KEP-4020: Unknown Version Interoperability Proxy
KEP-4020: Unknown Version Interoperability Proxy
- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- Infrastructure Needed (Optional)
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and
SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
This proposal introduces a Mixed Version Proxy (also earlier referred to as Unknown Version Interoperability Proxy in the original version of the proposal) to solve issues with version skew in Kubernetes clusters. During upgrades or downgrades, when API servers have different versions, this feature ensures that:
- Client requests for a specific built-in resource are proxied to an API server capable of serving it, avoiding 404 Not Found errors
- Clients receive a complete, cluster-wide discovery document (we’ll call this the “peer-aggregated discovery”), by merging information from all peer API servers, preventing controllers from making incorrect decisions based on incomplete data
Peer-aggregated discovery is only supported for aggregated discovery endpoint, which requires clients to use the aggregated discovery Accept headers. Requests for un-aggregated (legacy) discovery will always return local-only data and do not participate in peer merging. All discovery changes are implemented at the existing aggregated discovery endpoint /apis, with no new discovery endpoints being introduced.
Note: Peer-aggregated discovery is not supported for the api endpoint (/api) that serves the core/v1 group. Since Kubernetes v1.4, no new top-level types have been added to core/v1 group; only subresources have been introduced:
- /api/v1/namespaces/{namespace}/pods/{name}/ephemeralcontainers
- /api/v1/namespaces/{namespace}/pods/{name}/resize
- /api/v1/namespaces/{namespace}/serviceaccounts/{name}/token
Given this history and the expectation that any future new types will be added to new groups rather than core/v1, we do not anticipate the need for peer-aggregating discovery for /api. This means that the set of top-level resource types in core/v1 is now considered complete and will not change in future Kubernetes releases; only subresources may be introduced. No new top-level resources will be added to core/v1 going forward.
Note 2: Peer-aggregated discovery is also not supported for requests to /apis/<group> and /apis/<group>/<version> since those are also served by un-aggregated discovery handler.
Motivation
When an upgrade or downgrade is performed on a cluster, for some period of time the apiservers are at differing versions and are able to serve different sets of built-in resources (different groups, versions, and resources are all possible).
In an ideal world, clients would be able to know about the entire set of available resources and perform operations on those resources without regard to which apiserver they happened to connect to. Currently this is not the case.
Today, these things potentially differ:
- Resources available somewhere in the cluster
- Resources known by a client (i.e. read from discovery from some apiserver)
- Resources that can be actuated by a client
This can have serious consequences, such as namespace deletion being blocked incorrectly or objects being garbage collected mistakenly.
Goals
- Ensure that a request for built-in resources is handled by an apiserver that is capable of serving that resource (if one exists)
- In the failure case (e.g. network not routable between apiservers), ensure that unreachable resources are served 503 and not 404.
- Ensure discovery reports the same set of resources everywhere (not just group versions, as it does today)
- Ensure that every resource in discovery can be accessed successfully
Non-Goals
- Lock particular clients to particular versions
Proposal
We will use the existing Aggregated Discovery mechanism to fetch which group, versions and resources an apiserver can serve.
API server change:
A new handler is added to the stack: If a request targets a group/version/resource the apiserver doesn’t serve locally (requiring a discovery request, which is optimized by caching the discovery document), the apiserver will consult its cache of agg-discovery as reported by peer apiservers. This cache is populated and updated by an informer on apiserver identity lease objects. The informer’s event handler makes discovery calls to each peer apiserver when its lease object is added or updated, ensuring the cache reflects the current state of each peer’s served resources. The apiserver uses this cache to identify which peer serves the requested resource.
Once it figures out a suitable peer to route the request to, it will proxy the request to that server. If that apiserver fails to respond, then we will return a 503 (there is a small possibility of a race between the controller registering the apiserver with the resources it can serve and receiving a request for a resource that is not yet available on that apiserver).
Discovery merging:
- During upgrade or downgrade, it may be the case that no apiserver has a complete list of available resources. To fix the problems mentioned, it’s necessary that discovery exactly matches the capability of the system.
Why so much work?
