocated resources via the Dynamic Resource Allocation (DRA) framework. This approach would provide a unified grace period mechanism for various resize operations across the kubelet.
Key Considerations:
Memory Resize: When a container’s memory limit is scaled down, the application could receive a notification via the Downward API and the kubelet would wait for a configured grace period before enforcing the new limit. This gives the application time to reduce its memory usage (e.g., by releasing caches, shrinking buffers, or triggering garbage collection) before the hard limit is applied. This use case was explicitly mentioned in discussions around KEP-6050 for memory-backed emptyDir downsizing scenarios.
DRA Resources: For dynamically allocated resources (e.g., GPUs, FPGAs, or other accelerators managed via DRA), a scale-down grace period would allow applications to gracefully release or migrate workloads from resources being removed. This is particularly relevant as DRA evolves to support more dynamic allocation patterns.
Why Deferred to Alpha2/Beta: This generalization was not included in the initial Alpha implementation for the following reasons:
Scope Focus: The initial implementation focuses exclusively on exclusive CPUs, which is the only resource type currently supporting in-place vertical scaling with guaranteed QoS pods (via KEP-5554). Non-exclusive resources like general CPU and memory requests are not distinguishable at the container level for the purposes of selective resource removal.
Implementation Complexity: Extending the delay mechanism to other resource types requires coordination across multiple resource managers (Memory Manager, DRA framework, etc.) and potentially new APIs. Each resource type has different semantics for what “graceful release” means.
Limited Use Cases: As of today, exclusive CPUs are the primary use case requiring delayed scale-down. Not all of other resource types have in-place scaling implementations that would benefit from this feature.
Need for User Feedback: The SIG Node community agreed to collect user feedback from the Alpha1 implementation of the CPU-focused delay mechanism before designing a more generalized solution. This feedback will inform whether and how to extend the feature to other resource types.
Note: The scale-down delay approach was selected during the KEP review process (discussed in SIG Node meetings and document reviews) as it provides a simple, deterministic guarantee without requiring workload-kubelet synchronization. Concerns about timer-based approaches introducing race conditions are unfounded: both the delay verification and cpuset actuation occur sequentially within the CPUManager’s reconcile loop, ensuring deterministic behavior.