KEP-575: Defaulting for Custom Resources
Defaulting for Custom Resources
Table of Contents
Summary
Defaulting is a fundamental step in the processing of API objects in the request pipeline of the kube-apiserver. Defaulting happens during deserialization, i.e. after decoding of a versioned object, but before conversion to a hub type.
Defaulting is implemented for most native Kubernetes API types and plays a crucial role for API compatibility when adding new fields. CustomResources do not support this natively.
Mutating admission webhooks can be used to partially replicate defaulting for incoming request payloads. But mutating admission webhooks do not run when reading from etcd.
This KEP is about adding support for specifying default values for fields via OpenAPI v3 validation schemas in the CRD manifest. OpenAPI v3 has native support for a default field with arbitrary JSON values, for example:
properties:
foo:
type: string
default: "abc"
This KEP proposes to apply these default values during deserialization, in the same way as native resources do. We assume structural schemas as defined in KEP Vanilla OpenAPI Subset: Structural Schema .
This feature starts behind a feature gate CustomResourceDefaulting, disabled by default as alpha in 1.15.
It will graduate to GA in apiextensions.k8s.io/v1 for 1.16. Defaults can only be set on creation via the v1 API.
Motivation
- By far most native Golang based resources implement defaulting. CRDs do not allow that, leading to unnatural, not Kubernetes-like APIs. This is bad for the ecosystem.
- Mutating Admission Webhooks can be used for defaulting, but:
- they are not adequate as it is not possible to set default values of newly added fields on GET because admission is not run in the storage layer when reading from etcd.
- webhooks are complex, both from the development/maintenance point of view and due to their non-trivial operational overhead. This makes them a no-go for many “not so ambitiously, professionally developed CRDs”, e.g. in in-house enterprise environments.
- Structural schemas as defined in KEP Vanilla OpenAPI Subset: Structural Schema make defaulting a low hanging fruit.
Goals
- add CustomResource defaulting at the correct position in the request pipeline
- allow definition of defaults via the OpenAPI v3
defaultfield.
Non-Goals
- allow non-constant defaults: native Golang code can of course set defaults which depends on other fields of a JSON object. This is out of scope here and would need some kind of defaulting webhook.
- native-type declarative defaulting: this KEP is about CRDs. Though it might be desirable to support the same
// +default=<some-json-value>tag and a mechanism ink8s.io/apiserverto evaluate defaults in native, generic registries, this is out-of-scope of the KEP though.
Proposal
We assume the CRD has structural schemas (as defined in KEP Vanilla OpenAPI Subset: Structural Schema ).
We propose to
- derive the value-validation-less variant of the structural schema (trivial by definition of structural schema) and
- recursively follow the given CustomResource instance and the structural schema, applying specified defaults where an object field is undefined (
if _, ok := obj[field]; !ok=> default).
This means that we do not default
- explicit JSON
nullvalues (it might be rejected during validation depending on thenullablesetting) - nor empty lists or maps
- nor zero numbers/integers or empty strings (
omitemptyduring marshalling indirectly controls whether these values are defaulted or not)
This corresponds to the official OpenAPI v3 default semantics
.
We do defaulting in the serializer by passing a real defaulter to versioningserializer.NewCodec
such that defaulting is done natively just after the binary payload has been unmarshalled into an map[string]interface{} and pruning of KEP: Pruning for CustomResources
was done.
Like for native resources, we do defaulting
- during request payload deserialization
- after mutating webhook admission
- during read from storage.
Note: like for native resources, we do not default after webhook conversions. Hence, webhook conversions should be complete in the sense that they return defaulted objects in order for the API user to see defaulted objects. Technically we could do additional defaulting, but to match native resources, we do not.