- Note that merely serving 503s at the right times does not solve the problem, for two reasons: controllers might get an incomplete discovery and therefore not ask about all the correct resources; and when they get 503 responses, although the controller can avoid doing something destructive, it also can’t make progress and is stuck for the duration of the upgrade.
- Likewise proxying but not merging the discovery document, or merging the discovery document but serving 503s instead of proxying, doesn’t fix the problem completely. We need both safety against destructive actions and the ability for controllers to proceed and not block.
User Stories
Garbage Collector
The garbage collector makes decisions about deleting objects when all referencing objects are deleted. A discovery gap / apiserver mismatch, as described above, could result in GC seeing a 404 and assuming an object has been deleted; this could result in it deleting a subsequent object that it should not.
This proposal will cause the GC to see the complete list of resources in discovery, and when it requests specific objects, see either the correct object or get a 503 (which it handles safely).
Namespace Lifecycle Controller
This controller seeks to empty all objects from a namespace when it is deleted. Discovery failures cause NLC to be unable to tell if objects of a given resource are present in a namespace. It fails safe, meaning it refuses to delete the namespace until it can verify it is empty: this causes slowness deleting namespaces that is a common source of complaint.
Additionally, if the NLC knows about a resource that the apiserver it is talking to does not, it may incorrectly get a 404, assume a collection is empty, and delete the namespace too early, leaving garbage behind in etcd. This is a correctness problem, the garbage will reappear if a namespace of the same name is recreated.
This proposal addresses both problems.
Notes/Constraints/Caveats (Optional)
Risks and Mitigations
Network connectivity isues between apiservers
Cluster admins might not read the release notes and realize they should enable network/firewall connectivity between apiservers. In this case clients will receive 503s instead of transparently being proxied. 503 is still safer than today’s behavior. We will clearly document the steps needed to enable the feature and also include steps to verify that the feature is working as intended. Looking at the following exposed metrics can help wth that
kubernetes_apiserver_rerouted_request_totalto monitor the number of (UVIP) proxied requests. This metric can tell us the number of requests that were successfully proxied and the ones that failedapiserver_request_totalto check the success/error status of the requests
Increase in egress bandwidth
Requests will consume egress bandwidth for 2 apiservers when proxied. We can cap the number if needed, but upgrades aren’t that frequent and few resources are changed on releases, so these requests should not be common. We will count them with a metric.
Increase in request traffic directed at destination kube-apiserver
There could be a large volume of requests for a specific resource which might result in the identified apiserver being unable to serve the proxied requests. This scenario should not occur too frequently, since resource types which have large request volume should not be added or removed during an upgrade - that would cause other problems, too.
Indefinite rerouting of the request
We should ensure at most one proxy, rather than proxying the request over and over again (if the source apiserver has an incorrect understanding of what the destination apiserver can serve). To do this, we will add a new header such as
X-Kubernetes-APIServer-Rerouted:trueto the request once it is determined that the request cannot be served by the local apiserver and should therefore be proxied.
We will remove this header after the request is received by the destination apiserver (i.e. after the proxy has happened once) at which point it will be served locally.Putting IP/endpoint and trust bundle control in user hands in REST APIs
To prevent server-side request forgeries we will not give control over information about apiserver IP/endpoint and the trust bundle (used to authenticate server while proxying) to users via REST APIs.
Failure to Initialize Peer Discovery
If the
kube-apiserveris not started with the necessary certificates and keys (--proxy-client-key/certand--peer-ca-fileand--requestheader-client-ca-file) required for peer-to-peer authentication, the peer discovery controller will fail to initialize. The peer-aggregated discovery handler is designed to fall back to serving the local, peer-unaggregated discovery response in this scenario, allowing the API server to remain operational without compromising the safety of the cluster.Temporary Staleness of Peer Aggregated Discovery Cache When a Peer Leaves
Peer-aggregated discovery is constructed from aggregate-discovery responses from peers. The existing peers in a cluster are fetched via an informer on apiserver identity lease objects. When a peer apiserver leaves, its apiserver identity lease remains for up to 1 hour (reference ). During this period, the peer’s discovery information may persist in the peer-aggregated discovery cache, causing it to be temporarily stale. To avoid this long duration of staleness, we will add a pre-shutdown hook for the apiserver to clean up its own identity lease upon graceful shutdown. To avoid the case of a lingering lease in case of a server crash, we will also proactively delete any stale leases found upon server startup, which should eventually be followed up by creation of a brand new lease object. This active clean up of stale leaes will ensure that the peer-aggregated discovery correctly reports discovery info from servers that actually exist in a cluster at a given time.
