KEP-2837: Pod Level Resource Specifications
KEP-2837: Pod Level Resource Specifications
- Release Signoff Checklist
- Summary
- Motivation
- Proposal
- Design Details
- Design Principles
- Components/Features changes
- Cgroup Structure Remains unchanged
- PodSpec API changes
- PodSpec Validation Rules
- Scheduler Changes
- QoS Changes
- OOM Killer Behavior
- Init Containers & Sidecar Containers
- Ephemeral Containers
- Admission Controller
- Eviction Manager
- Pod Overhead
- Hugepages
- [Scoped for Beta in 1.36] Fix for pod-level limits default Logic (Issue 136120)
- [Scoped for Beta in 1.36] Fix for Kubelet QoS Class Determination (Issue 135082)
- [Scoped for Beta] Cluster Autoscaler
- [Scoped for Beta] HPA
- Cluster Autoscaler
- VPA
- Instrumentation
- Test Plan
- Graduation Criteria
- Upgrade / Downgrade Strategy
- Version Skew Strategy
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- Future Work
- [Future KEP Consideration in 1.35] Support for Windows
- [Future KEP Consideration in 1.35] Memory Manager
- [Future KEP Consideration in 1.35] CPU Manager
- [Future KEP Consideration in 1.35] Topology Manager
- [Future KEP Consideration in collaboration with sig-autoscaling] VPA
- [Scoped for GA] User Experience Survey
Release Signoff Checklist
Items marked with (R) are required prior to targeting to a milestone / release.
- (R) Enhancement issue in release milestone, which links to KEP dir in kubernetes/enhancements (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- e2e Tests for all Beta API Operations (endpoints)
- (R) Ensure GA e2e tests meet requirements for Conformance Tests
- (R) Minimum Two Week Window for GA e2e tests to prove flake free
- (R) Graduation criteria is in place
- (R) all GA Endpoints must be hit by Conformance Tests
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in kubernetes/website , for publication to kubernetes.io
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Summary
Currently resource allocation on PodSpec is container-centric, allowing users to specify resource requests and limits for each container. The scheduler uses the aggregate of the requested resources by all containers in a pod to find a suitable node for scheduling the pod. The kubelet then enforces these resource constraints by translating the requests and limits into corresponding cgroup settings both for containers and for the pod (where pod level values are aggregates of container level values derived using the formula in KEP#753 ). The existing Pod API lacks the ability to set resource constraints at pod level, limiting the flexibility and ease of resource management for pods as a whole. This limitation is particularly problematic when users want to focus on controlling the overall resource consumption of a pod without the need to meticulously configure resource specifications for each individual container in it.
To address this, this KEP proposes extending the Pod API to support Pod-level resource limits and requests for non-extended resources (CPU, Memory and Hugepages), in addition to the existing container-level settings.
Motivation
Kubernetes workloads often consist of multiple containers collaborating within a pod. While this separation enables granular monitoring and management of each container, it can be challenging to accurately estimate and allocate resources for individual containers, especially for workloads with unpredictable or bursty resource demands. This often leads to over-allocation of resources to ensure that no container experiences resource starvation, as kubernetes currently lacks a mechanism for sharing resources between containers within a pod easily.
Introducing pod-level resource requests and limits offers a more simplified resource management for multi-container pods as it is easier to gauge the collective resource usage of all containers in a pod rather than predicting each container’s individual needs. This proposal seeks to support pod-level resource management, enabling Kubernetes to control the total resource consumption of the pod, relieving users from the burden of meticulously configuring resources for each container. This simplified approach is particularly valuable for tightly coupled applications, and it will enable Kubernetes to leverage the underlying cgroup resource management mechanisms more effectively for better resource utilization for bursty workloads.
This new feature of resource specification at pod-level would complement, not replace, the existing container-level limits, providing users with greater flexibility.
Goals
This proposal aims to:
- Extend Pod API to allow specifying resource spec (requests and limits) at the pod level.
- Make this feature compatible with existing usage of container level requests/limits, and other features like topology manager, memory manager, VPA etc.
Non Goals
- This KEP focuses on the core resource types of CPU, memory and hugepages. It doesn’t intend to address other resource types (e.g. GPU, storage, network bandwidth) at the pod level in this phase. However, it could be considered in future extensions of the KEP.
- Pod-level device plugins: existing container-level device plugins are compatible with this proposal, but there are some discussions on how to share device(s) among containers within a pod, which is out of scope of this KEP.
- This proposal will not explore dynamic QoS class adjustments based on runtime conditions or pod phases. Instead, it will focus on static QoS class determination based on pod-level and container-level resources. Future explorations into dynamic QoS changes may be considered in subsequent proposals.
- This proposal does not aim to implement fine-grained control over resource sharing within a pod. While pod-level resources facilitate basic resource sharing, more advanced controls such as weighted sharing and prioritization are outside the current scope. These enhancements may be explored in future proposals.
- This proposal does not focus on performance optimizations for specific workloads. Although the feature is anticipated to enhance resource utilization, specific optimizations for particular workloads, such as high-performance computing, will be considered in future iterations.
Proposal
User Stories
Simplified Resource Management
There are cases when it is challenging to decide a-priori how much resources to allocate to each container in a pod. For instance, consider a development environment implemented as a Kubernetes Pod with multiple sidecar containers for tools, and a regular container for web-based IDE. The IDE container may have a fixed memory limit, but the resource needs of the tool containers can fluctuate depending on the developer’s activities.
The proposed Pod Level Resource Spec feature addresses this by allowing all containers within the pod to share a defined resource pool. In the example provided, even though the IDE has its own resource constraints, tool1 and tool2 containers can dynamically utilize any remaining resources within the pod’s overall limit.
apiVersion: v1
kind: Pod
metadata:
labels:
run: ide
name: myide
spec:
resources:
limits:
memory: "1024Mi"
cpu: "4"
initContainers:
- image: debian:buster
name: shell
restartPolicy: Always
- image: first-tool:latest
name: tool1
restartPolicy: Always
- image: second-tool:latest
name: tool2
restartPolicy: Always
containers:
- name: ide
image: theia:latest
resources:
requests:
memory: "128Mi"
cpu: "0.5"
limits:
memory: "256Mi"
cpu: "1"
Without this feature, the developers will need to estimate beforehand how much resources to allocate to the tools, a task that can be challenging especially for workloads with varying resource demands.
Better Resource Utilization
When multiple containers within a pod experience independent and uncoordinated spikes in resource usage, the current container-level resource management can result in significant waste. Resources are allocated based on the peak usage of each container, even if those peaks do not occur simultaneously. As a result, while one container may be using a large amount of resources, others might remain idle, leading to underutilization within the pod.
Pod-level resource specifications provide a more efficient strategy for resource allocation. By setting limits at the pod level, containers can dynamically share resources. This allows one container experiencing a spike to access idle resources from others, optimizing overall utilization.
Since resource demands across containers are often not synchronized, the total resource usage of the pod is usually lower than the sum of the individual peak usages. By establishing pod-level limits based on this aggregate demand, organizations can enhance resource efficiency and avoid unnecessary over-allocation.
For instance, in an AI/ML Batch Processing Workload involving tightly coupled containers that execute tasks on large datasets, resource demands can vary significantly based on the size of the data and the complexity of the operations. Different stages of batch processing might experience peaks at different times. For example, data cleaning may require more memory when handling complex datasets, whereas data transformation could be less resource-intensive. If resources are allocated at the container level based on peak estimates, this can lead to scenarios where one container consumes its allocated resources while others remain underutilized, resulting in inefficiencies.
Moreover, manually tuning requests and limits for each container can be time-consuming and complex. By defining pod-level limits, all containers can dynamically share the designated resources. For example, when one container is performing a resource-intensive task, it can leverage the unused resources of other containers within the pod. This approach not only improves overall resource utilization but can also lead to cost savings in cloud environments where resource allocation impacts billing.
Note: Understanding the distinction between resource sharing with pod-level resources feature and with burstable pods is important. While both allow containers to share resources with other containers, they both operate at different scopes. Pod-level resources enable containers within a pod to share unused resoures amongst themselves, promoting efficient utilization within the pod. In contrast, burstable pods allows sharing of spare resources between containers in any pods on the node. This means a container in a burstable pod can use resources available elsewhere on the node.
Notes/Constraints/Caveats
cgroupv1 has been moved to maintenance mode since Kubernetes version 1.31. Hence this feature will be supported only on cgroupv2. Kubelet will fail to admit pods with pod-level resources on nodes with cgroupv1.
Pod Level Resource Specifications is an opt-in feature, and will have no effect on existing deployments. Only deployments that explicitly require this functionality should turn it on by setting the relevant resource section at pod-level in the Pod specification.
In alpha stage of Pod-level Resources feature, when using pod-level resources, in-place pod resizing is unsupported with in-place pod resizing. Users won’t be able to use in-place pod resize with pod-level resources enabled.
Risks and Mitigations
Since Pod Level Resource Specifications is an opt-in feature, merging the feature related changes won’t impact existing workloads. Moreover, the feature will be rolled out gradually, beginning with an alpha release for testing and gathering feedback. This will be followed by beta and GA releases as the feature matures and potential problems and improvements are addressed.
While this feature doesn’t alter the existing cgroups structure, it does change how pod-level cgroup values are determined. Currently, Kubernetes derived these values from the container-level cgroup settings. However, with Pod Level Resource Specifications enabled, pod-level cgroup settings will be directly set based on the values specified in the pod’s resource spec stanza, if set. This change in behavior could potentially affect:
Workloads or tools that rely on reading cgroup values: This means that any workloads or tools that depend on reading or interpreting container cgroup values might observe different derived values if pod-level resources are specified without container level settings.
Third-party schedulers or tools that make assumptions about pod-level resource calculation: These tools might require adjustments to accommodate the new way pod-level resources are determined.
To mitigate potential issues, the feature documentation will clearly highlight this change and its potential impact. This will allow users to:
- Adjust their pod-level and container-level resource settings as needed
- Modify any custom schedulers or tools to align with new resource calculation method.
Design Details
Design Principles
To ensure this feature is intuitive, and beneficial, and complies with existing container-level resources design, we adhered to the following core design principles:
Prioritize Explicit Pod-Level Settings: When users explicitly define resource requests or limits at pod-level, these settings take precedence. This respects the user’s intent and provides clarity in resource allocation.
Consistent Derivation from Container Values: If pod-level resources are not explicitly defined, they are derived consistently from the container-level resource specifications, if container-level requests are set. This ensures predictability and maintains the expected behavior of existing applications.
Symmetric Semantic For Consistency & Compatibility With Existing Behavior: This principle ensures consistency between how Kubernetes handles resource requests at both the container level and the pod level. We preserve the existing container-level behavior where a missing resource request defaults to the container’s limit, if set, and extend this same logic to pods. This means that at the pod level, if a resource request is not explicitly defined, Kubernetes attempts to derive it from requests specified at container-level within the pod. However, container-level requests are not set for at least 1 container, the pod-level request cannot be accurately derived. In this case, the pod’s resource request will default to the pod’s limit, if pod limit is set. This ensures consistency and predictability across both levels of resource management.
Fairness: The resource allocation mechanism aims to be fair among containers within a pod. No single container can monopolize resources unless explicitly configured to do so by setting container-level requests. For example, OOM score adjustment calculation below demonstrates the fairness in our design.
Flexibility: The design allows for flexibility in resource allocation. Users can express different resource requirements and sharing strategies as needed. For example, optional pod-level resources, combination of pod-level and container-level limits, etc. make the resource allocation flexible enough to meet the different requirements.
Components/Features changes
Cgroup Structure Remains unchanged
This KEP introduces pod-level resource specifications but does not alter the fundamental cgroup structure. Currently, pod level cgroups are derived from the resource requests and limits defined at the container level in the PodSpec. With this KEP, the PodSpec is extended to include pod-level resource requests and limits. These values will be directly used to configure the pod-level cgroup, providing a more direct and explicit way to manage the overall resource consumption of the pod.
PodSpec API changes
New field in PodSpec:
type PodSpec struct {
...
// The total amount of compute resources required by all containers in the pod.
// Currently, only CPU and Memory resources are supported .
// +featureGate=PodLevelResources
// +optional
Resources ResourceRequirements
}
PodSpec Validation Rules
Proposed Validation & Defaulting Rules
To ensure clarity and prevent ambiguity in resource allocation, the following validation rules are proposed for pod-level resource specifications:
In alpha, invalidate requests to update resources at container-level if
resourcesis set in PodSpec.Pod-level Resources Priority: If pod-level requests and limits are explicitly set, they take precedence over container-level settings. Defaulting logic is only applied when pod-level requests and/or limits are not explicitly specified.
The aggregated container requests cannot be greater than pod-level request or limit.
The aggregate container-level limits can exceed pod-level limits, but the total resource consumption across all containers in a pod will always remain within the pod-level limit. While the total container limits can exceed pod-level requests or limits, no single container limit can exceed the pod-level limit.
Container-level Defaulting:
- [Existing Rule] If the container-level request is not set, but the container-level limit is set, then the container-level request defaults to the container-level limit. PR#12035
- [Existing Rule] If neither container-level nor pod-level requests and limits are set, then the Kubernetes scheduler applies implementation-defined minimum as the container request. The pod-level request is derived as the product of the number of containers and this minimum value. These values won’t appear in the pod specification.
Pod-level Defaulting:
- If pod-level requests or limits are not set, they will be derived from the individual container requests and limits within the pod.
- If a pod-level request is not defined, but a pod-level limit is specified and no container requests are set, Kubernetes is unable to derive the pod-level request from the container requests unless at least one container has a request defined. In this case, the pod-level request defaults to the pod-level limit.
Supported Resources: Currently, pod level resources support only CPU and memory.
Comprehensive Tabular View
The table below presents a comprehensive view of how Kubernetes handles resource requests and limits, tracing the flow of these values from the initial user defined Pod specification, through the application of default values, to final cgroup settings that enforce the resource constraints on the containers.
Table Legend:
- CR = Container-level Requests as specified in the Pod Spec
- CL = Container-level Limits as specified in the Pod Spec
- PR = Pod-level Request as specified in the Pod Spec
- PL = Pod-level Limit as Specified in the Pod Spec
- f() = Formula to calculate resource requirements as described in KEP#753
- default min = Respective default minimum cgroup value for a resource.
