KEP-4176: New CPUManager Static Policy which spread hyperthreads across physical CPUs to better utilize CPU Cache
KEP-4176: A new static policy to prefer allocating cores from different CPUs on the same socket
- Release Signoff Checklist
- Summary
- Goals
- Non-Goals
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- Infrastructure Needed (Optional)
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
In this KEP, we propose a new CPU Manager Static Policy Option called distribute-cpus-across-cores to prefer allocating CPUs from different physical cores on the same socket. This new policy is analogous to the distribute-cpus-across-numa policy option in that it proposes to spread CPU allocations out, rather than pack them together. The main difference being that this new policy spreads individual CPU allocations across cores, whereas the existing policy spreads them across NUMA nodes. Such a policy is useful, for example, if an application wants to avoid being a noisy neighbor with itself, but still take advantage of the L2 cache by running its threads on the same socket.
Goals
- Introduce a new CPU Manager Static Policy that spreads CPUs across physical cores without considering NUMA.
- Enhance application performance by taking advantage of L2 Cache.
Non-Goals
- This proposal does not aim to modify the existing CPU Manager Core Binding Policies. It focuses solely on introducing a new policy for spreading CPUs across physical cores.
- It does not address other resource allocation or management aspects within Kubernetes.
Proposal
We propose to add a new CPUManager policy option called distribute-cpus-across-cores to the static CPUManager policy. When enabled, this will trigger the CPUManager to try to allocate CPUs across physical cores as much as possible. It will not prohibit a CPU from being allocated on a core that already has a CPU allocated, but it will only resort to doing so once there is no other option.
User Stories (Optional)
Story 1 Bytedance Database Performance Optimization
We’re running DB instances in Kubernetes and adopt default static policy in the past. While, we notice that the performance of DB instances is not stable. If an instance is under pressure, in original way, it was allocated two CPUs from same physical core. However, an important pattern we notice is not always all instances are busy. After exploration, we find that the CPU cache is one bottleneck, once we allocate CPUs across physical cores, the busy instance can leverage more CPU cache and performance is improved a lot.
Story 2
Notes/Constraints/Caveats (Optional)
Risks and Mitigations
The risk associated with implementing this new proposal is minimal. It pertains only to a distinct policy option within the CPUManager and is safeguarded by the option’s inherent security measures, in addition to the default deactivation of the CPUManagerPolicyAlphaOptions feature gate.
| Risk | Impact | Mitigation |
|---|---|---|
| Bugs in the implementation lead to kubelet crash | High | Disable the policy option and restart the kubelet. The workload will run but with CPU packing semantics - like it was before this new policy option was added. |
Design Details
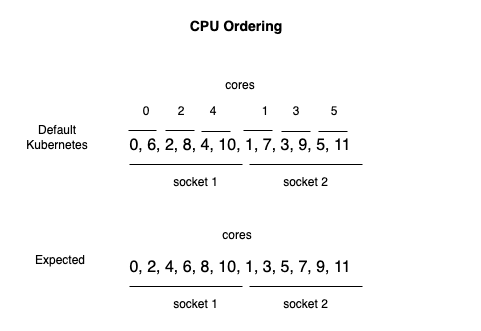
Current default sorting order is sockets, cores and then cpus. Using machine with 2 sockets, 6 cores, 12 CPUs topology as an example, default cpu ordering is [0, 6, 2, 8, 4, 10 | 1, 7, 3, 9, 5, 11]. In that case, if cpu manager plans to allocated two cpus, [0, 6] will be picked up. However, they belong to same socket, same numa node and same physical core which can not meet our case.
In order to meet our use case, we can change sorting algorithm to sort by socket and then directly cpus without taking physical cores into ordering. In that case, we get cpu sequence [0, 2, 4, 6, 8, 10 | 1, 3, 5, 7, 9, 11]. From the topology information, we know [0, 2] will be allocated for 2 cpu container and 0 and 2 are from same socket but different physical cores.
Test Plan
[x] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Prerequisite testing updates
Unit tests
k8s.io/kubernetes/pkg/kubelet/cm/cpumanager:20231005-86.3%
Integration tests
No new integration tests for kubelet are planned.
e2e tests
These cases will be added in the existing e2e_node tests:
CPU Manager works with
spread-physical-cpus-preferredstatic policy optionBasic functionality
- Enable
CPUManagerPolicyAlphaOptionsand configure CPUManager policy option tospread-physical-cpus-preferred. - Verify the machine has more than one physical cores.