Compare the yellow boxes in the following figure:
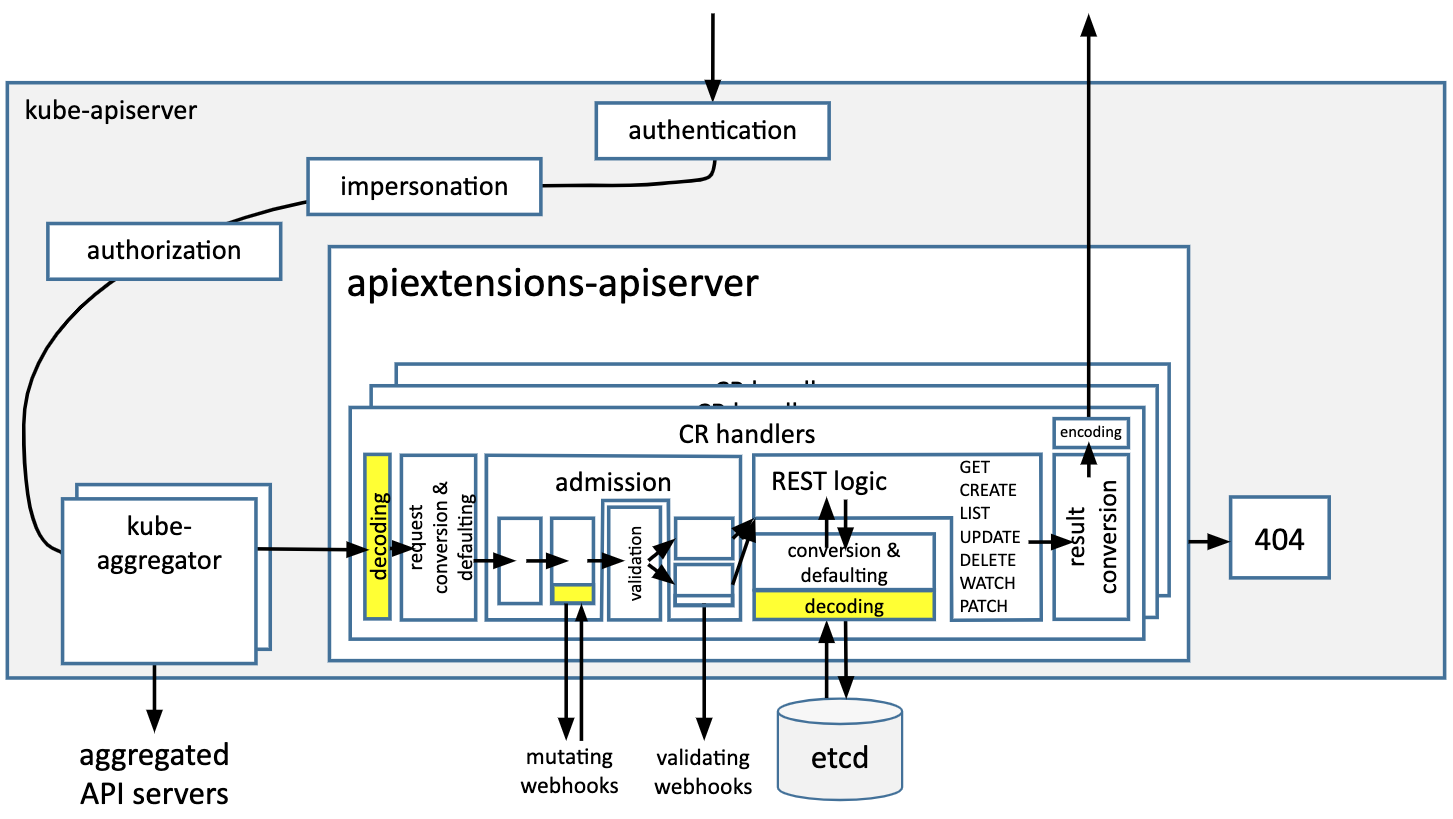
We rely on the validation steps in the request pipeline to verify that the default value validates value validation. We will check the types in default values using the structural schema during CRD creation and update though. We will also reject defaults which contain values which will be pruned.
Defaulting happens top-down, i.e. we apply defaults for an object first, then dive into the fields (including, the new one).
The default field in the CRD types is considered alpha quality. We will add a CustomResourceDefaulting feature gate. Values for default will be rejected if the gate is not enabled and there have not been default values set before (ratcheting validation).
Kubebuilder’s crd-gen
can make use of this feature by adding another tag, e.g. // +default=<arbitrary-json-value>. Defaults are arbitrary JSON values, which must also validate (types are checked during CRD creation and update, value validation is checked for requests, but not for etcd reads) and are not subject to pruning (defaulting happens after pruning).
Validation
CRDs with defaults can only be created via apiextensions.k8s.io/v1. They are rejected for v1beta1 on creation (updates keep working).
Default values must be pruned, i.e. must not have fields which are not specified by the given structural schema (including support for x-kubernetes-preserve-unknown-fields to exclude nodes from being pruned), with the exception of
- defaults inside of
.metadataof an embedded resource (x-kubernetes-embedded-resource: true) - defaults which span
.metadataof an embedded resource.
Values conflicting with this are rejected when creating or updating a CRD.
Defaults are validated against the schema (including embedded ObjectMeta validation).
Defaults inside .metadata at the root are not allowed.
Behaviour of Embedded Resource ObjectMeta Defaults
While defaults for ObjectMeta fields are not checked for being pruned during CRD creation and update (previous section), we do pruning of default values on CR storage creation. That way no user-provided default values are lost, but the pruning step during storage creation ensures that no unknown or invalid defaulted values are persisted during CR creation or update.
Examples
default in the undefined case
type: object properties: foo: type: string default: "abc"Then
{}is defaulted to:
{ "foo": "abc" }no defaulting
type: object properties: foo: type: string default: "abc"Then
{ "foo": "def" }is defaulted to:
{ "foo": "def" }array default in the undefined case
type: object properties: foo: type: array items: type: integer default: [1]Then
{}is defaulted to:
{ "foo": [1] }In contrast
{ "foo": null }is defaulting to
{ "foo": null }and then rejected by validation because
foohas nonullable: true.Similarly, empty lists stay empty lists:
{ "foo": [] }is defaulted to:
{ "foo": [] }top-down defaulting
type: object properties: foo: type: object properties: a: type: string default: "abc" b: type: string default: {"b":"def"}Then
{}is defaulted to:
{ "foo": {"a":"abc", "b":"def"} }
References
- Old pruning implementation PR https://github.com/kubernetes/kubernetes/pull/64558 , to be adapted. With structural schemas it will become much simpler.