- cpu.weight default min value is 1
- memory.min the default minimum value is 0.
- default max = Respective default maximum cgroup value for a resource. It is equal to node allocatable.
Rows 1 - 4 state the existing rules for container-level resource management, while rows 5 - 16 outline the proposed rules with the addition of pod-level resource specifications.
Rows 1 - 4
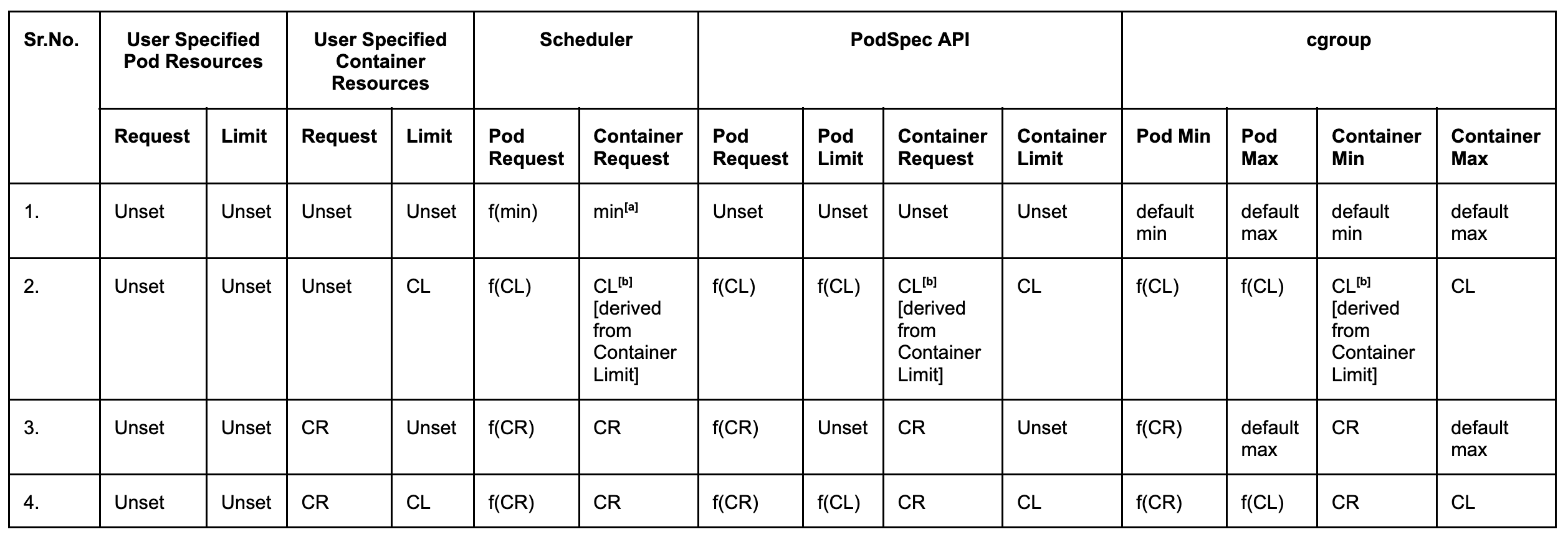
Row 1 Annotation [a]: When container-level requests and limits are not set, the scheduler uses the default minimum values for CPU and memory requests . These minimum values are not applied to the PodSpec itself; they are solely used by the scheduler for scheduling decisions.
Row 2 Annotation [b]: For container level resources, if a request is not specified but a limit it set, the Pod Spec is modified to set the request equal to limit for each container. This modified Pod spec is then used by the scheduler, and also for configuring cgroup settings.
Rows 5 - 8
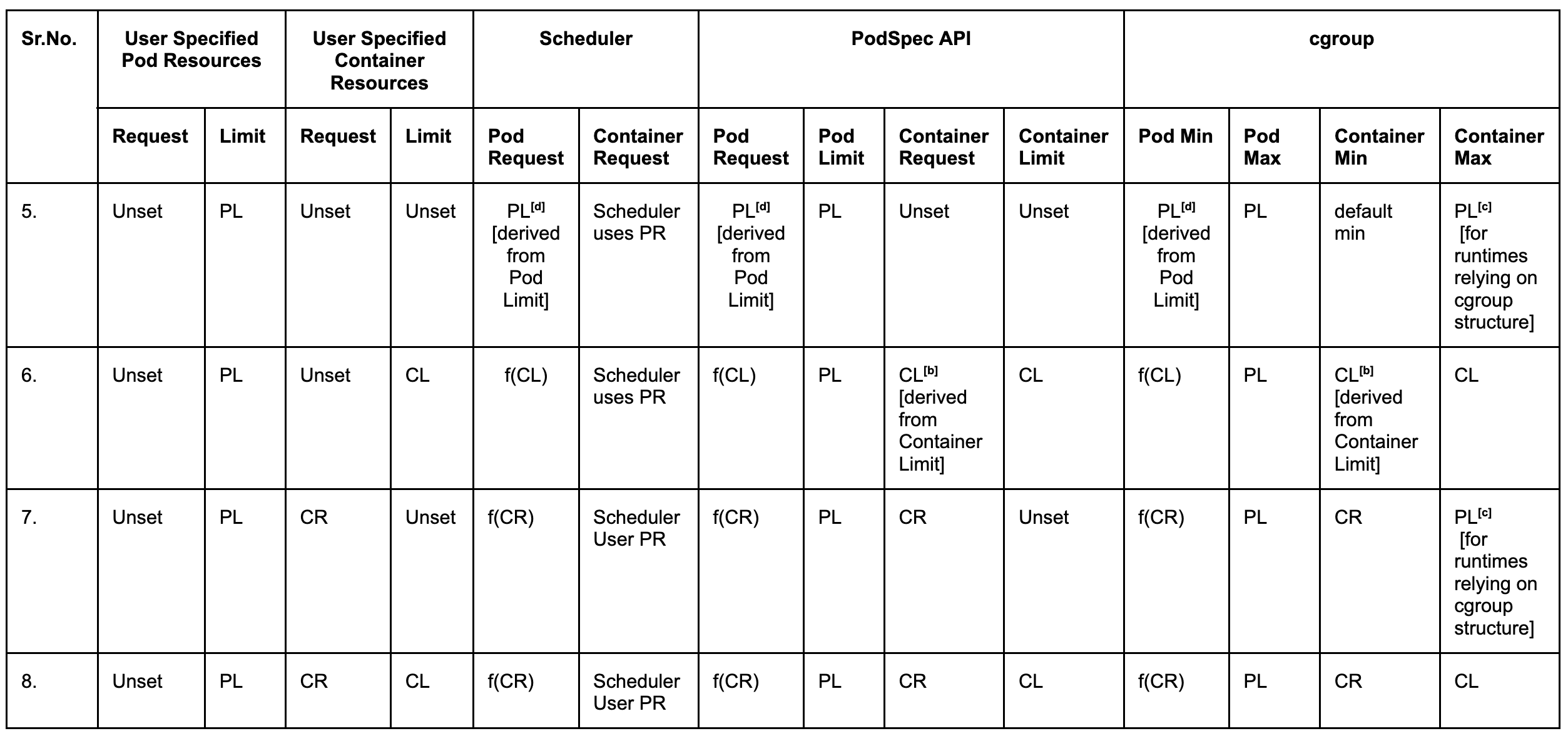
Row 5 Annotation [d]: When the pod-level request is not specified and cannot be inferred from the container-level request because container-level request is also unset, the pod-level request defaults to the limit.
Row 7 Annotation [c]: When container-level limit is not set, the pod-level limit is applied to each container’s cgroup maximum value. This is because container-level limit is implied in this case, and some runtimes (like the Java runtime) rely on container-level cgroup maximum values for fine tuning their components. This implied pod-level limit is not set in Pod spec.
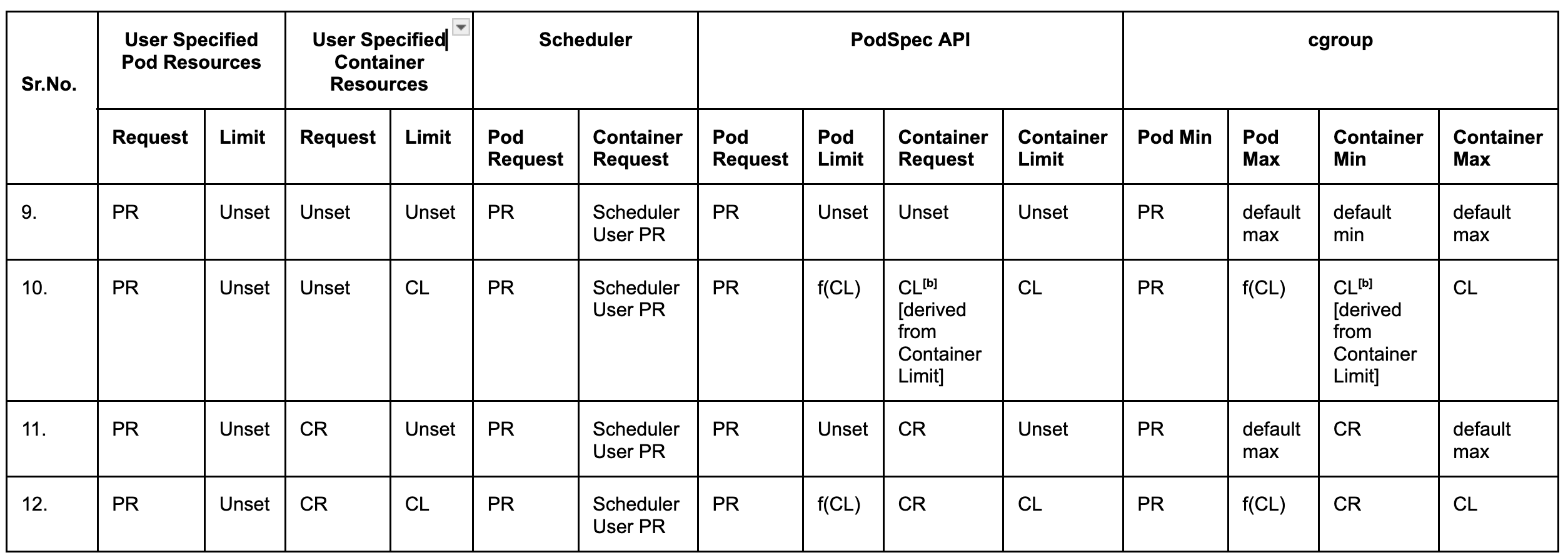
Rows 9 - 12
When the pod-level limit is unset, the value will be derived from container-level limits. If no pod-level limit is defined and not all the containers within the pod have explicitly limits set, then the containers in this pod will have access to an unknown amount of resources, up to the node allocatable capacity, but not less than their specified requests.
Row 10 Annotation [b]: For container level resources, if a request is not specified but a limit it set, the Pod Spec is modified to set the request equal to limit for each container. This modified Pod spec is then used by the scheduler, and also for configuring cgroup settings.
Rows 13 - 16
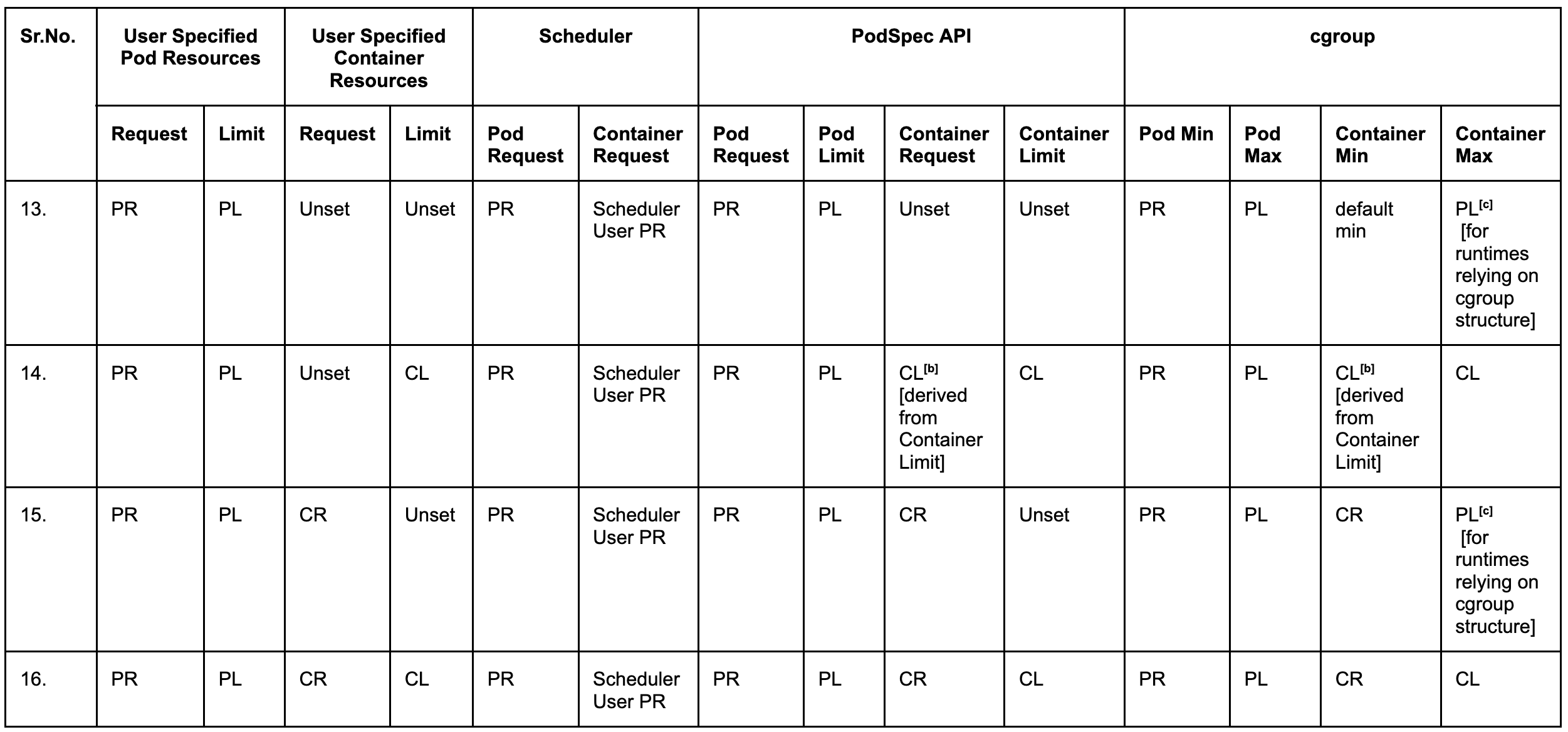
When both pod-level request and limit are explicitly specified,the scheduler and cgroups will use those values directly.