Design Details
Aggregation Layer
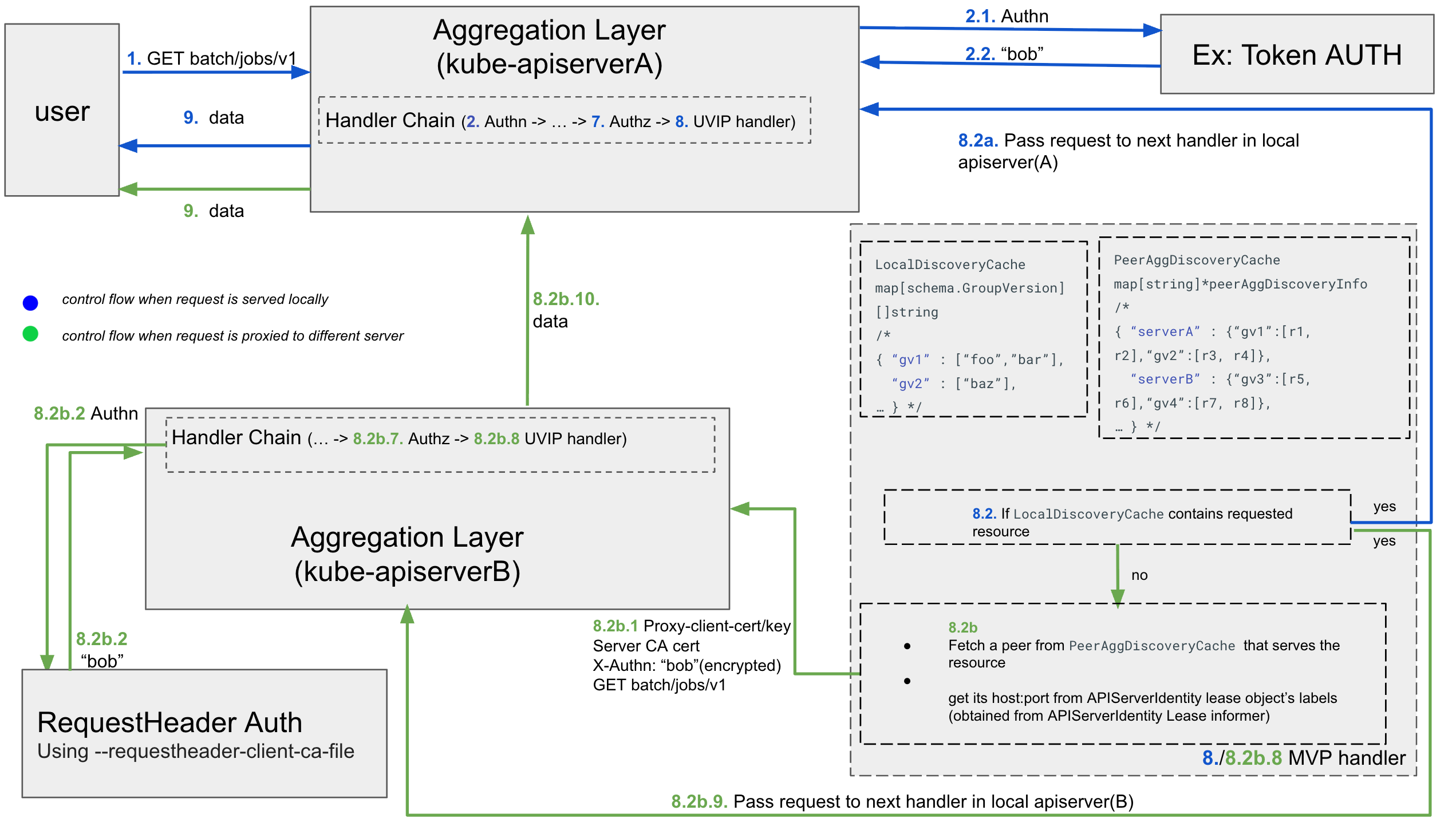
A new handler will be added to the handler chain of the aggregation layer. This handler will maintain the following internal caches:
- LocalDiscovery cache:
- Stores the set of resources served by the local API server, organized by group-version
- Populated via a discovery call using a loopback client
- A post-start hook ensures this cache is fully populated before the API server begins serving requests
- The cache is periodically refreshed (every 30 minutes) to ensure it remains up-to-date and the apiserver has a complete view of its served resources before processing any incoming requests
- PeerDiscovery cache:
- Stores the resources served by each peer API server in the cluster
- Populated by a peer-discovery controller, which watches apiserver identity Lease objects
- When a lease is created or updated (as a result of a change in holderIdentity e.g., due to a server restart), the controller makes a discovery request to the corresponding peer API server
- This cache is essential for both - building the peer-aggregated discovery response and determining which peer can handle a proxied resource request
- LocalDiscovery cache:
This handler will pass on the request to the next handler in the local aggregator chain, if:
- It is a non resource request
- The LocalDiscovery cache or the apiserver identity lease informer hasn’t synced yet. We will serve error 503 in this case
- The request has a header
X-Kubernetes-APIServer-Rerouted:truethat indicates that this request has been proxied once already. If for some reason the resource is not found locally, we will serve error 503 - The requested resource was listed in the LocalDiscovery cache
- No other peer apiservers were found to exist in the cluster
If the requested resource was not found in the LocalDiscovery cache, it will try to fetch the resource from the PeerDiscovery cache. The request will then be proxied to any peer apiserver, selected randomly, thats found to be able to serve the resource as indicated in the PeerDiscovery cache.
- There is a possibility of a race condition regarding creation/update of an aggregated resource or a CRD and its registration in the LocalDiscovery cache. This transient state is mitigated by a periodic refresh of the local discovery cache every 30 minutes. In such cases, the request will be routed to the peer.
If there is no eligible apiserver found in the PeerDiscovery cache for the requested resource, it will pass on the request to the next handler in the handler chain. This will either
