KEP-4781: Restarting kubelet does not change pod status
KEP-4781: Restarting kubelet does not change pod status
- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- Infrastructure Needed (Optional)
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
When a kubelet restarts, for whatever reason, it usually will not have any impact on currently running pods. Today, however, a kubelet restart causes all pods on that node to have their Started and Ready statuses set to False (by the kubelet), which can disrupt services that were actually functioning normally. This KEP proposes improving Pod readiness management in the kubelet to ensure that the status of Pods is not unilaterally modified, and is instead preserved during kubelet restarts.
Motivation
Ensuring high availability and minimizing service disruptions are critical considerations for Kubernetes clusters. When the kubelet restarts, it resets the Start and Ready states of all containers to False by default. This means that any successful probe statuses that were previously established are lost upon the restart. As a result, services may be inaccurately flagged as unavailable, despite having been operational prior to the kubelet’s restart. This reset can lead to erroneous perceptions of service health and negatively impact the overall performance of the cluster, potentially triggering unnecessary alerts or load balancing changes.
Some users have reported that this issue has been causing them trouble. Here are some links to historical discussions related to this problem: https://github.com/kubernetes/kubernetes/issues/100277 , https://github.com/kubernetes/kubernetes/issues/100277#issuecomment-1179412974 , https://github.com/kubernetes/kubernetes/issues/102367
It’s essential to implement strategies to ensure that the service states accurately reflect their operational status, even during kubelet interruptions.
Goals
- Ensure consistency in container start and ready states across kubelet restarts.
- Minimize unnecessary service disruptions caused by temporary ready state changes.
Non-Goals
- If the kubelet fails to renew its lease beyond the nodeMonitorGracePeriod due to an excessively long restart interval, the Ready status of the containers in the pods on the node will be set to false. In this situation, we should not manually set the Ready status back to true. Instead, it should remain false, waiting for the probe to execute again and restore it.
- Modify the fundamental logic of how readiness probes work.
Proposal
User Stories (Optional)
Story 1
As a user of Kubernetes, I want the container’s Ready state to remain consistent across kubelet restarts so that my services do not experience unnecessary downtime. However, currently, a kubelet restart causes a brief “Not Ready” storm, where the state of all Pods is set to Not Ready, impacting the availability of my services.
Risks and Mitigations
Inconsistency with other Kubernetes components
If other parts of Kubernetes (e.g., the API server, controllers) expect certain behavior regarding container readiness states, these changes might cause inconsistencies.
Delayed Health Check Updates
By preserving the old state without immediate health checks, there is a delay in recognizing containers that have become unhealthy during or after kubelet’s downtime. Services relying on Pod readiness for service discovery might continue directing traffic to Pods with containers that are no longer healthy but are still reported as Ready.
Design Details
We will be adding a deprecated feature gate: ChangeContainerStatusOnKubeletRestart. This feature gate will be disabled by default. When disabled, the Kubelet will not change container statuses after a restart. Users can enable the ChangeContainerStatusOnKubeletRestart feature gate to restore the behavior where the Kubelet changes container statuses after a restart.
Regarding this feature gate, the changes we will make in the kubelet codebase are as follows:
We will retrieve the
Startedfield from the container status in the Pod via the API server. After the Kubelet restarts, during the first entry intoSyncPod, we will propagate this value to the newly generated container status.We ensure that if the
Startedfield in the container status is true, the container is considered started (since the startupProbe only runs during container startup and will not execute again once completed).If the Kubelet restart occurs within the
nodeMonitorGracePeriodand the Pod’s Ready condition is set to false, we will set the container’s ready status to false. It will remain in this state until subsequent probes reset it to true.We will modify the logic in the
doProbefunction. When it detects a container that was already running before the Kubelet restarted (for the first time after restart), it will skip marking an initial Failure status. This allows the proberesultto retain the defaultSuccessstatus. If the container’s state changes during the Kubelet restart period and causes the probe to return an abnormal result, the status will be updated to a non-Success state in the next probe cycle. Subsequent syncPod operations will then set the container’s Ready status to false.Additionally, this KEP ensures that if a Pod’s Ready condition is set to
falsebefore kubelet restart, the kubelet will not transition the Pod to aReadystate until the readiness probe explicitly marks it as such. This prevents Pods that were previously marked asNotReadyfrom being incorrectly reported asReadyafter a kubelet restart, ensuring consistency and avoiding potential service disruptions.