Rows 13, 15 Annotation [c]: When container-level limit is not set, the pod-level limit is applied to each container’s cgroup maximum value. This is because container-level limit is implied in this case, and some runtimes (like the Java runtime) rely on container-level cgroup maximum values for fine tuning their components.
Clarifying Tricky Cases and Design Decisions with Pod Level Resources
Row 5 from the scenarios table: Pod Limits Defined; Pod Requests & Container Specs Unspecified.
- Since container-level requests are not specified for at least one container, pod-level request cannot be derived from container-level requests.
- As pod-level limit is set, pod-level request defaults to pod-level limit in Pod Spec.
- For runtimes relying on cgroup structure, we set container-level limit equal to pod-level limit in cgroup configuration. These values are not set in Pod Spec.
Row 6 from the scenarios table: Pod Limits and Container Limits Defined, Pod Requests and Container Requests Unspecified.
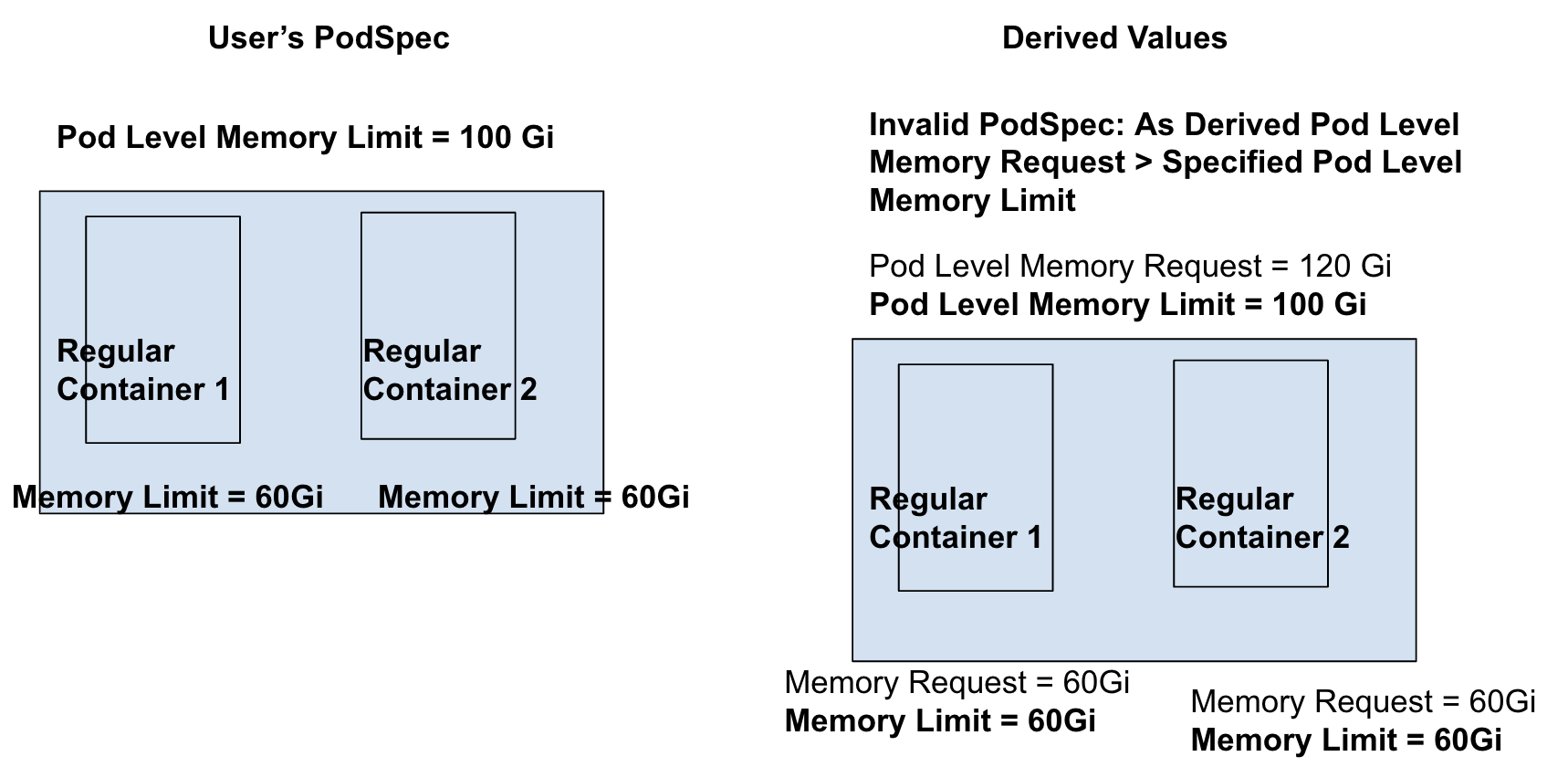
- As container-level limits are specified, container-level requests default to container-level limits, which means Container-level Request = 60 Gi for each container.
- Now as containers have requests, pod-level request can be derived from container-level requests using the formula from KEP#753 , which means Pod-level Request = 60 Gi + 60 Gi = 120 Gi.
- Pod-Level Request of 120Gi > Pod-Level Limit of 100 Gi which makes this PodSpec invalid.
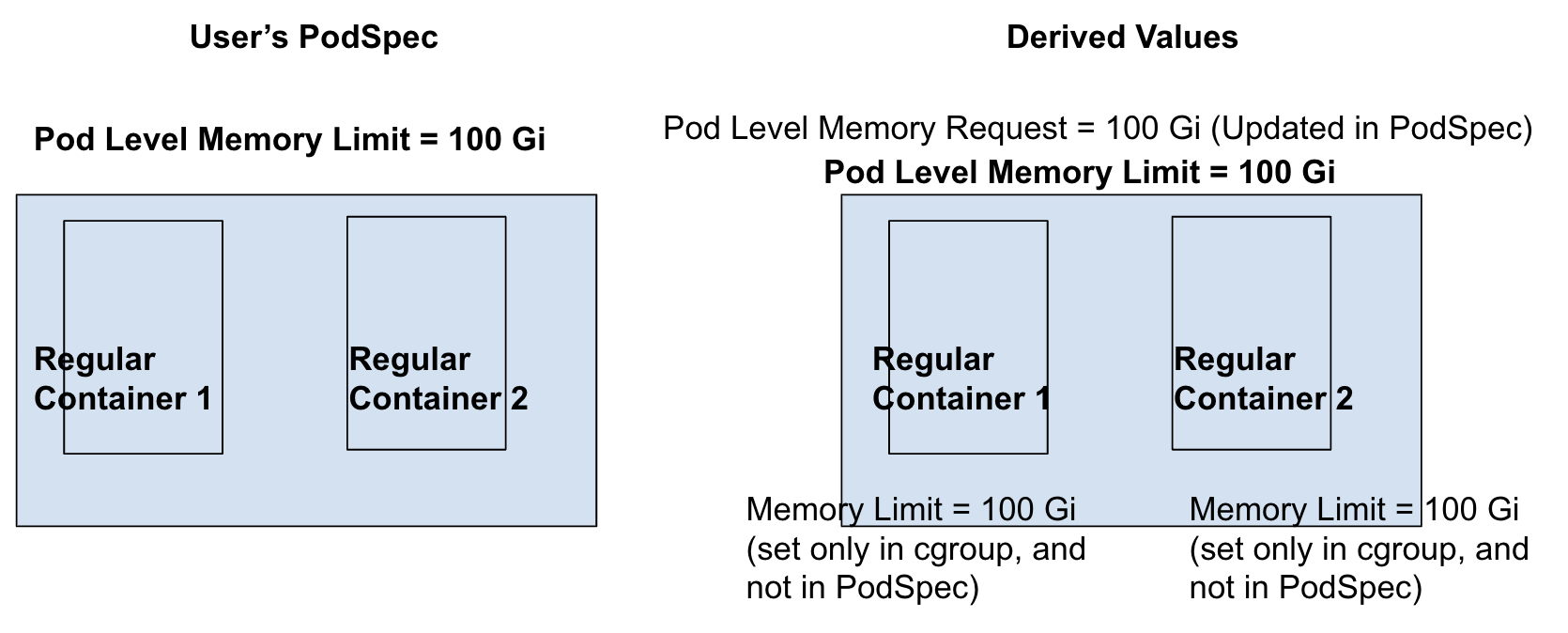
Row 7 from the scenarios table: Pod Limit is set; Container Requests are set for both regular containers.
Since container-level requests are set, Kubernetes can determine the pod-level request using the formula from KEP#753 . As both containers in the pod are regular containers, the pod-level request will be calculated as sum of container level request which is equal to 100Gi. This is set in Pod Spec.
Container-level limit will be set equal to pod-level limit only in cgroup settings (and not in PodSpec) for runtimes (or other softwares) relying on container-level cgroup values.
Pod-level Request is set, Pod-level limit is not set; Container-level Requests & Limits are not set.
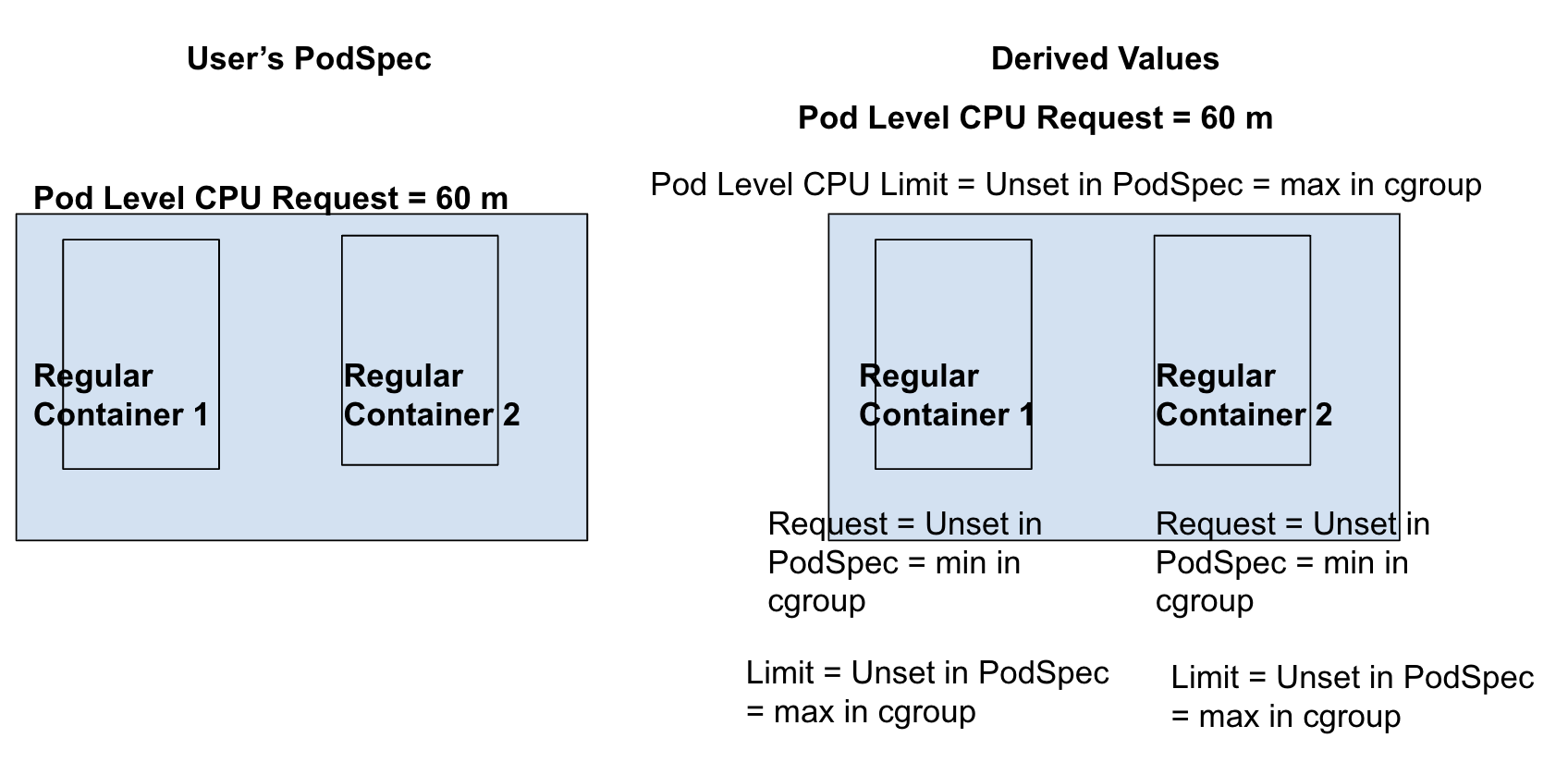
- Since container-level limits are not set for all containers, Kubernetes cannot determine pod-level limit from container-level values.
- As container-level limits are not set for all containers (only 1 container has limits specified) in this pod, there’s no way to derive pod-level limits. Consequently, the containers in this pod will have access to an unknown amount of resources, up to the node allocatable capacity, but not less than the total specified pod requests which guarantees minimum resources for both containers. This is facilitated by setting memory.max=max in the pod-level cgroup.
- As container-level requests and limits are not set, container level cgroup setting for cpu.weight defaults to 1 (minimum default weight) and cpu.max defaults to “max 100000” (maximum default value for cpu.weight).