- OpenAPI v3 specification
- JSON Schema
Test Plan
blockers for alpha:
- we add unit tests for the general defaulting algorithm
- we add apiextensions-apiserver integration tests to
- verify that CRDs with default, but without structural schemas are rejected by validation.
- verify that CRDs without defaults keep working (probably nothing new needed)
- verify that CRDs with defaults are defaulted if the feature gate is enabled:
- during request payload deserialization
- during mutating webhook admission
- during read from storage
- verify with feature gate closed that CRDs with defaults are rejected on create and on updating for the first default value, but accepted if defaults existed before (ratcheting validation).
blockers for beta:
add tests for default value validation:
- CRD schema with defaults containing unknown fields inside metadata
- new CRD (allowed)
- updated CRD where existing CRD did contain the unknown field (allowed)
- updated CRD where existing CRD did not contain the unknown field (allowed)
- building CR storage from persisted CRD discards unknown fields
- CRD schema with defaults containing schema-invalid fields inside metadata (e.g. finalizers: 1)
- new CRD (forbidden)
- updated CRD where existing CRD did contain the invalid field (allowed)
- updated CRD where existing CRD did not contain the invalid field (forbidden)
- building CR storage from persisted CRD discards schema invalid fields from defaults.
- CRD schema with defaults containing unknown fields outside of metadata is
- accepted if they fall under the scope of
x-kubernetes-preserve-unknown-fields: true - rejected otherwise.
- accepted if they fall under the scope of
- CRD schema with defaults containing unknown fields inside metadata
we are happy with the API and its behaviour
blockers for GA:
- add tests for default value validation:
- CRD schema with defaults is rejected on creation via the
v1beta1endpoints, but updates viav1beta1are still possible.
- CRD schema with defaults is rejected on creation via the
- we verified that performance of defaulting is adequate and not considerably reducing throughput. As a rule of thumb, we expect defaulting to be considerably faster than a deep copy.
Graduation Criteria
- the test plan is fully implemented for the respective quality level
Upgrade / Downgrade Strategy
- defaults cannot be set in 1.14 CRDs.
- CRDs created in 1.15 will keep defaults when downgrading to 1.14 (because we have them in our
v1beta1types already). They won’t be effective and the CRD will not validate anymore. This is acceptable for an alpha feature. - CRDs created in 1.15 with the feature gate enabled will keep working the same way when upgrading to 1.16, or conversely during downgrade from 1.16 to 1.15 as we do ratcheting validation.
- Creation of CRDs with defaults via
v1beta1API will be disabled, even if the feature gate is explicitly enabled.
Version Skew Strategy
- kubectl is not aware of defaulting in any relevant way.
Alternatives considered
we considered following the behaviour of native resources regarding
nullvalues and empty lists/maps and zero values for string, number and integer, i.e. this semantics:For atomic types:
if v, ok := obj[fld]; !ok=> defaultelse if !nullable && v == nil=> default
and for
arraytype in the schema one of these:if v, ok := obj[fld]; !ok=> defaultelse if !nullable && v == nil=> defaultelse if array, ok := v.([]interface{}); !ok=> return deserialization errorelse if !nullable && len(array) == 0=> default
and for
objecttype in the schema:if v, ok := obj[fld]; !ok=> defaultelse if !nullable && v == nil=> defaultelse if object, ok := v.(map[string]interface{}); !ok=> return deserialization errorelse if !nullable && len(object) == 0=> default.
We decided against that because
the native-type defaulting semantics inherited
- the Golang unmarshalling behaviour which identifies undefined and
nullvalues (if one does not use additional pointer types to fight against it) - the Protobuf inability to distinguish undefined and empty lists and maps.
For CRDs we can distinguish undefined and
null. We control Protobuf for CRDs, when we add support in the future, and hence can use some kind of value packaging to represent undefined lists/maps and other values faithfully.This way we avoid cargo culting an accidental API convention.
- the Golang unmarshalling behaviour which identifies undefined and
the semantics of “default if undefined” is much simpler than any variant with (potentially conditional) defaulting of
nulland empty slices/maps.it conflicts with official OpenAPI v3 semantics for
defaultIf we need more native-type like defaulting in addition, we can add an alternative
x-kubernetes-legacy-default: <arbitrary-json>which is mutual exclusive with
default. Using another field name avoids this conflict, but gives us the legacy behaviour of defaultingnulland empty lists/maps.This might potentially be relevant when embedding upstream Kubernetes types into CRDs.