- be eventually handled by the apiextensions-apiserver or the aggregated-apiserver if the request was for a custom resource or an aggregated resource which was created/updated after we established both the LocalDiscovery and the PeerDiscovery caches
- be returned with a 404 Not Found error for cases when the resource doesn’t exist in the cluster
If the proxy call fails for network issues or any reason, it will serve 503 with error
Error while proxying request to destination apiserverWe will add a poststarthook for the apiserver to ensure that it does not start serving requests until
- we have populated the LocalDiscovery cache
- apiserver identity informer is synced
Identifying destination apiserver’s network location
We will be performing dual writes of the ip and port information of the apiservers in:
A clone of the endpoint reconciler’s masterlease which would be read by apiservers to proxy the request to a peer. We will use a separate reconciler loop to do these writes to avoid modifying the existing endpoint reconciler
APIServerIdentity Lease object for users to view this information for debugging
We will use an egress dialer for network connections made to peer kube-apiservers. For this, will create a new type for the network context to be used for peer kube-apiserver connections (xref )
Proxy transport between apiservers and authn
For the mTLS between source and destination apiservers, we will do the following
For server authentication by the client (source apiserver) : the client needs to validate the server certs (presented by the destination apiserver), for which it will
- look at the CA bundle of the authority that signed those certs. We will introduce a new flag –peer-ca-file for the kube-apiserver that will be used to verify the presented server certs. If this flag is not specified, the requests will fail with error 503
- look at the ServerName
kubernetes.default.svcfor SNI to verify server certs against
The server (destination apiserver) will check the client (source apiserver) certs to determine that the proxy request is from an authenticated client. We will use requestheader authentication (and NOT client cert authentication) for this. The client (source apiserver) will provide the proxy-client certfiles to the server (destination apiserver) which will verify the presented certs using the CA bundle provided in the [–requestheader-client-ca-file](https://github.com/kubernetes/kubernetes/blob/release-1.27/staging/src/k8s.io/ apiserver/pkg/server/options/authentication.go#L125-L128) passed to the apiserver upon bootstrap
Discovery Merging
A new handler is introduced to serve a consolidated discovery document, combining local and peer API server data. This handler extends the existing aggregated discovery endpoints (/apis and /api); no new endpoints are introduced.