Row 10 from scenaior table: Pod-level Request is set; Container-level limits are set for all containers.
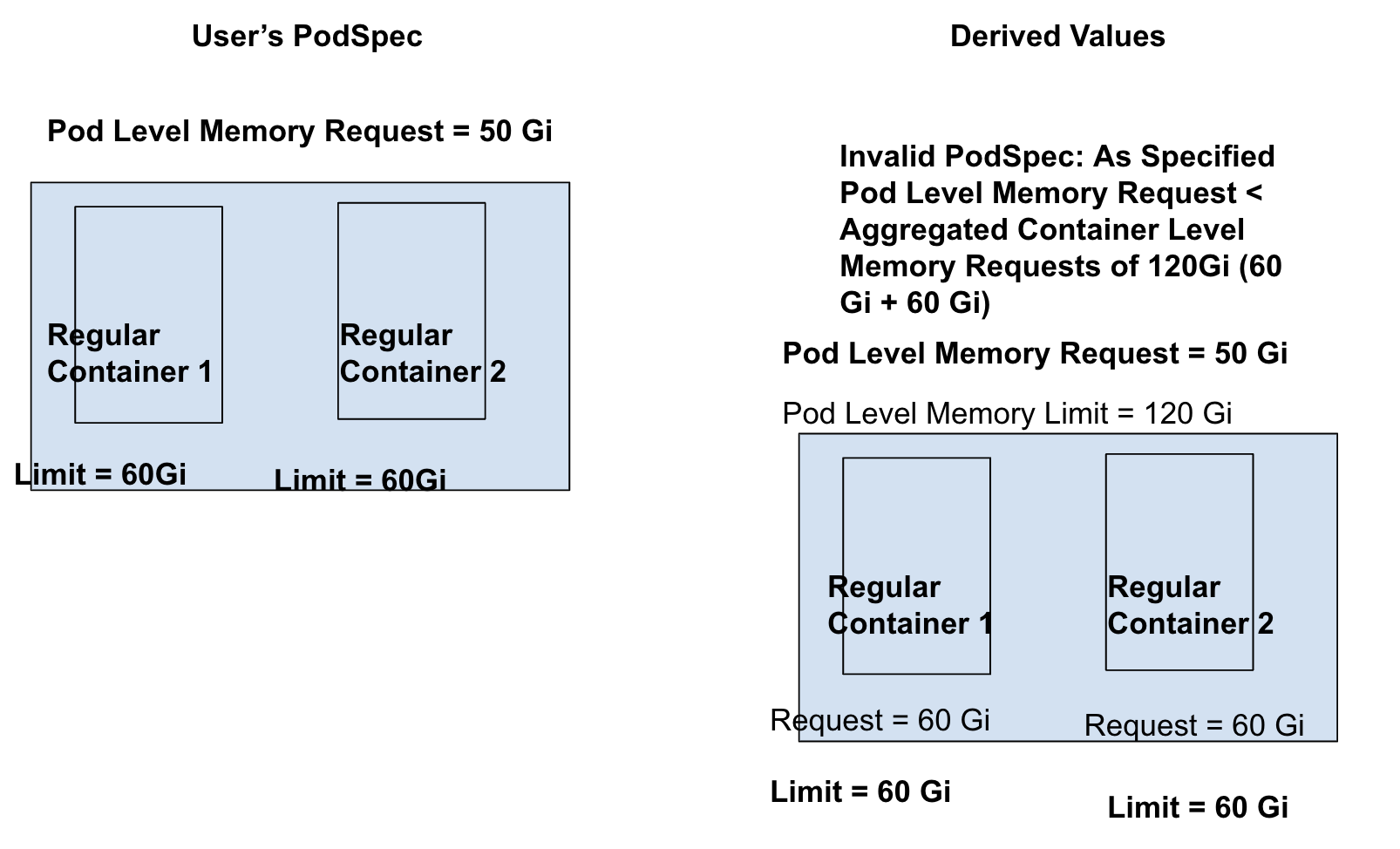
- As container-level limits are specified, container-level requests default to container-level limits, which means Container-level Request = 60 Gi for each container.
- Aggregated container-level requests = 60 Gi + 60 Gi = 120 Gi; Pod-level specified request is less than aggregated container-level requests which makes this pod invalid.
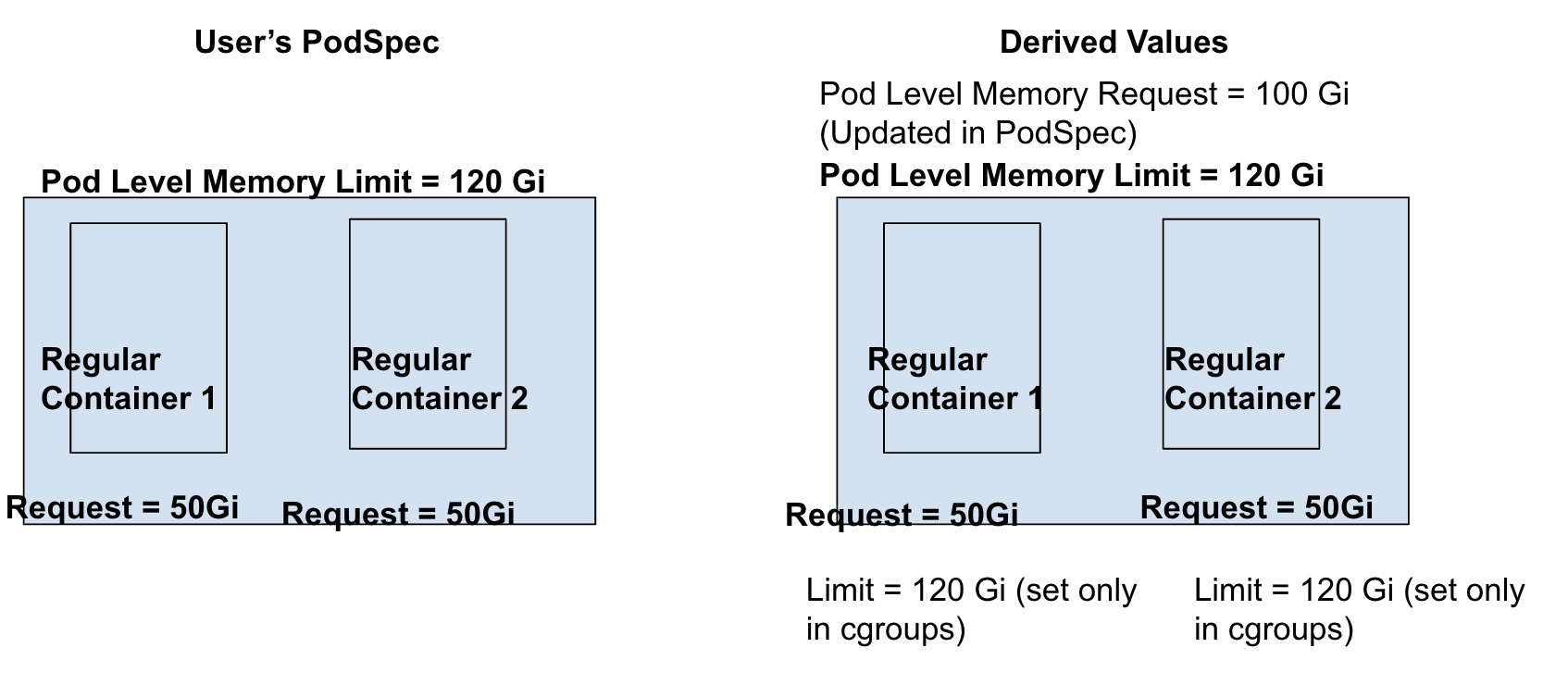
Pod-level Limit is set; Container Requests & Limits are set for 1 regular container.
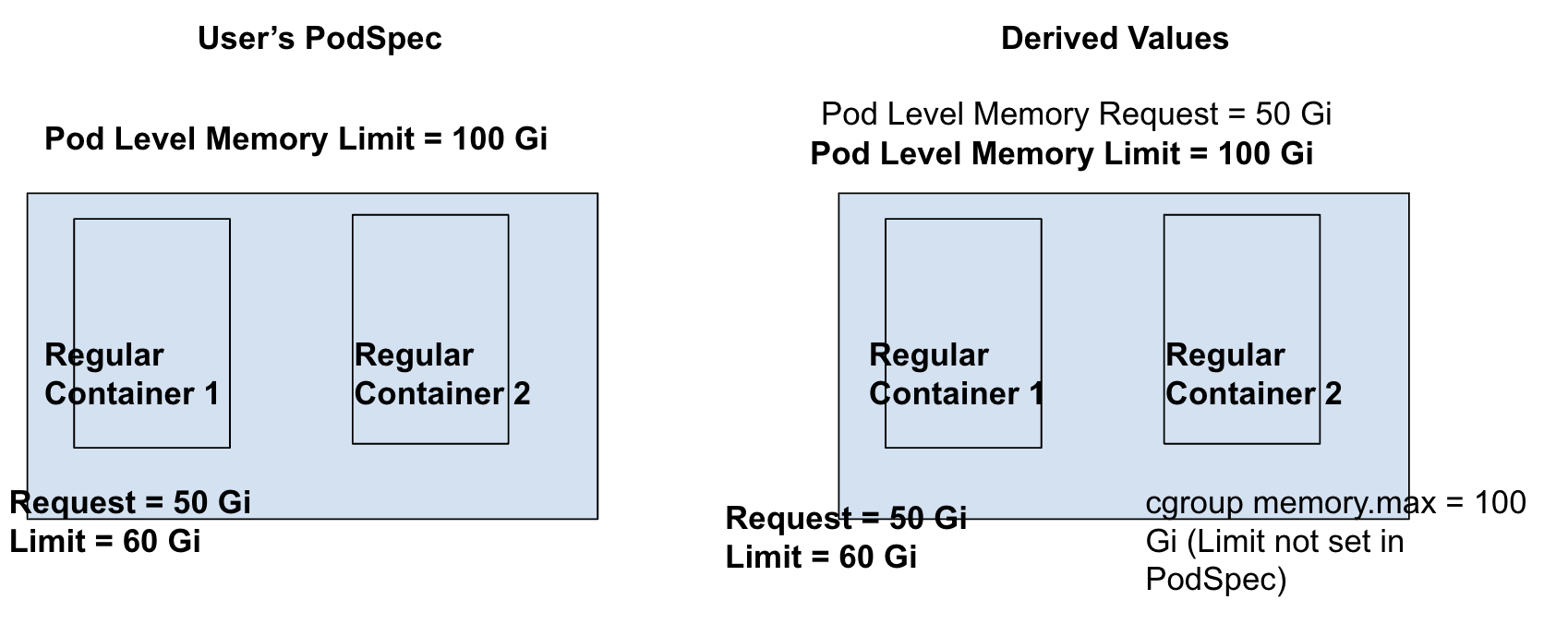
As container-level request is set for at least 1 container, pod-level requests can be derived from container-level requests, which makes pod-level request = 50 Gi.
Container-level limit for container 2 will be set equal to pod-level limit only in cgroup settings (and not in PodSpec) for runtimes (or other softwares) relying on container-level cgroup values.
Pod-level request is set; Container level limits set for 1 container.
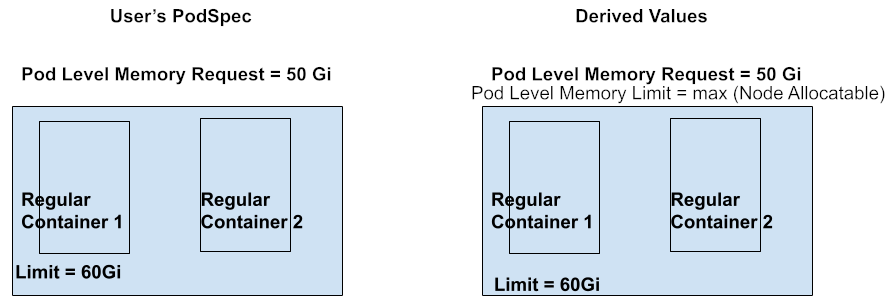
- As container-level limits are not set for all containers (only 1 container has limits specified) in this pod, there’s no way to derive pod-level limits. As a result, the containers in this pod will have access to an unknown amount of resources, up to the node allocatable capacity, but not less than their specified requests.
Pod-level request is set; Container-level spec is not set.
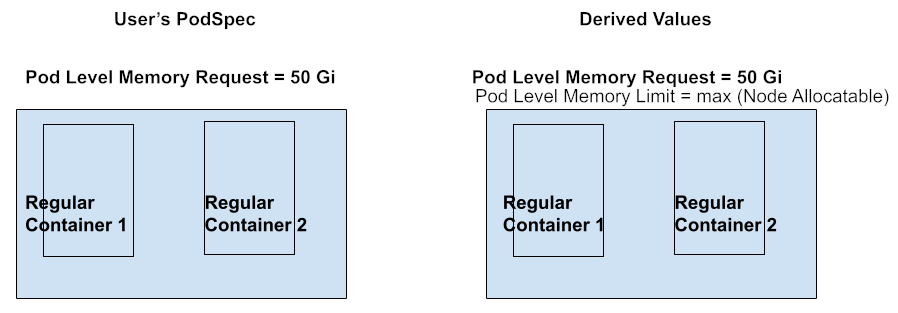
- As container-level limits are not set for all containers in this pod, there’s no way to derive pod-level limits. As a result, the containers in this pod will have access to an unknown amount of resources, up to the node allocatable capacity, but not less than their specified requests.
Pod-level limit is set, Container-level request is set for all containers.