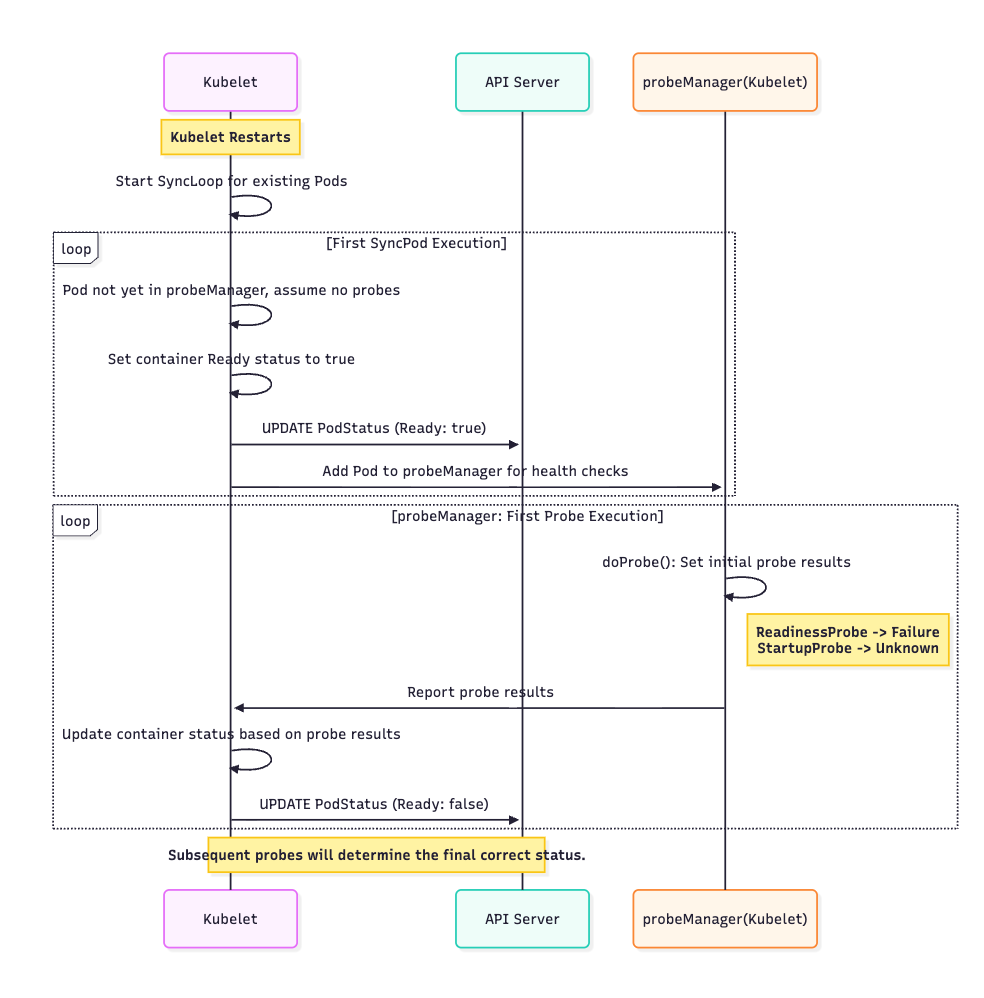
Before the Changes: If kubelet restarts, the pod status transition process is as follows:
Kubelet uses
SyncPodto reconcile the pod state. During the first execution ofSyncPod, the pod has not yet been added to theprobeManager. At this point,SyncPodassumes the pod has no probes configured (note: if it is a newly created pod, the first execution ofSyncPoddoes not go through this step). Therefore, it sets the container’sReadystatus to true and updates it to the APIserver.After updating the container status,
SyncPodadds the pod to theprobeManager. The pod then begins executing probes.During the first execution of
doProbe(It will skip theinitialDelaySecondsperiod because the container’s startup time exceeds theinitialDelaySecondsperiod),doProbesets the result of all probes to theirinitialValue. TheinitialValueforreadinessProbeisFailure, and forstartupProbeit isUnknown. Based on the probe results, it updates theStartedandReadyfields of the container status in the APIserver to false.