This handler is responsible for the following actions:
- Document Generation: Merges local discovery data with PeerDiscovery cache to create a comprehensive view of all API groups and resources available in the cluster
- Client Negotiation: Interprets a new
profileparameter in the Accept header- By default, serves the peer-aggregated discovery document
- If
profile=nopeeris specified, serves the local-only discovery response. This is used for PeerDiscovery cache population and for backward compatibility
- Backward Compatibility: The handler ensures that local (non peer-aggregated) discovery requests continue to function as before. When a newer API server (with the feature enabled) needs to fetch discovery information from an older peer (which is unaware of the feature), it sends a discovery request with the Accept header:
application/json;g=apidiscovery.k8s.io;v=v2;as=APIGroupDiscoveryList;profile=nopeer, application/json;g=apidiscovery.k8s.io;v=v2;as=APIGroupDiscoveryList, application/json;...;q=0.9. This header signals the preference for a local (non peer-aggregated) response. The older peer, which does not recognize theprofile=nopeerparameter, simply falls back to its standard discovery behavior and returns its local discovery document. This guarantees that the request succeeds and allows the newer API server to collect the necessary unmerged data for its peer cache.
Caching and consistency
The peer-aggregated discovery response is cached in memory for performance. This cache is automatically invalidated and refreshed under two conditions:
- When the local API server’s discovery cache changes (e.g., due to resource additions or removals)
- When peer API server discovery information changes (e.g., a peer joins or leaves, triggered by lease informer events)
This two-layer caching strategy provides a robust feedback loop:
Case 1: Peer API server change sequence
- Peers Announce: API servers announce their presence(or absence) via identity leases
- Caches Update: The informer on these leases triggers the repopulation of the peer discovery cache on each API server
- Peer-aggregated discovery cache Invalidates: An update to the peer discovery cache automatically invalidates the peer-aggregated discovery cache
- Recalculation: The next peer-aggregated discovery request triggers a single, optimized recalculation of the peer-aggregated discovery response, which is then cached for subsequent requests
Case 2: Local Discovery change sequence
- Local Resource Change: The API server detects a change in its own resources (e.g., an API group or version is added, removed, or updated)
- Local Discovery Cache Update: The local discovery cache is updated to reflect the new set of available resources
- Peer-aggregated discovery cache Invalidates: Any update to the local discovery cache automatically invalidates the peer-aggregated discovery cache
- Recalculation: The next peer-aggregated discovery request triggers a single, optimized recalculation of the peer-aggregated discovery response, which is then cached for subsequent requests
Test Plan
[x] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Prerequisite testing updates
Unit tests
pkg/controlplane/apiserver/options:07/18/2023-100%staging/src/k8s.io/apiserver/pkg/util/peerproxy:03/18/2025-100%staging/src/k8s.io/apiserver/pkg/reconcilers:07/18/2023-100%staging/src/k8s.io/apiserver/pkg/endpoints/discovery/aggregated:09/06/2025-100%
Integration tests
In the first alpha phase, the integration tests are expected to be added for:
Resource request routing tests:
- The behavior with feature gate turned on/off
- Request is proxied to an apiserver that is able to handle it
- Validation that a request is proxied to the available peer if another eligible peer becomes unavailable
Peer-aggregated discovery tests:
- Validation that the peer-aggregated discovery endpoint correctly combines API groups and resources from multiple API servers with different served resources
- Validation of the Accept header negotiation, ensuring that by default we return the consolidated document, while
profile=nopeerAccept header returns the local document
e2e tests
We will test the feature mostly in integration test and unit test. We may add e2e test for spot check of the feature presence.
Graduation Criteria
Alpha
- Proxying implemented (behind feature flag)
- mTLS or other secure system used for proxying
- Ensure proper tests are in place.