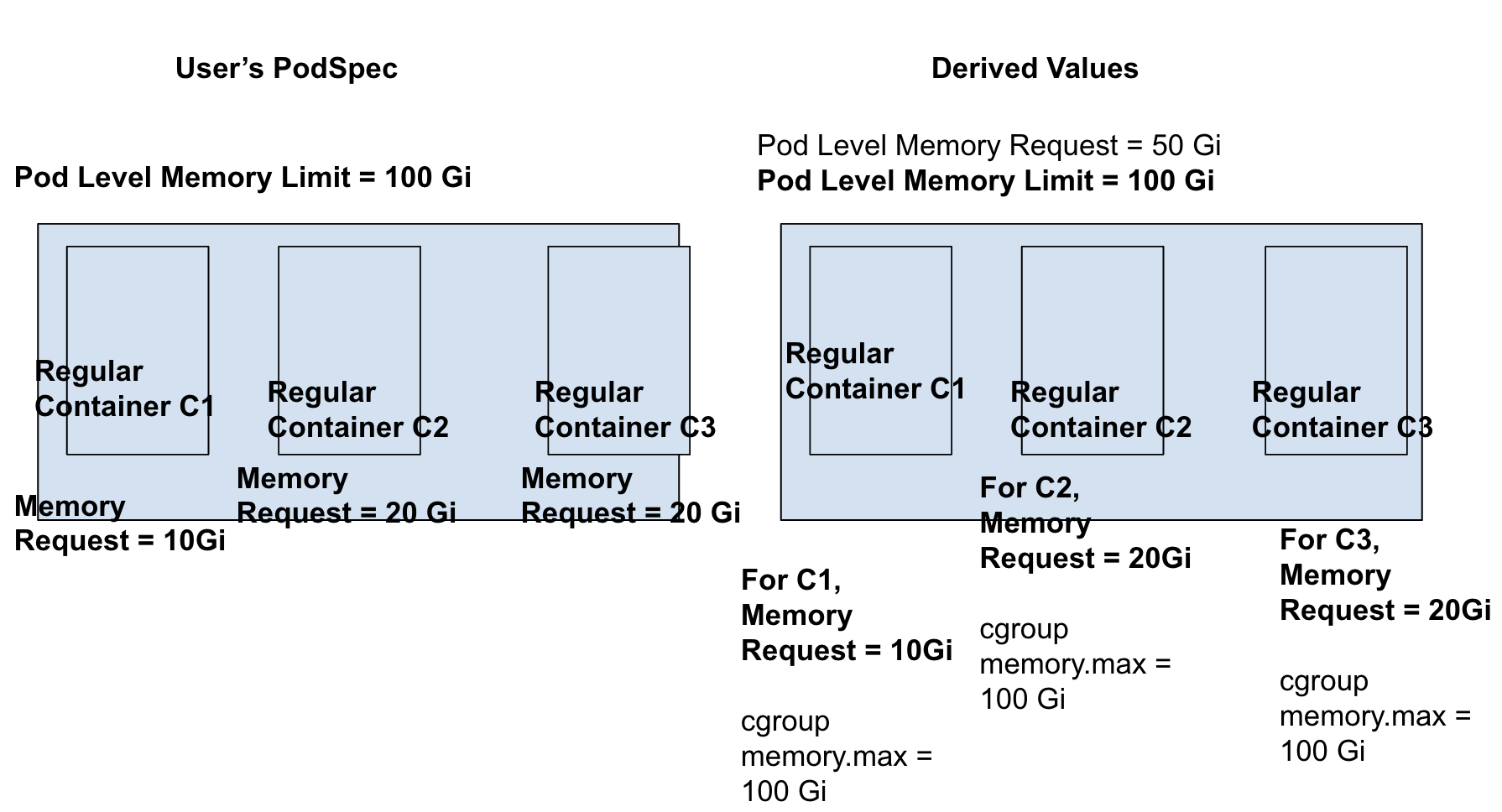
- AS container-level request are set, pod-level request can be derived from formula in KEP#753 . So pod-level request is equal = 10 Gi + 20 Gi + 20 Gi = 50 Gi.
- Container-level limit will be set equal to pod-level limit only in cgroup settings (and not in PodSpec) for runtimes (or other softwares) relying on container-level cgroup values.
Scheduler Changes
The scheduler will determine pod resources requirements in the following ways:
Directly from Pod-Level Resources (pod.spec.resources)
If the pod.spec.resources is defined, the scheduler will use the resource requests at the pod-level as the sole indicator of the pod’s resource needs. This includes the combined resource requirements of all containers within the pod, including init containers, sidecar containers, and regular containers.
Indirectly from Container-level Resources
If the pod.spec.resources is NOT defined, the scheduler will derive the pod’s resource needs by aggregating the requests and limits of all containers (init, sidecar and regular containers) within the pod.
Both Pod-level and Container level
If both pod-level and container-level resources are specified, the scheduler will prioritize the pod-level resources and ignore the container-level requests for node placement decisions.
Note: It is important to consider how this change will affect observability tools (like kube-state-metrics) that monitor and report on Kubernetes’ resource usage. To ensure these tools work correctly with pod-level resource specifications, these changes will be clearly documented to spread awareness around how these tools need to be updated before this feature is enabled by default in Beta.
To further aid in this transition, the Sig Scheduling community is working on developing PodRequests library function that these tools can use to accurately retrieve pod resource requests, taking into account both pod-level and container-level specifications. This effort is tracked in https://github.com/kubernetes/kubernetes/pull/124609
QoS Changes
With the addition of pod-level resource specifications, Kubernetes will prioritize those values when determining the Quality of Service (QoS) for a pod. Here’s the order of preference:
- Pod Level Resources: If the resources are specified at the pod level, Kubernetes will use those values to determine the QoS class.
- Container Level Resources: If pod-level resources are not specified, Kubernetes will fallback to the resources defined at the container level for QoS classification.
Essentially, pod-level resource specifications, when present, take precedence over container-level specifications in determining the QoS class of a pod.
For each core resource type (CPU, Memory), a pod may have pod-scoped resource request and/or limit. Pods which have a defined request or limit for a given resource are said to “have explicitly resourced” or “be explicitly resourced”. Pods which DO NOT have a defined request or limit for a given resource type are said to “have implicit resources” or “be implicitly resourced”
Guaranteed QoS
A pod is considered
Guaranteedif, for each resource type (CPU and memory), one of following conditions is true:It is explicitly resourced for that resource type AND the the pod’s request is equal to its limit.
[Unchanged Current Behavior] It is implicitly resourced for that resource type AND all containers’ requests are equal to their limits.
Note: If the pod spec includes
resourcesstanza at pod level, but either requests or limits are missing for a resource, the pod will not be considered Guaranteed QoS, even if container-level requests and limits are present and are equal.Burstable QoS Criteria
A pod is considered
Burstable, if for each resource type it doesn’t meet the criteria for Guaranteed QoS for that resource, and either of following is true:- It is explicitly resourced (pod.spec.resources is set) for that resource, AND pod request (less than or equal to limit) or limit is set.
- It is implicitly resourced for that resource AND for at least one container in the pod, request (less than or equal to limit) or limit is set.
BestEffort QoS Criteria
None of pod-level or container-level resources requests or limits are specified.
OOM Killer Behavior
OOM Score Adjustment
Kubernetes uses oom_score_adj value to influence which processes are more likely to be terminated by the OOM killer when a node faces memory constraints.
For Guaranteed and BestEffort pods, the oom_score_adj values remains unchanged. They retain their constant values of -997 and 1000, respectively. Thus ensures consistent behavior for these QoS classes, even with the introduction of pod-level resource specifications.
Currently, the oom_score_adj calculation for containers in Burstable pods only considers container-level memory requests:
$$ oomScoreAdjust = {1000 - \left[1000 \times {memoryRequest \over memoryCapacity }\right ]} $$
where:
- memoryRequest: Container-level memory request
- memoryCapacity: Node memory capacity
This approach creates issues with the introduction of pod level resources. If a pod only has pod level memory request and no container-level requests, the oom_score_adj will be high (~1000) for all the containers in the pod. This makes the processes in these containers to be unfairly targeted by the OOM Killer, even though the user has specified a pod-level request indicating a desire for some level of memory guarantee.
To address this, the KEP proposes a modified oom_score_adj formula for Burstable pods that considers both pod-level and container level memory requests.
$$ oomScoreAdjust = {1000 - \left[1000 \times {containerMemoryRequest + remainingPodMemRequestPerContainer \over memoryCapacity }\right ]} $$
where:
- containerMemoryRequest: Container-level memory request
- memoryCapacity: Node memory capacity
- remainingPodMemRequestPerContainer can be calculated as:
$$ remainingPodMemRequestPerContainer = {\left[PodRequest - \sum(containerMemoryRequests) \right] \over no. of containers} $$
Let’s understand the reasoning behind the new formula with examples.
Consider the following pods. Let’s assume the Node Memory Capacity is 1000 Gi.
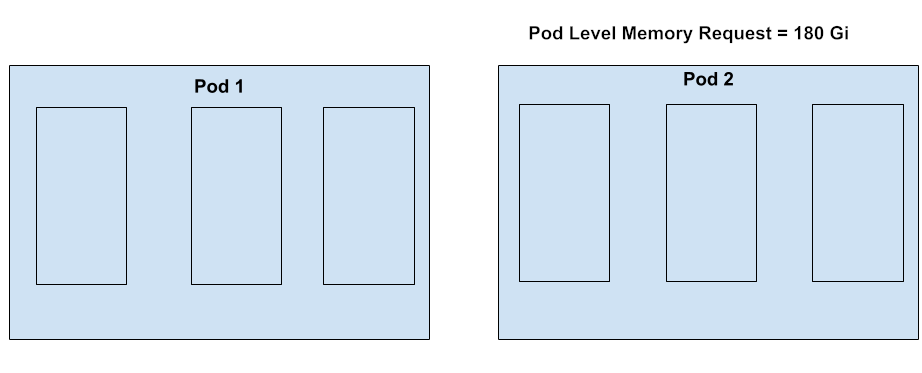
Using the existing formula, the oom_score_adj for all containers in both pods would be 1000.
$oomScoreAdjust _{current_formula} = 1000 - [1000 \times 0] / 1000 = 1000$
Pod 1 Pod 2 Container 1 1000 1000 Container 2 1000 1000 Container 3 1000 1000 This is problematic because it means that the containers in Pod 2, despite having a pod-level memory request, are treated the same as containers in Pod 1, which have no memory requests at all. This is unfair to Pod 2, as the user has explicitly requested a certain amount of memory at pod level, indicating some level of memory guarantee.
The new formula addresses this issue by considering both pod-level and container-level memory requests.
For Pod 2,
$remainingPodMemRequestPerContainer = {\left[PodRequest - \sum(containerMemoryRequests) \right] \over no. of containers} = {[180 - 0] / 3} = {60}$
$oomScoreAdjust _{proposed_formula} = {1000 - \left[1000 \times {containerMemoryRequest + remainingPodMemRequestPerContainer \over memoryCapacity }\right ]} = {1000 - [1000 \times {0 + 60 \over 1000}]} = 940$
Pod 1 Pod 2 Container 1 1000 940 Container 2 1000 940 Container 3 1000 940
The new formula assigns a lower oom_score_adj to the containers in Pod 2 than the containers in Pod 1, making them less likely to be killed by the OOM killer. This is a fairer approach as it reflects user’s intention to provide some level of memory guarantee to the pod.
Consider the following pods. Let’s assume the Node Memory Capacity is 1000 Gi.
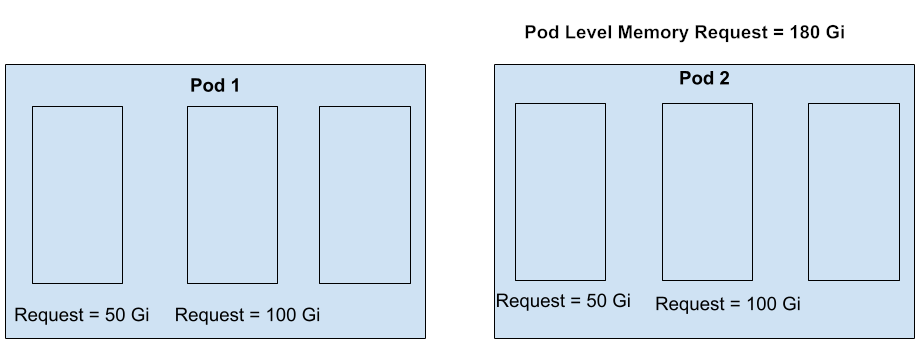
Using the existing formula, the oom_score_adj will be as following:
For Container 1 in both pods,
$oomScoreAdjust _{current_formula} = 1000 - [1000 \times 50] / 1000 = 950$
For Container 2 in both pods,
$oomScoreAdjust _{current_formula} = 1000 - [1000 \times 100] / 1000 = 900$
For Container 3 in both pods,
$oomScoreAdjust _{current_formula} = 1000 - [1000 \times 0] / 1000 = 1000$
Pod 1 Pod 2 Container 1 950 950 Container 2 900 900 Container 3 1000 1000 Container 3 in Pod 2 has same oom_score_adj as Container 3 in Pod 1, even though Pod 2 has a pod-level memory request indicating the user’s desire for some level of memory guaratee. This is unfair to Container 3 in Pod 2.
The new formula addresses this issue by considering both pod-level and container-level memory requests.
For Pod 2 Container 1,
$remainingPodMemRequestPerContainer = {\left[PodRequest - \sum(containerMemoryRequests) \right] \over no. of containers} = {[180 - 150] / 3} = {10}$
$oomScoreAdjust _{proposed_formula} = {1000 - \left[1000 \times {containerMemoryRequest + remainingPodMemRequestPerContainer \over memoryCapacity }\right ]} = {1000 - [1000 \times {50 + 10 \over 1000}]} = 940$
For Pod 2 Container 2,
$oomScoreAdjust _{proposed_formula} = {1000 - \left[1000 \times {containerMemoryRequest + remainingPodMemRequestPerContainer \over memoryCapacity }\right ]} = {1000 - [1000 \times {100 + 10 \over 1000}]} = 890$
For Pod 2 Container 3,
$oomScoreAdjust _{proposed_formula} = {1000 - \left[1000 \times {containerMemoryRequest + remainingPodMemRequestPerContainer \over memoryCapacity }\right ]} = {1000 - [1000 \times {0 + 10 \over 1000}]} = 990$
Pod 1 Pod 2 Container 1 950 940 Container 2 900 890 Container 3 1000 990
The new formula assigns lower oom_score_adj values to all containers in Pod 2 than the containers in Pod 1, making them less likely to be killed compared to Pod 1. The reasoning behind this intent is to reward the pods with explicit pod-level requests.