The sequence diagram for this process is as follows:
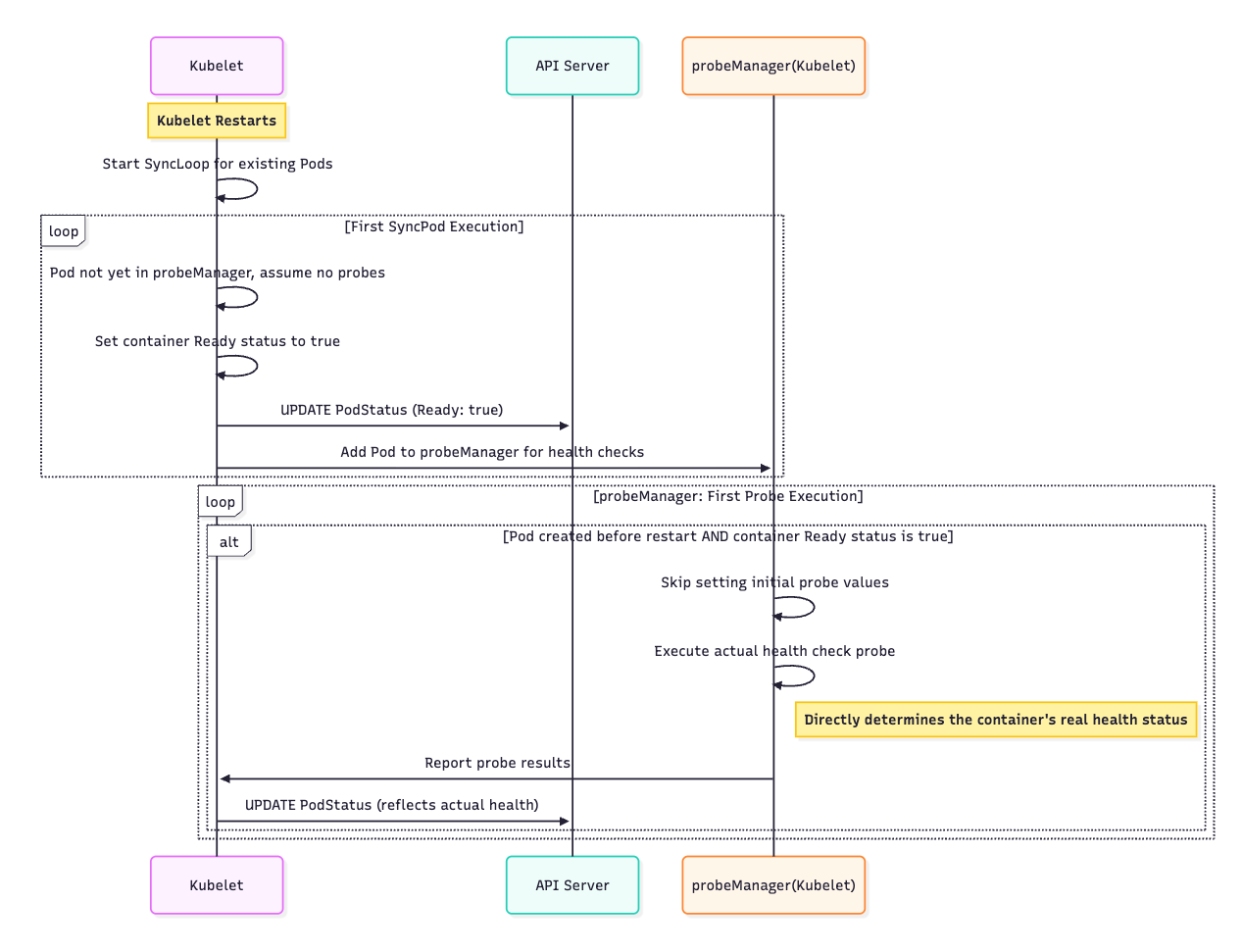
After the Changes:
Scenario 1:
After the changes, if kubelet restarts, the pod status transition process is as follows:
- (The first two steps are the same as before the changes and are omitted here.)