Beta
- Discovery document merging implemented
- Use egress dialer for network connections made to peer kube-apiservers
- Error metrics added for peer proxy failures and discovery sync failures
- Integration tests for peer-aggregated discovery and request proxying
- Documentation for configuring peer connectivity (–peer-ca-file, –peer-advertise-ip, –peer-advertise-port)
GA
- TODO: wait for beta to determine any further criteria
Upgrade / Downgrade Strategy
In alpha, no changes are required to maintain previous behavior. And the feature gate can be turned on to make use of the enhancement.
Version Skew Strategy
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
- Feature gate (also fill in values in
kep.yaml)- Feature gate name: UnknownVersionInteroperabilityProxy
- Components depending on the feature gate: kube-apiserver
Does enabling the feature change any default behavior?
Yes, requests for built-in resources at the time when a cluster is at mixed versions will be served with a default 503 error instead of a 404 error, if the request is unable to be served.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Yes, disabling the feature will result in requests for built-in resources in a cluster at mixed versions to be served with a default 404 error in the case when the request is unable to be served locally.
What happens if we reenable the feature if it was previously rolled back?
The request for built-in resources will be proxied to the apiserver capable of serving it, or else be served with 503 error.
Are there any tests for feature enablement/disablement?
Unit test and integration test will be introduced in alpha implementation.
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
The proxy to remote apiserver can fail if there are network restrictions in place that do not allow an apiserver to talk to a remote apiserver. In this case, the request will fail with 503 error.
What specific metrics should inform a rollback?
- apiserver_request_total metric that will tell us if there’s a spike in the number of errors seen meaning the feature is not working as expected
apiserver_peer_proxy_errors_totalmetric indicating frequent failures when proxying to peersapiserver_peer_discovery_sync_errors_totalmetric indicating problems syncing discovery from peers
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
Upgrade and rollback will be tested before the feature goes to Beta.
Is the rollout accompanied by any deprecations and/or removals of features
APIs, fields of API types, flags, etc.?
No.
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
The following metrics could be used to see if the feature is in use:
apiserver_rerouted_request_totalwhich is incremented anytime a resource request is proxied to a peer apiserverapiserver_peer_proxy_errors_total(labels:type) which is incremented when a proxy request to a peer fails. Thetypelabel indicates the failure reason:endpoint_resolution: failed to resolve the network address of a peer apiserverproxy_transport: failed to build the proxy transport for the request
apiserver_peer_discovery_sync_errors_total(labels:type) which is incremented when syncing discovery information from a peer fails. Thetypelabel indicates the failure reason:lease_list: failed to list apiserver identity leaseshostport_resolution: failed to resolve host/port from an identity leasefetch_discovery: failed to fetch discovery document from a peer
aggregator_discovery_peer_aggregated_cache_misses_totalwhich is incremented everytime we construct a peer-aggregated discovery response by merging resources served by a peer apiserveraggregator_discovery_peer_aggregated_cache_hits_totalwhich is incremented everytime peer-aggregated discovery was served from the cacheaggregator_discovery_nopeer_requests_totalwhich is incremented everytime a no-peer discovery was requested
How can someone using this feature know that it is working for their instance?
- Metrics like
apiserver_rerouted_request_totalcan be used to check how many resource requests were proxied to remote apiserver - The
aggregator_discovery_peer_aggregated_cache_misses_totalandaggregator_discovery_peer_aggregated_cache_hits_totalmetrics will show activity when peer-aggregated discovery responses are constructed and served - The
aggregator_discovery_nopeer_requests_totalmetric will increment when local (non peer-aggregated) discovery is requested
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
- The peer-aggregated discovery endpoint should reliably return a complete and up-to-date set of resources available in the cluster, except for brief periods during peer lease expiration or network partition
- The percentage of proxied resource requests that result in a successful response (not 5XX) should be high (>99% under normal conditions)
- The system should minimize the duration of staleness in the peer-aggregated discovery cache (O(seconds) in the normal case, O(single digit minutes) in the worst case)
- The feature should not introduce significant latency or error rates for standard API operations
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
apiserver_rerouted_request_total- Components exposing the metric: kube-apiserver
- Metric name:
apiserver_peer_proxy_errors_total- Components exposing the metric: kube-apiserver
- Labels:
type(endpoint_resolution, proxy_transport)
- Metric name:
apiserver_peer_discovery_sync_errors_total- Components exposing the metric: kube-apiserver
- Labels:
type(lease_list, hostport_resolution, fetch_discovery)
- Metric name:
aggregator_discovery_peer_aggregated_cache_hits_total- Components exposing the metric: kube-apiserver
- Metric name:
aggregator_discovery_peer_aggregated_cache_misses_total- Components exposing the metric: kube-apiserver
- Metric name:
aggregator_discovery_nopeer_requests_total- Components exposing the metric: kube-apiserver
- Metric name:
Are there any missing metrics that would be useful to have to improve observability of this feature?