Also, this formula ensures that containers with explicit requests are prioritized over the containers with no requests set. In our example, within Pod 2, containers with explicit requests (Containers 1 & 2) have lower oom_score_adj values than Container 3 (no explicit request).
System Out-of-Memory (OOM) Kill
When a node is under memory pressure, if the kernel is not able to reclaim memory, the kernel will trigger OOM Killer. The OOM Killer prioritizes killing the processes with higher OOM scores. The new oom_score_adj formula, which considers both pod-level and container-level resources, helps the OOM Killer make fair and informed decisions about which processes to terminate.
cgroup Out-of-Memory (OOM) Kill
Previously, with only container-level resource limits, the cgroup OOM killer would be triggered if an individual container exceeded its own memory limit. Now, if only pod-level limits are specified, the cgroup OOM killer will be triggered when the combined memory usage of all the containers within a pod exceeds the pod-level memory limit.
Init Containers & Sidecar Containers
The current implementation (before this KEP) calculates the total effective resource requirements for a pod by aggregating the resource needs of Init containers, Sidecar containers and Regular containers. The calculation is detailed in the Sidecar containers KEP ).
Note: This section doesn’t factor in Pod Overhead when calculating pod level resource needs. Pod Overhead is considered to be added independently from resources specified in the Pod Spec by the kubelet.
With the addition of pod-level requests and limits, there are a few ways to determine a pod’s final resource allocation:
[Selected] Option 1: Pod Level Requests & Limits as an Override
With this option, the resource requests and limits the users sets at the pod level will directly determine the resource constraints applied to the pod’s cgroup. This means the pod’s overall resource usage, including all its containers, will be capped by the limits you define at the pod level, and the pod as a whole is guaranteed to receive at least the amount of resources requested at the pod level (minimum guarantees).
For example,
apiVersion: v1 kind: Pod spec: resources: requests: memory: 100Mi cpu: 1 limits: memory: 200Mi cpu: 2 initContainers: - name: init-container image: busybox ... containers: - name: container-1 ... - name: container-2 resources: requests: memory: 50Mi cpu: 1Resources requests at pod-level
- The Scheduler will use the requested resources (CPU and memory) settings specified at the pod level to find a node with enough available resources.
- The Kubelet will use the CPU request at the pod-level resources to set cpu.weight in pod-level cgroup.
Resources limits at pod-level
- All init(Regular and Sidecar) and non-init containers will be capped by the pod level limit which represents the combined peak usage of all containers.
- Kubelet will use CPU and memory limits from PodSpec to set cpu.max and memory.max cgroup settings at pod-level respectively.
Pros
- This approach is straightforward to understand and implement.
- It ensures enough resources are available for all containers. within the pod, collectively
Cons
This method can sometimes lead to potential over-provisioning (resource wastage), particularly when the init containers have significantly higher peak resource usage compared to the non-init containers. In this case, allocating resources based on the init container’s needs can result in unnecessary resource allocation for the application containers. However this can be mitigated by setting container level resource spec for application containers.
For example, if your init container needs 2 CPU cores and 512Mi of memory for a short burst during initialization, while your application container only requires 0.5 CPU cores and 256Mi of memory. You should set pod level requests and limits to 2 CPU and 512Mi of memory. Crucially, you could also set container level requests and limits for your app container (0.5 CPU and 256Mi). This prevents the application container from using the extra resources allocated to the pod, making the resources available for other workloads.
[Rejected]Option 2: Phased requests/limits - Pod-level cgroups are set after init containers are completed.
This option proposes a more dynamic approach where pod-level cgroup settings are applied after the completion of init containers. This requires specifying resource requests and limits for init containers at container level if the peak resource requirement/usage of init containers is higher than those of non-init containers (sidecar & regular containers). The resources spec set at pod level will account for all regular and sidecar containers (non-init containers).
For example,
apiVersion: v1
kind: Pod
spec:
resources:
requests:
memory: 100Mi
cpu: 2
limits:
memory: 200Mi
cpu: 3
initContainers:
- name: init-myservice
resources:
requests:
memory: 300Mi
cpu: 4
limits:
memory: 600Mi
cpu: 6
containers:
- name: container-1
resources:
requests:
memory: 50Mi
cpu: 1
limits:
memory: 100Mi
cpu: 2
- name: container-2
resources:
requests:
memory: 50Mi
cpu: 1
limits:
memory: 100Mi
cpu: 2
Resources requests at pod-level
The scheduler will use the higher of init and pod-level requests values to find the suitable node.
From the example above, the scheduler will use:
max(init container resources requests, pod-level resources requests)
= max (memory: 300Mi cpu: 4, memory: 100 Mi cpu: 2) = (memory: 300 Mi, cpu: 4) to find a suitable node.The init containers will rely on its own requests specified in the PodSpec.
After the init containers complete, kubelet will use the pod-level request to set cpu.weight in pod-level cgroup settings. (Currently, Kubernetes doesn’t directly map memory request to a specific cgroup settings)
Resources limits at pod-level
- The init containers will rely on their own limits specified in the PodSpec.
- After the init containers complete, kubelet uses CPU and memory limit at pod-level to set cpu.max and memory.max in the pod level cgroup.
Pros
- Reduces the problem of overprovisioning.
Cons
- Complicated to implement as it requires additional logic in kubelet to monitor init containers completion after which it will set/change pod level cgroup settings.
- Determining the QoS class for a pod becomes complicated with this approach. With this option, the QoS classification would need to consider both the init container’s requests and limits and the pod-level requests and limits. This could potentiall lead to a scenario where a pod’s QoS class changes dynamically based on its execution phase (whether it’s in initialization phase or in the phase after init containers are completed).
Note: Option 1 is a preferred design option as it is easier to implement, and also easier to understand from UX perspective. If there are enough supporting use cases for Option 2, we can explore the implementation in the beta phase of the KEP. Option 2 will also require discussions about dynamic QoS classes as per the execution phase of the pod (init vs non-init phase).
Ephemeral Containers
Currently, you can’t set resource limits (like CPU or memory) directly for ephemeral containers. They inherit the resource limits derived from the limits defined for other containers (regular, sidecars and init) in a pod. This behavior won’t change as a part of this KEP. Ephemeral containers will be capped by pod-level resource limits.
For further information on potential future changes, refer to the documentation on “scoped-for-beta-in-place-pod-resize”.
Admission Controller
LimitRange
LimitRange today supports objects of type
Container,PodandPersistentVolumeClaim. It allows following constraints:- min (this option is to specify min usage constraint on the resource)
- max (this option is to specify max usage constraints on the resource)
- defaultRequest (this option is to specify default resource request for the named resource)
- default (this option is to specify default limit for the named resource)
- maxLimitRequestRatio (represents the max burst value of the named resource)
default and defaultRequest are not supported by LimitRanger of type
Pod. To incorporate Pod level resource specifications, LimitRanger of typePodlogic will be extended with following changes:- Validation at Pod Admission will use pod resources from
resourcesstanza at pod level if it is set. - Extend
Podtype LimitRanger to supportdefaultRequestanddefaultto allow setting Pod level defaults.
Note: If there is an existing LimitRange of type Container in a namespace and a user creates a pod with pod-level resources only (without specifying container-level resources), Kubernetes will apply default container-level values based on the Container LimitRange. To avoid having the Container LimitRange applied to their workloads, the user should create pods in a different namespace where no Container LimitRange is set.
ResourceQuota
The ResourceQuota admission plugin will prioritize using pod-level resources if they are specified. If not, it will rely on container-level resources to determine the effective resource requests and limits for the pod.
The ResourceQuota Controller obtains the PodSpec directly from the Kubernetes API Server to monitor and track resource usage within a namespace. Therefore, if pod-level resources are specified, the ResourceQuota will use these pod-level resources from the PodSpec for both tracking and monitoring purposes.
Eviction Manager
For memory.available signal, the eviction manager checks the pod’s memory usage and compares it with memory requests at pod level to determine the pod eviction order. It aggregates the container-level memory requests to calculate the effective pod-level memory request. When pod-level memory requests are specified, the Eviction Manager should use the pod-level request directly instead of aggregating container-level requests. This logic should be modified to check if pod-level requests are set. If so, use the pod-level request; otherwise, fall back to aggregating container requests.
Pod Overhead
- Scheduling: The scheduler will consider the Pod Overhead in addition to pod-level resource requests (if specified) when selecting a node for the pod.
- Cgroup Sizing: The kubelet will include the Pod Overhead in determining the size of the pod’s cgroup. This means the pod cgroup’s resource limits will be set to accommodate both pod-level requests and pod overhead.
Hugepages
With the proposed changes, support for hugepages(with prefix hugepages-*) will be extended to the pod-level resources specifications, alongside CPU and memory. The hugetlb cgroup for the pod will then directly reflect the pod-level hugepage limits, if specified, rather than using an aggregated value from container limits. When scheduling, the scheduler will consider hugepage requests at the pod level to find nodes with enough available resources.
Containers will still need to mount an emptyDir volume to access the huge page filesystem (typically /dev/hugepages). This is the standard way for containers to interact with huge pages, and this will not change.
[Scoped for Beta in 1.36] Fix for pod-level limits default Logic (Issue 136120)
The PodLevelResourcesFixUpdateDefaulting feature gate (Beta in 1.36) addresses a bug in current defaulting logic which only implements defaulting for Pod-level requests. However, per the Rows 10 and 12 of the resource matrix, if Pod-level limits are unset but all containers have limits defined, the Pod-level limits should be defaulted to the sum of the container limits. This fix implements the missing logic to ensure consistency between the KEP and the implementation.
Note: PodLevelResourcesFixUpdateDefaulting feature gate is introduced in Beta stage
in 1.36 and is enabled by default. It is not recommended to disable this feature gate.
Turning it off creates a discrepancy between the expected resource model and the actual
defaulting behavior.
[Scoped for Beta in 1.36] Fix for Kubelet QoS Class Determination (Issue 135082)
The PodLevelResourcesFixKubeletQOSClass feature gate (Beta in 1.36) addresses a bug where ComputePodQOS incorrectly handles the distinction between nil and empty Pod Level Resources (PLRs). While most of the codebase correctly differentiates between them to determine if a pod has opted into pod-level resources, ComputePodQOS fails to do so consistently. This can lead to situations where a pod with container-level resources is misclassified as BestEffort because its (absent) pod-level resources are incorrectly interpreted. This fix ensures that pods are assigned the correct QoS class, maintaining expected eviction and scheduling priority behavior.
Note: PodLevelResourcesFixKubeletQOSClass feature gate is introduced in Beta stage
in 1.36 and is enabled by default. Disabling this feature is strongly discouraged, as it reverts
the system to a state where resource-heavy pods may be erroneously targeted for eviction.
[Scoped for Beta] Cluster Autoscaler
Cluster Autoscaler won’t work as expected with pod-level resources in alpha since it relies on container-level values to be specified. If a user specifies only pod-level resources, the CA will assume that the pod requires no resources since container-level values are not set. As a result, the CA won’t scale the number of nodes to accommodate this pod. Meanwhile, the scheduler will evaluate the pod-level resource requests but may be unable to find a suitable node to fit the pod. Consequently, the pod will not be scheduled. While this behavior is acceptable for the alpha implementation, it is anticipated that Cluster Autoscaler support will be addressed in the Beta phase with pod resource requirements surfaced in a helper library/function that autoscalers can use to make autoscaling decisions.
[Scoped for Beta] HPA
For accurate scaling decisions, HPA needs to be able to correctly calculate the resources requested by a pod, regardless of whether those requests are defined at the pod or container level. Currently, HPA calculates pod requests by simply aggregating the requests of all containers within a pod. To address this, HPA should leverage the helper method found at https://github.com/kubernetes/kubernetes/blob/988cf21f0975cf95444a619481c13d2503d8ec6a/staging/src/k8s.io/component-helpers/resource/helpers.go for more precise pod request computations. The changes are being worked on by sig-autoscaling: (#132237)[https://github.com/kubernetes/kubernetes/issues/132237]
To make HPA compatible with PodLevelResources, sig-autoscaling has proposed following changes:
For Resource type metrics
If pod-level requests are set: use pod level resources.
If pod-level requests are not set or the PodLevelResources feature flag is not enabled (fallback to the current behavior): compute pod-level resources by aggregating container-level resources. Throw an error if at least one container in the pod doesn’t set the resource requests.
For ContainerResource type metrics
- Do not change the existing behavior: try to read the target container resource request (regardless if pod-level resources are set or not). If the container request is not set, throw an error.
Note that we are not changing HPA behavior with respect to ContainerResource type metrics, because the user should have control over per-container utilization if they specify container requests. An use case for that is: user specifies pod requests and container request for only 1 container within that pod and configures HPA to scale based on that container’s resource utilization.
Cluster Autoscaler
The Cluster Autoscaler uses resourcehelper.PodRequests to calculate Pod resource requirements for scaling decisions in K8s version 1.33. This automatically includes Pod-level resource requests when the PodLevelResources feature gate is enabled, ensuring accurate node scaling and utilization calculations.
VPA
Collaboration with sig-autoscaling has been established to integrate support for VPA with Pod-level resources, slated for VPA 1.5.
The necessary changes include augmenting the recommendation algorithm to provide pod-level resource recommendations within RecommendedPodResources, in addition to existing per-container recommendations, when pod-level resources are set.
type RecommendedPodResources struct {
ContainerRecommendations []RecommendedContainerResources
// NEW: Pod-level resources
PodLevelResources *ResourceList
}
Note: Detailed KEP design is owned and being worked on by sig-autoscaling: #7571
Instrumentation
This section outlines the final list of metrics for the Pod-Level Resources feature, excluding Resource Manager extensions. These metrics are designed to provide deep observability into admission control, scheduling efficiency, and Kubelet-level execution.
Feature Adoption
These metrics track feature adoption, user intent, and validation friction within the control plane.
kubelet_pod_level_resources_admission_total
Total number of pods processed during Kubelet admission, categorized by resource configuration strategy.
Note: This metric is ALPHA and temporary. It is intended to track feature adoption while the feature is new and is scheduled to be removed 2-3 releases after the Pod-Level Resources feature reaches General Availability (GA).