- During the first execution of
doProbe(It will skip theinitialDelaySecondsperiod because the container’s startup time exceeds theinitialDelaySecondsperiod), If the pod’s creation time precedes the kubelet’s start time by more than 10 seconds (a tolerance for clock skew), and the container’s readiness state is true.doProbeskips the step of setting all probe results to theirinitialValueand proceeds with subsequent probe steps. This ensures that kubelet can immediately probe whether the container is still functioning properly after restarting, avoiding a situation where the container becomes unhealthy during kubelet restart but kubelet fails to update the container’sReadyfields to false in a timely manner.
The sequence diagram for this process is as follows:
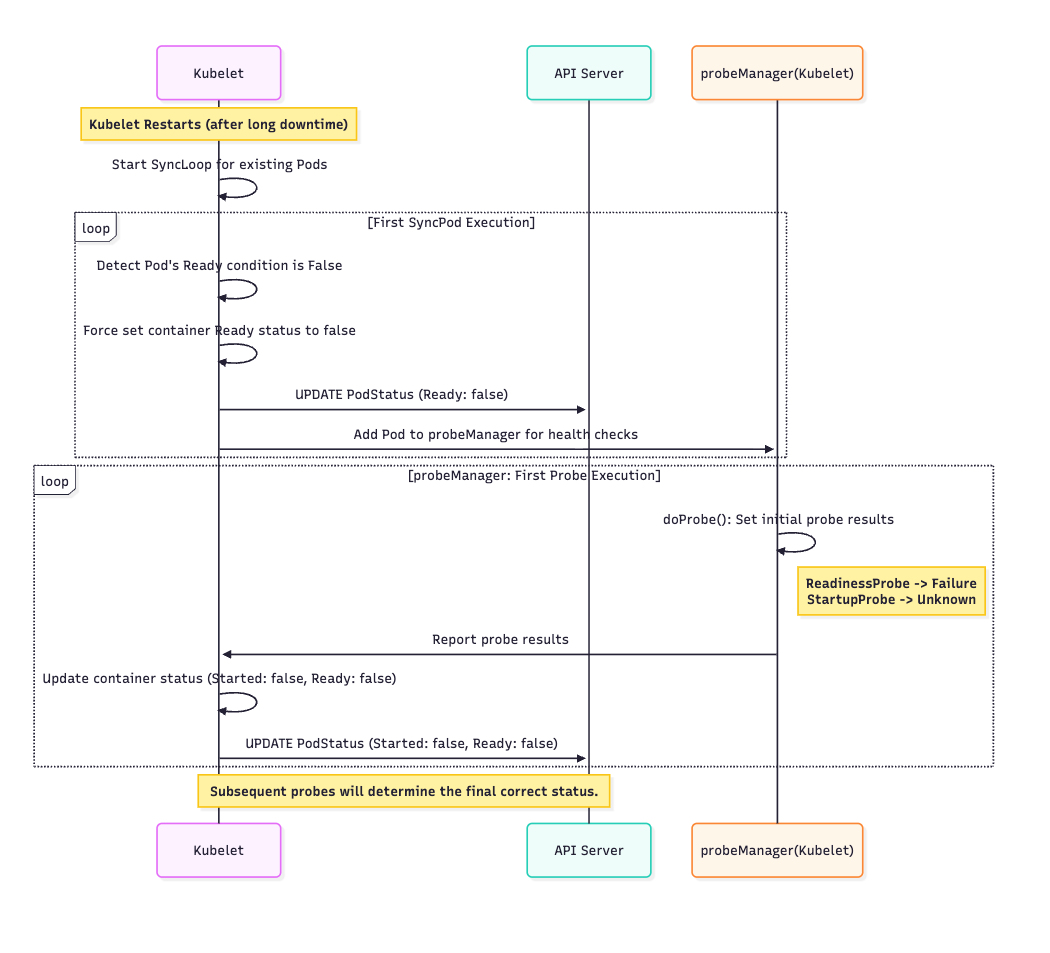
Scenario 2:
After the change, if the kubelet is restarted for a sufficiently long time (exceeding the nodeMonitorGracePeriod), causing the pod’s Ready condition to be set to false:
KubeletusesSyncPodto reconcile the pod state. During the first execution ofSyncPod, if kubelet detects that the pod’sReady conditionis false, it directly sets the container’sReadyfields tofalseand updates it to the APIserver.After updating the container status,
SyncPodadds the pod to theprobeManager. The pod then begins executing probes.The logic here is the same as in Scenario 1. Since the container’s
Readyfields is false, doProbe sets the result of all probes to theirinitialValueand updates theStartedandReadyfields of the container status in the API server to false based on the probe results. Subsequent executions ofdoProbewill then transition the pod status to the desired state.