- Create a simple pod with a container that requires 2 cpus.
- Verify that the container cpu allocation are across physical cores.
- Delete the pod.
Graduation Criteria
Alpha
- Feature implemented behind the existing static policy feature flag
- The functionality of new CPU allocation algorithm is implemented
- Initial unit tests completed and coverage is improved
- Documents is improved and enough guidance and examples can be given to potential users.
Upgrade / Downgrade Strategy
We anticipate no repercussions. The new policy option is voluntary and operates independently from the current selections.
Version Skew Strategy
No changes needed.
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
- Feature gate (also fill in values in
kep.yaml)- Feature gate name:
CPUManagerPolicyAlphaOptions - Components depending on the feature gate:
kubelet
- Feature gate name:
- Change the kubelet configuration to set a CPUManager policy of static and a CPUManager policy option of
spread-physical-cpus-preferred- Will enabling / disabling the feature require downtime of the control plane? No
- Will enabling / disabling the feature require downtime or reprovisioning of a node? (Do not assume Dynamic Kubelet Config feature is enabled). Yes – a kubelet restart is required.
Does enabling the feature change any default behavior?
No. In order to enable the feature, the user must explicitly set the CPUManager policy to static, enable CPUManagerPolicyAlphaOptions and the CPUManager policy option to spread-physical-cpus-preferred.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
For sure. The feature gate can be disabled in many ways.
- Set
CPUManagerpolicy tonone - Disable
CPUManagerPolicyAlphaOptions - select other policy options instead of
spread-physical-cpus-preferred
Ongoing workloads will maintain their operations without disruption, while upcoming tasks will receive CPU allocations in accordance with the reinstated policy.
What happens if we reenable the feature if it was previously rolled back?
If we reactivate the feature after a rollback, the outcome remains unchanged. Current containers will retain their allocations, while newly created containers will be affected.
Are there any tests for feature enablement/disablement?
A dedicated e2e test will validate the preservation of the default behavior when the feature gate is turned off, when the feature is unused, when pread-physical-cpus-preferred turns off but CPUManagerPolicyAlphaOptions is disabled. This will be conducted through three distinct test scenarios.
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
In the worst case, if the logic has panic and kubelet crashes, the kubelet will restart and the workload will run with the default policy. Running workloads won’t be affected.
What specific metrics should inform a rollback?
I verify the correctness by checking the kubelet log and the CPU allocation of the workload. I have not added any metrics against this new feature.
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
We manually test it in our internal environment and it works. It’s worth doing automated upgrade/rollback tests in the future.
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
No.
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
Examine the kubelet configuration of a node to verify the existence of the feature gate and the utilization of the new policy option.
How can someone using this feature know that it is working for their instance?
- Events
- Event Reason:
- API .status
- Condition name:
- Other field:
- Other (treat as last resort)
- Details: Inspect the kubelet configuration of the nodes: check feature gate and usage of the new option.
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
Even CPU allocation algorithm is changed in this case, it won’t cause any performance regression. So we don’t need to define any SLOs for this feature.
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
- [Optional] Aggregation method:
- Components exposing the metric:
- Other (treat as last resort)
- Details:
Are there any missing metrics that would be useful to have to improve observability of this feature?
N/A
Dependencies
N/A
Does this feature depend on any specific services running in the cluster?
No. It doesn’t rely on other Kubernetes components.
Scalability
Will enabling / using this feature result in any new API calls?
No
Will enabling / using this feature result in introducing new API types?
No
Will enabling / using this feature result in any new calls to the cloud provider?
No
Will enabling / using this feature result in increasing size or count of the existing API objects?
No
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
No
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
N/A
What are other known failure modes?
The failure modes is similar to existing options. It changes the way how cpu manager allocate CPUs. It’s compatible when user switch between options, however, when the pod get rescheduled, it will follow the current static option instead of previous one.
Currently, in alpha version, we will think it’s incompatile with other options. User should stick to this option. Compatibility issue would be resolved in future version.
When user switch to non static mode, then /var/lib/kubelet/cpu_manager_state requires deletion. This is a known compatibility issue.
What steps should be taken if SLOs are not being met to determine the problem?
Implementation History
Drawbacks
This allocation strategy tries to avoid workload taking entire physical core and it is not suitable for all workloads. For example, if the workload is CPU intensive and it’s not sensitive to CPU Cache, it’s not suitable to use this policy. Otherwise, the application may suffer from performance regression.