Labels:
config_mode- Possible values:container_level,pod_level_only,pod_and_container_level.status- Possible values:admitted,rejected.qos_class- Possible values:guaranteed,burstable,best_effort.
This metric is recorded as a counter.
The Kubelet (Execution Phase)
Tracks operation failures and resource enforcement during the container lifecycle. Labels are kept low-cardinality to ensure node stability.
kubelet_oom_kills_total
Total number of OOM kills triggered. This generic metric uses labels to distinguish between pod-level and container-level events.
Labels:
scope- Possible values:pod(kills triggered specifically because the shared pod-level memory pool was exhausted),container(standard container-level OOM kills).resource- Alwaysmemory.
This metric is recorded as a counter.
kubelet_cpu_cfs_throttled_seconds_total
Total time in seconds that containers were throttled due to exceeding CPU limits.
Labels:
scope- Possible values:pod(throttling caused by the shared pod-level ceiling),container(throttling caused by an individual container’s limit).
This metric is recorded as a counter.
Kube-State-Metrics (KSM)
Exposed by the cluster-level state collector. This is the primary source for high-cardinality metadata used in observability joins.
kube_pod_level_resource_spec
Exposes the numeric values of the pod-level resources specified in the PodSpec.
Labels:
namespace: The namespace of the pod.pod: The name of the pod.uid: The Kubernetes UID of the pod.node: The node where the pod is running.resource: The resource type (cpu,memory).type: The spec type (request,limit).unit: The unit of measurement (core,bytes).
Regression Monitoring (Existing Metrics)
While not new, the following metrics must be monitored to ensure no regressions in scheduling or node stability occur after adopting pod-level resource specifications.
schedule_attempts_total{result="error|unschedulable"}: Monitored to detect spikes in unschedulable pods due to potential bugs in the new resource requirement calculation.node_collector_evictions_total: Monitored to ensure that the new pod eviction ranking logic based on pod-level requests behaves as expected and does not lead to an increase in unintended evictions.started_pods_errors_total/started_containers_errors_total: Monitored to detect failures in the Kubelet’s ability to create and configure the pod-level cgroups and container sandboxes.
Test Plan
[X] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Unit tests
This feature will touch multiple components. For alpha, unit tests coverage for following packages needs to be added:
- Scheduler logic will be updated to consider pod-level requests. Hence pkg/scheduler will require additional coverage.
- pkg/kubelet/cm will be updated to set pod-level cgroups using CPU requests and limits, and memory limits.
- pkg/apis/core/validation/types_test.go and pkg/apis/core/validation since new fields are added in PodSpec and also new validation rules are required for the new fields.
- pkg/kubeapiserver/admission for changes made in the admission logic for LimitRanger and ResourceQuota admission controllers.
k8s.io/kubernetes/pkg/kubelet/cm: 20250618 - 18.4
k8s.io/kubernetes/pkg/kubelet/kuberuntime: 20250618 - 69.1
k8s.io/kubernetes/pkg/scheduler/framework - 20250618 - 71.7
k8s.io/kubernetes/pkg/apis/core/validation - 20250618 - 84.7
Integration tests
e2e tests provide good test coverage of interactions between the new pod-level resource feature and existing Kubernetes components i.e. API server, kubelet, cgroup enforcement. We may replicate and/or move some of the E2E tests functionality into integration tests before GA using data from any issues we uncover that are not covered by planned and implemented tests.
e2e tests
- Cgroup settings when pod-level resources are set.
- Validate scheduling and admission.
- Validate the containers with no limits set are throttled on CPU when CPU usage reaches Pod level CPU limits.
- Validate the containers with no limits set are OOMKilled when memory usage reaches Pod level memory limits.
- Test the correct values in TotalResourcesRequested.
Graduation Criteria
Phase 1: Alpha (target 1.32)
- Feature is disabled by default. It is an opt-in feature which can be enabled by enabling the
PodLevelResourcesfeature gate and by setting the newresourcesfields in PodSpec at Pod level. - Support the basic functionality for scheduler to consider pod-level resource requests to find a suitable node.
- Support the basic functionality for kubelet to translate pod-level requests/limits to pod-level cgroup settings.
- Unit test coverage.
- E2E tests.
- Documentation mentioning high level design.
Phase 2: Beta (target 1.34)
- User Feedback.
- Feature is disabled by default. It is an opt-in feature which can be enabled by setting the new fields in PodSpec.
- Support for all features that are scoped out of alpha phase in the KEP design.
- Unit test coverage for additional features supported in Beta.
- E2E tests for additional features supported in Beta.
- Documentation update and blog post to announce feature in beta phase.
- Benchmark tests for resource usage with and without pod level resources for bursty workloads.
- Use kube_pod_container_resource_usage metric to check resource utilization.
- In-place pod resize support guarded behind a separate feature gate -
InPlacePodLevelResourcesVerticalScalingi.e. (Issue#5419)[https://github.com/kubernetes/enhancements/issues/5419] - Suggest Karpenter folks to use pod resource requests from k8s.io/component-helper or update https://github.com/kubernetes-sigs/karpenter/blob/v1.5.0/pkg/utils/resources/resources.go#L111-L144
- Resolve defaulting bugs via
PodLevelResourcesFixUpdateDefaultingfeature gate (Beta in 1.36). Issue 136120 - Resolve Kubelet QoS class determination bugs via
PodLevelResourcesFixKubeletQOSClassfeature gate (Beta in 1.36). Issue 135082
GA (stable)
- No major bugs reported for 3 months.
- Pod Level Resources Support With In Place Pod Vertical Scaling KEP is past alpha.
- User feedback (ideally from at least two distinct users) is green
- Resource Allocation Managers i.e. Topology, Memory and CPU managers support with Pod-level resources is past alpha.
Upgrade / Downgrade Strategy
Upgrade
API Server and Scheduler should be upgraded before the kubelet in that order.
The existing workloads will not have any impact specifically because of pod-level resources feature
since they won’t be using the new field resources in PodSpec at pod-level.
Downgrade
Kubelet should be downgraded before Scheduler and API server.
The existing workloads that don’t use pod-level resources won’t be affected by the downgrade. The existing pods using the new feature will still have the old pod-level cgroup settings which can lead to unpredictable resource allocation, and potentially cause issues with resource limits and enforcements. Hence it is recommended to drain the nodes and recreate the workloads with a clean slate.
Downgrade Steps:
- Disable the Feature Flag: Disabling the pod-level resource feature flag.
- Cordon Nodes: Cordon all the nodes to prevent new pods from being scheduled.
- Modify Workloads: This is the crucial step. Update your pod specifications to remove the pod-level resource fields and use container-level resources instead.
- Drain Nodes: Now you can safely drain nodes one by one. The evicted pods, with their updated configurations, will be scheduled on other nodes.
- Downgrade Kubelets.
- Downgrade Scheduler.
- Downgrade API Server.
- Uncordon nodes.
Version Skew Strategy
Pod-level resource specification is an opt-in feature. For this feature to work correctly, it must be enabled in all parts of the cluster (scheduler, API server, kubelet).
When the feature gate is disabled on control plane, but enabled on kubelet,
users will not be able to schedule Pods with the new resources field in the
spec.
When the feature gate is enabled on control plane, but disabled on kubelet, users
will be able to create the Pods with resources field, but kubelet will reject
those pods.
Therefore, all cluster nodes (controlplane and worker nodes), must be upgraded
before the user can deploy pods with the new resources field in the spec.
For users wanting to use this feature, it is user’s responsibility to use the correct version of kube-scheduler, kube-apiserver and kubelet otherwise the feature will not work as expected.
Production Readiness Review Questionnaire
Feature Enablement and Rollback
How can this feature be enabled / disabled in a live cluster?
Feature gate (also fill in values in
kep.yaml)- Feature gate name: PodLevelResources
- Components depending on the feature gate: kubelet, kube-apiserver, kube-scheduler
- Will enabling / disabling the feature require downtime of the control plane? No. Once the feature is disabled, the control plane components reject the pods with pod-level resources.
- Will enabling / disabling the feature require downtime or reprovisioning of a node? No. Once the feature is disabled, the kubelet rejects the pods with pod-level resources.
Feature gate (also fill in values in
kep.yaml)- Feature gate name: PodLevelResourcesFixKubeletQOSClass
- Components depending on the feature gate: kubelet
- Will enabling / disabling the feature require downtime of the control plane? No.
- Will enabling / disabling the feature require downtime or reprovisioning of a node? No. Once the feature is disabled, the kubelet will fallback to the old and erroneous logic of determining QOSClass. The feature gate is introduced in Beta stage in 1.36 and is enabled by default. While is not recommended to disable this feature gate as it resolves a critical bug, the gate allows administrators to revert to the previous behavior in the unlikely event that the fix introduces regressions in pod eviction or scheduling priorities within their specific environment. Disabling it is only recommended as a temporary troubleshooting step.
Feature gate (also fill in values in
kep.yaml)- Feature gate name: PodLevelResourcesFixUpdateDefaulting
- Components depending on the feature gate: kube-apiserver
- Will enabling / disabling the feature require downtime of the control
plane? No. Once the feature is disabled, the control plane would not set
the pod-level limits defaults when container-level limits are set for all
pods.
PodLevelResourcesFixUpdateDefaultingfeature gate is introduced in Beta stage in 1.36 and is enabled by default. While, it is not recommended to disable this feature gate, the gate allows administrators to revert to the previous behavior in the unlikely event that the fix introduces any regressions. - Will enabling / disabling the feature require downtime or reprovisioning of a node? No.
Does enabling the feature change any default behavior?
No. This feature is guarded by a feature gate, and requires setting Pod level
resource stanza explicitly. Existing default behavior does not change if the
feature is not used.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Yes. Any new pods created after disabling the feature will not utilize the pod-level resources feature. Disabling the feature will not affect existing pods not using pod-level resources feature – they will continue to function.
For pods that were created with pod-level resources, disabling the feature can result in a discrepancy between how different components calculate resource usage and the actual resource consumption of those workloads. For example, if a ResourceQuota object exists in a namespace with pods that were using pod-level resources, and then the feature is disabled, those existing pods will continue to run. However, the ResourceQuota controller will revert to using container-level resources instead of pod-level resources when calculating resource usage for these pods. This may lead to a temporary mismatch until the pods are recreated or the resource settings are updated.
Another scenario arises if the feature is disabled after a series of deployments have been admitted with only pod-level resources. In this case, the scheduler will interpret these pods as having the minimum implementation-defined resource requirements. As a result, these pods may be classified as BestEffort QoS pods, which means they are considered to have the lowest priority for resource allocation. Consequently, this classification could lead to scheduling issues, as the pods may be placed on nodes that lack sufficient resources for them to run effectively. This situation highlights the potential risks associated with toggling the feature gate after deployments are already in place, as it can affect pod scheduling and resource availability in the cluster.
To resolve this, users can delete the affected pods and recreate them.
What happens if we reenable the feature if it was previously rolled back?
Primary feature gate: PodLevelResources
If the feature is re-enabled after being previously disabled, any new pods will again have access to the pod-level resources feature.
Pods that were created but not yet started will be treated based on its resource spec (pod-level when feature gate is enabled, and container-level when the gate is disabled).
Pods that are already running with resources provisioned will continue running with resources provisioned at the time of execution (whether it was pod-level or container-level resources).
However, some components may calculate the resource usage of the pods based on the resource spec (pod-level when feature gate is enabled, and container-level when feature gata is disabled), and that may not necessarily match the actual resources provisioned for the running pod.
To ensure consistent and intuitive resource calculations, it is advisable to delete all pods when toggling the feature between enabling and disabling. This will help eliminate discrepancies and ensure that all pods operate under the same resource management scheme.
Bug-fix feature gates
PodLevelResourcesFixUpdateDefaulting: Corrects the defaulting logic for Pod-level limits. Re-enabling this ensures that Pods with container-level limits—but missing explicit Pod-level limits—are correctly assigned a defaulted Pod-level limit. This prevents “Limit-less” Pods that should have been constrained.
PodLevelResourcesFixKubeletQOSClass: Ensures the Kubelet correctly distinguishes between nil and empty Pod Level Resources. Re-enabling this prevents the critical misclassification of Pods as BestEffort.
Unlike the primary feature gate, re-enabling these feature gates primarily corrects the metadata and accounting logic. Re-enabling them is not disruptive to pod execution and is essential to restore the intended eviction priority behaviors in Kubernetes.
Are there any tests for feature enablement/disablement?
Yes, the tests will be added along with beta implementation.
- Validate that the users can set pod-level resources in the Pod spec only when the feature gate is enabled.
- Validate that scheduler considers pod level resources when the feature is enabled, and falls back to container level resources. when the feature is disabled.
- Validate the kubelet is using pod level resources in cgroup settings if the feature is enabled, and uses container level values when feature is disabled.
- Confirm that the API server gracefully ignores the pod-level resource fields and reverts to the existing container-level resource aggregation logic when the feature gate is disabled.
- Confirm Limit Ranger uses defaultRequest and limit when feature is enabled, and errors out for these values when feature is disabled.
Rollout, Upgrade and Rollback Planning
How can a rollout or rollback fail? Can it impact already running workloads?
Since the feature is opt-in feature and requires setting new fields in the PodSpec, the rollouts won’t likely fail because of this feature. For the new workloads that want to use this feature, there could be unexpected interactions with the existing features. This is why this feature will be rolled out in phases to make sure all the cases and interaction with existing features are covered before making it available in GA.
Rollbacks should be seamless if done after disabling the feature, and recreating the running workloads that use the feature.
What specific metrics should inform a rollback?
Any unusual observations in the following metrics should signal rollback:
kube_pod_container_resource_requests: This metric exposes the resource requests (CPU and memory) for each container within a pod.kube_pod_container_resource_limits: This metric exposes the resource limits (CPU and memory) for each container within a pod.node_collector_evictions_total: to check if a pod level resource setting is causing to evict more pods than normal.started_pods_errors_total: exposed by kubelet to check if large number of pods are failing unusually.started_containers_errors_total: exposed by kubelet to check if large number. of containers are failing unusuallyscheduler_pending_pods: Number of pending pods onunschedulablequeue to see number of pods scheduler failed to schedule.scheduler_pod_scheduling_attempts: Any spiked in number of attempts to schedule podsscheduler_schedule_attempts_total: Number of attempts to schedule pods.