No. We are open to input.
Dependencies
Does this feature depend on any specific services running in the cluster?
No, but it does depend on
APIServerIdentityfeature in kube-apiserver that creates a lease object for APIServerIdentity which we will use to store the network location of the remote apiserver for visibility/debugging
Scalability
Will enabling / using this feature result in any new API calls?
Yes, enabling this feature will result in new API calls. Specifically:
- Discovery calls via a loopback client: The local apiserver will use a loopback client to discover the resources it serves for each group-version. This should only happen once upon server startup.
- Remote discovery calls to peer apiservers: The event handler for apiserver identity
lease informer will make remote discovery calls to each peer apiserver whose
- identity lease is created
- identity lease is updated as a result of change in holderIdentity implying a server restart
Will enabling / using this feature result in introducing new API types?
No.
Will enabling / using this feature result in any new calls to the cloud provider?
No.
Will enabling / using this feature result in increasing size or count of the existing API objects?
No.
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
The Local Discovery, Peer Discovery and Peer-aggregated Discovery caches should take care of not causing delays while handling a request.
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
Requests will consume egress bandwidth for 2 apiservers when proxied. We can put a limit on this value if needed.
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No.
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
If the API server/etcd is unavailable the request will fail with 503 error.
What are other known failure modes?
None.
What steps should be taken if SLOs are not being met to determine the problem?
- The feature can be disabled by setting the feature-gate to false if the performance impact of it is not tolerable.
- The peer-to-peer connection between API servers should be checked to ensure that the remote API servers are reachable from a given API server
Implementation History
- v1.28: Mixed Version Proxy KEP merged and moved to alpha
- v1.33: Replaced StorageversionAPI with AggregatedDiscovery to fetch served resources by peer apiservers
- v1.35: Peer-aggregated Discovery implemented
- v1.36: Added egress dialer, error metrics for peer proxy and discovery sync failures
Drawbacks
Alternatives
Network location of apiservers
- Use endpoint reconciler’s masterlease
- We will use the already existing IP in Endpoints.Subsets.Addresses of the masterlease by default
- For users with network configurations that would not allow Endpoints.Subsets.Addresses to be reachable from a kube-apiserver, we will introduce a new optional –bind-peer-ip flag to kube-apiserver. We will store its value as an annotation on the masterlease and use this to route the request to the right destination server
- We will also need to store the apiserver identity as an annotation in the masterlease so that we can map the identity of the apiserver to its IP
- We will also expose the IP and port information of the kube-apiservers as annotations in APIserver identity lease object for visibility/debugging purposes
Pros
- Masterlease reconciler already stores kube-apiserver IPs currently
- This information is not exposed to users in an API that can be used maliciously
- Existing code to handle lifecycle of the masterleases is convenient
Cons
- using masterlease will include making some changes to the legacy code that does the endpoint reconciliation which is known to be brittle
- Use coordination.v1.Lease
- By default, we can store the External Address of apiservers as labels in the APIServerIdentity Lease objects.
- If
--peer-bind-addressflag is specified for the kube-apiserver, we will store its value in the APIServerIdentity Lease label - We will retrieve this information in the new UVIP handler using an informer cache for these lease objects
Pros
- Simpler solution, does not modify any legacy code that can cause unintended bugs
- Since in approach 1 we decided we want to store the apiserver IP, port in the APIServerIdentity lease object anyway for visibility to the user, we will be just making this change once in the APIServerIdentity lease instead of both here and in masterleases
Cons
- If we take this approach, there is a risk of giving the user control of the apiserver IP, port information. This can lead to apiservers routing a request to a rogue IP:port specified in the lease object.