- Special Case: If a Pod’s
Readystatus has been set to false before the kubelet restarts, the kubelet will ensure that the Pod remains in theNotReadystate until the readiness probe explicitly marks it as Ready. This behavior is consistent with when a Pod’sReadystatus is set to false during a kubelet restart.
The sequence diagram for this process is as follows:
Test Plan
[ ] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Prerequisite testing updates
Unit tests
pkg/kubelet/prober:2025-08-25-77.4%k8s.io/kubernetes/pkg/kubelet:2025-08-25-71.2%
Integration tests
:
e2e tests
- Add an e2e test case to verify that restarting kubelet does not affect pod status when the pod has no probes.
- Add an e2e test case to verify that restarting kubelet does not affect pod status when the pod has a
startupProbe. - Add an e2e test case to verify that restarting kubelet does not affect pod status when the pod has a
readinessProbe. - Add an e2e test case to verify that restarting kubelet does not affect pod status when the pod has both
startupProbeandreadinessProbe.
Graduation Criteria
deprecated
Implement the code and add the ChangeContainerStatusOnKubeletRestart feature gate.
Add e2e tests to ensure the functionality meets expectations.
GA
During the Deprecated phase, no issues were reported by users.
Upgrade / Downgrade Strategy
Version Skew Strategy
N/A
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
- Feature gate (also fill in values in
kep.yaml)- Feature gate name:
ChangeContainerStatusOnKubeletRestart - Components depending on the feature gate:
kubelet
- Feature gate name:
Does enabling the feature change any default behavior?
Yes, currently, when a kubelet restarts, the state of Pods and containers are reported as Not Ready. This feature changes the behavior to inherit the last state of Pods and containers, thus avoiding service inconsistencies, but may introduce delayed updates to the Not Ready state.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Yes. By setting the feature gate to false and restarting the kubelet, the cluster will revert to the previous default behavior. This rollback is safe since the feature does not involve storage modifications to API objects.
What happens if we reenable the feature if it was previously rolled back?
If the feature is re-enabled, the kubelet will once again adopt the new behavior of preserving pod status during restarts. Re-enabling the feature will not cause side effects, as it is stateless and only affects the kubelet’s startup logic.
Are there any tests for feature enablement/disablement?
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
Rolling back (disabling the feature gate) is inherently safe as it simply restores kubelet’ long-standing default behavior. The likelihood of failure is extremely low, as both deployment and rollback only require a kubelet restart. Running pods (workloads) will not be restarted. The purpose of deployment is to minimize impact on workloads, while rollback restores the current “impactful yet predictable” state.
What specific metrics should inform a rollback?
N/A
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
N/A
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
N/A
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
How can someone using this feature know that it is working for their instance?
- Events
- Event Reason:
- API .status
- Condition name:
- Other field:
- Other (treat as last resort)
- Details:
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
- [Optional] Aggregation method:
- Components exposing the metric:
- Other (treat as last resort)
- Details:
Are there any missing metrics that would be useful to have to improve observability of this feature?
Dependencies
Does this feature depend on any specific services running in the cluster?
No
Scalability
Will enabling / using this feature result in any new API calls?
No
Will enabling / using this feature result in introducing new API types?
No
Will enabling / using this feature result in any new calls to the cloud provider?
No
Will enabling / using this feature result in increasing size or count of the existing API objects?
No
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
No
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
What are other known failure modes?
What steps should be taken if SLOs are not being met to determine the problem?
Implementation History
Drawbacks
If a container becomes unhealthy during the kubelet restart, the kubelet may still report a Ready status until the Readiness probe completes its check. This can lead to other Kubernetes components making decisions based on stale information, such as directing traffic to an unhealthy Pod, resulting in service degradation or failed user requests.