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
Testing plan for Beta:
- Initial State: Old cluster version (i.e., 1.31) with PodLevelResources disabled.
- Create a test Pod with container-level resources
Upgrade Phase:
- Upgrade API server & then scheduler (control plane components) to 1.32 and enable the feature gate
- Expected outcome: Pods created before upgrade are still running as expected.
- Create a new test Pod with pod-level resources
- API server will identify the new pod-level resources
- Kubelet doesn’t set the pod-level cgroups correctly
- Delete this test pod
- Upgrade node to 1.32 and enable the feature gate
- Create a new test Pod with pod-level resources
- pod-level cgroups are set correctly
Downgrade Phase:
- Disable the feature gate on the nodes.
- verify that the pods created above with pod-level resources still have pod-level resources set.
- Cordon nodes.
- verify that the pods created above with pod-level resources still have pod-level resources set.
- Disable the feature gate on control plane components
- previous created pod objects should still have pod-level resources set in the object.
- attempt creating new pods with pod-level resources. API server will reject these pods
Re-upgrade Phase:
- Restart the API server with feature gate enabled
- Restart the kubelet with feature gate enabled
- verify the existing pods are running
- recreate these pods to see the pod-level cgroups set correctly
Validation of Bug-Fix Logic (FixUpdateDefaulting & FixKubeletQOSClass):
- Verify the upgrade path with feature FixUpdateDefaulting enabled: create a Pod with container-level limits but no Pod-level limits. The API server should automatically default the Pod-level limits to the sum of container.
- Verify the upgrade path with FixKubeletQOSClass enabled: create a pod with empty string values in pod-level resources requests and/or limits to ensure that the QOS class is set correctly.
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
No
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
Operators can use the kubelet_pod_level_resources_admission_total metric to track the adoption of this feature. This metric is categorized by resource configuration strategy (config_mode), admission status, and QoS class. Additionally, kube_pod_level_resource_spec (Kube-State-Metrics) can be used to identify specific pods using the feature and their configured resource values.
Note: This metric is ALPHA and temporary. It is intended to track feature adoption while the feature is new and is scheduled to be removed 2-3 releases after the Pod-Level Resources feature reaches General Availability (GA).
How can someone using this feature know that it is working for their instance?
- Other Field
- pod.status.spec.resources[x]
- Inspect Cgroup Filesystem: cgroup fs for the pod will reflect the requests/limits at pod level in cpu.weight, cpu.max, memory.max cgroup files.
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
Measure the overall resource utilization of the cluster with and without pod-level resources to ensure that the feature does not lead to significant over-provisioning or underutilization of resources.
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
kubelet_pod_level_resources_admission_total(ALPHA, Temporary): Total number of pods processed during Kubelet admission, categorized by resource configuration strategy. Scheduled for removal 2-3 releases after GA.kubelet_oom_kills_total: Total number of OOM kills triggered. Use labelscope="pod"to identify kills caused specifically by the shared pod-level limit.kubelet_cpu_cfs_throttled_seconds_total: Total time in seconds that containers were throttled. Use labelscope="pod"to identify throttling caused by the shared pod-level ceiling.kube_pod_level_resource_spec(Kube-State-Metrics): Exposes the numeric values of pod-level resources specified in the PodSpec.schedule_attempts_total{result="error|unschedulable"}node_collector_evictions_total: to check if a pod level resource setting is causing to evict more pods than normalstarted_pods_errors_total: exposed by kubelet to check if large number of pods are failing unusuallystarted_containers_errors_total: exposed by kubelet to check if large number of containers are failing unusually- Components exposing the metric: apiserver, kubelet, scheduler, kube-state-metrics
Are there any missing metrics that would be useful to have to improve observability of this feature?
No
Dependencies
Does this feature depend on any specific services running in the cluster?
No.
Scalability
Will enabling / using this feature result in any new API calls?
No. It only modifies existing API request/response payloads.
Will enabling / using this feature result in introducing new API types?
Yes, the PodSpec object will be modified to include new fields for pod level resources specifications i.e. pod.spec.resources.requests and pod.spec.resources.limit.
Will enabling / using this feature result in any new calls to the cloud provider?
No
Will enabling / using this feature result in increasing size or count of the existing API objects?
Negligible.
API type(s):
Estimated increase in size: (e.g., new annotation of size 32B) ~250B increase per pod
- v1.ResourceRequirements with cpu, memory, and hugepages-NGi for each requests and limits fields could lead to an increase in 2 * (3 * (15 (key type string) + 10(value type string))) = ~150B per pod
- v1.ResourceList could lead to an increase in 3 * (15+10) = ~75B
Estimated amount of new objects: (e.g., new Object X for every existing Pod)
- type PodStatus has 2 new fields of type v1.ResourceRequirements and v1.ResourceList
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
The computational overhead introduced in API server, scheduler and kubelet due to additional validation for pod level resource specifications should be negligible. Thorough testing and monitoring will ensure the SLIs/SLOs are not impacted.
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No. Pod-level resource information could lead to marginal increase in storage requirements for the new fields, although its impact is likely to be small compared to other Kubernetes object data.
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
Yes, it could.
Pod-level resource limits can enable higher pod density on a node, especially when containers within a pod don’t have simultaneous peak resource usage. This is because pod-level limits can more accurately reflect the pod’s overall resource needs, reducing over-provisioning compared to using only container-level limits. However, this increased density may also increase consumption of other resources like PIDs and network sockets.
This is however be mitigated by maxPods kubelet configuration that limits the number of pods on a node.
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
No dependency on etcd availability.
The scheduler relies on the API server to fetch pod specifications and node information. Without access to the API server, it cannot make informed scheduling decisions based on pod-level resource requests. This could lead to suboptimal placement.
What are other known failure modes?
What steps should be taken if SLOs are not being met to determine the problem?
It is suggested that if workloads with pod level resource specifications enabled cause performance or stability degradations, those workloads are recrated with only container level resource specs.
Implementation History
- 2020-03-17: Initial discussion in [SIG Node meeting] (https://www.youtube.com/watch?v=3cU56ZiUZ8w&list=PL69nYSiGNLP1wJPj5DYWXjiArF-MJ5fNG&index=101 )
- 2020-03-30: Initial KEP draft and discussion.
- 2021-07-26: Issue link
- 2024-05-31: Revised KEP for alpha (#4678)[https://github.com/kubernetes/enhancements/pull/4678]
- 2025-06-18: Revised KEP for Beta
- 2026-01-27: Revised KEP for 1.36 to include fixes for issues 135082 and 136120.
- 2026-06-08: Revised KEP for GA in 1.37.
Drawbacks
Alternatives
VPA
This KEP focusses on addressing the challenge of accurately assessing the container-level resource usage. VPA could be used as an alternative as it requires setting initial values for requests and limits, and then dynamically adjusts the values based on the actual usage. However, setting the initial values at container level is still required.
Furthermore, VPA introduces a delay in resource adjustments, as it needs time to gather and analyze usage data. This delay can be problematic for applications that experience sudden spike in resource usage demands. Additionally, there’s always a risk that VPA’s requested resource adjustments might be denied due to limited cluster resources.
Future Work
[Future KEP Consideration in 1.35] Support for Windows
Please note: This will be a separate KEP feature guarded by a feature gate.
Pod-level resource specifications are a natural extension of Kubernetes’ existing resource management model. Although this new feature is expected to function with Windows containers, careful testing and consideration are required due to platform-specific differences. As the introduction of pod-level resources is a major change in itself, full support for Windows will be addressed in future KEPs, beyond the scope of this KEP.
Until full Windows support for pod-level resource specifications is implemented, the behavior for pods, with pod-level resources, targeting Windows is as follows:
API Server Validation: If the spec.os.name field in the Pod specification is explicitly set to “windows”, the Kubernetes API server will generally reject the pod during validation.
Kubelet Admission: The Kubelet running on a Windows node would reject the pod, with pod-level resources, during admission.
[Future KEP Consideration in 1.35] Memory Manager
Please note: This will be a separate feature, as the required changes are not trivial and warrant further discussion. Until full support for the pod-level resources with Memory Manager is implemented, any guaranteed pod that requests pod-level integer memory resources will not receive memory alignment at the pod level. To ensure users are aware that their pod-level memory requests are not being aligned, this will be surfaced as a Kubernetes event. This event will inform you that pod-level resources are being ignored for memory alignment purposes.
The Memory Manager currently allocates memory resources at the container level through its Allocate method. The Topology Manager calls this Allocate method as part of its hint provider integration.
With the introduction of Pod Level Resources, the following modifications are needed:
Memory Manager Interface Extension: Add a new AllocatePodLevel method to the Memory Manager interface to handle resource allocation at the pod level. This method will complement the existing container-level Allocate method.
Topology Manager Integration: Modify the (Topology Manager)[https://github.com/kubernetes/kubernetes/blob/fd53f7292c7d5899135fddd928c0dc3844126820/pkg/kubelet/cm/topologymanager/scope.go#L150] to conditionally call AllocatePodLevel when pod-level resources are configured. Maintain backward compatibility by continuing to use the existing Allocate method for container-level allocation scenarios
[Future KEP Consideration in 1.35] CPU Manager
Please note: This will be a separate feature, as the required changes are not trivial and warrant further discussion. Until full support for the pod-level resources with CPU Manager is implemented, any guaranteed pod that requests pod-level integer CPU resources will not receive CPU alignment at the pod level. To ensure users are aware that their pod-level CPU requests are not being aligned, this will be surfaced as a Kubernetes event. This event will inform you that pod-level resources are being ignored for CPU alignment purposes.
The CPU Manager currently allocates CPUs at the container level through its Allocate method. The Topology Manager calls this Allocate method as part of its hint provider integration.
With the introduction of Pod Level Resources, the following modifications are required:
CPU Manager Interface Extension: Add a new AllocatePodLevel method to the CPU Manager interface to handle resource allocation at the pod level. This method will complement the existing container-level Allocate method.
Topology Manager Integration: Modify the (Topology Manager)[https://github.com/kubernetes/kubernetes/blob/fd53f7292c7d5899135fddd928c0dc3844126820/pkg/kubelet/cm/topologymanager/scope.go#L150] to conditionally call AllocatePodLevel when pod-level resources are configured. Backward compatibility will be maintained by continuing to use the existing Allocate method for container-level allocation scenarios.
Policy-Specific Modifications: Not all existing CPU Manager policies remain compatible with Pod Level Resources. Following are policy-specific adaptations:
distribute-cpus-across-numa: This policy is incompatible with pod-level resources. Distributing CPUs across NUMA nodes requires detailed knowledge of bandwidth-intensive containers, which is explicitly abstracted away by pod-level resources. Without workload-specific information, the system cannot optimally distribute containers across NUMA nodes, and incorrect placement could degrade performance (How to distribute M containers across N NUMA nodes).
distribute-cpus-across-cores: Similarly, this policy is incompatible. Users focused on core-level optimization for individual containers would likely not opt for pod-level resources in the first place.
full-pcpus-only: This policy is compatible and highly beneficial for multi-tenant pods requiring inter-pod isolation, as it helps prevent hyperthread contention. The CPU Manager will be extended to allocate full physical cores at the pod level and implement a shared CPU pool within pod boundaries.
align-by-socket: This policy is compatible. It ensures all a pod’s CPUs remain on the same socket when possible, reducing inter-socket latencies and benefiting containers that share L3 cache or communicate frequently. The socket alignment logic will be extended to work with pod-level CPU pools.
strict-cpu-reservation: This policy is compatible and crucial for guaranteed workloads, preventing interference from burstable and best-effort pods. We’ll update the CPU reservation logic to consider pod-level requests and limits.
prefer-align-cpus-by-uncorecache: This policy is compatible. It optimizes CPU allocation across uncore cache groups, enhancing shared cache locality for containers within the pod. The allocation logic will be updated to consider pod-level requests and limits.
Note: This is a preliminary analysis, and we might have real usecases to support distribute-cpus-across-numa and distribute-cpus-across-cores with pod-level resources. We can re-visit this again during the GA planning cycle.
[Future KEP Consideration in 1.35] Topology Manager
Please note: This will be a separate feature, as the required changes are not trivial and warrant further discussion. Until full support for the pod-level resources with Topology Manager is implemented, any guaranteed pod that requests pod-level integer resources will not receive topology alignment at the pod level. To ensure users are aware that their pod-level memory/cpu requests are not being aligned, this will be surfaced as a Kubernetes event. This event will inform you that pod-level resources are being ignored for topology alignment purposes.
Currently, scope=pod aggregates resource requirements from a pod’s individual containers to determine overall pod-level needs. With the introduction of Pod Level Resources, scope=pod will directly use the pod-level resource values specified in the Pod object for topology alignment.
Besides, scope=container won’t be supported for pods with Pod Level Resources. This is because these pods lack per-container resource specifications, leaving the Topology Manager without the granular information needed to make informed container-level topology decisions. If a user creates a guaranteed pod with pod-level resources and this pod gets scheduled on a node where the Kubelet’s Topology Manager is configured with scope=container, then the Topology Manager will not perform resource alignment for that pod, and will explicitly throw an error with an informative message.This message will guide the user to use scope=pod or to configure per-container resources if fine-grained container-level topology is truly desired.
[Future KEP Consideration in collaboration with sig-autoscaling] VPA
Pod-Level Resources allows pod-level limits to be greater than aggregated container limits to allow the containers to share idle resources among each other. Integrating this functionality with VPA necessitates the development of a complex new recommendation algorithm. Concepts such as proportionate pod and container level recommendations have been proposed and require further discussion.
[Scoped for GA] User Experience Survey
Before promoting the feature to GA, we plan to conduct a UX survey to understand user expectations for setting various combinations of requests and limits at both the pod and container levels. This will help us gather use cases for different combinations, enabling us to enhance the feature’s usability. If we identify the need for significant changes to the defaulting logic based on this feedback, we’ll release another Beta version of Pod-Level Resources to incorporate those adjustments.