KEP-2570: Memory QoS
KEP-2570: Support Memory QoS with cgroups v2
- Release Signoff Checklist
- Latest Update
- Summary
- Motivation
- Proposal
- Design Details
- Production Readiness Review Questionnaire
- Implementation History
- Drawbacks
- Alternatives
- Infrastructure Needed (Optional)
Release Signoff Checklist
- (R) Enhancement issue in release milestone, which links to KEP dir in [kubernetes/enhancements] (not the initial KEP PR)
- (R) KEP approvers have approved the KEP status as
implementable - (R) Design details are appropriately documented
- (R) Test plan is in place, giving consideration to SIG Architecture and SIG Testing input (including test refactors)
- (R) Graduation criteria is in place
- (R) Production readiness review completed
- (R) Production readiness review approved
- “Implementation History” section is up-to-date for milestone
- User-facing documentation has been created in [kubernetes/website], for publication to [kubernetes.io]
- Supporting documentation—e.g., additional design documents, links to mailing list discussions/SIG meetings, relevant PRs/issues, release notes
Latest Update
Targeting Beta in v1.37. Rollback cleanup is now fully implemented. Cgroup v2 memory knobs (memory.min, memory.low, memory.high) are properly cleared when the MemoryQoS feature gate is disabled. Node e2e tests cover memory protection, throttling, and rollback cleanup. Benchmark testing validates memory.high throttle behavior, tiered memory protection, and rollback safety. See Beta v1.37
for details.
Previous Status (v1.36)
v1.36 shipped as Alpha v3 rather than Beta based on PRR feedback:
New KubeletConfiguration field requires Alpha iteration: Adding
memoryReservationPolicyto KubeletConfiguration is an API-level change. Per Kubernetes policy, features adding API fields must start in Alpha. This field provides independent control overmemory.minprotection, addressing concerns about validating memory.min behavior separately.memory.min stability concerns need benchmark validation: Mapping
requests.memorytomemory.mincould impact node stability under memory pressure if too much memory is protected for pods. The design mitigates this by also settingmemory.minfor kube-reserved and system-reserved cgroups when--enforce-node-allocatableis configured. The scheduler ensuressum(requests) ≤ allocatable, and the kernel invokes OOM killer (not hang) whenmemory.mincannot be satisfied. Benchmark testing under sustained memory pressure is needed to validate this before Beta.Scope consolidation: The Alpha v3 iteration adds
memoryReservationPolicyfor independent memory reservation control, new observability metrics, a kernel version check to mitigate livelock issues, and documented failure modes—addressing the gaps identified since the v1.28 Beta attempt was cancelled.
Previous Status (v1.28)
Work on Memory QoS was paused after issues were uncovered during the Beta promotion process in v1.28. This section documents the lessons learned from that experience. Note: Kubernetes 1.28 did not receive the Beta promotion.
Initial Plan: Use cgroup v2 memory.high knob to set memory throttling limit. As per the initial understanding,
setting memory.high would have caused memory allocation to be slowed down once the memory usage level in the containers
reached memory.high level. When memory usage goes beyond memory.max, kernel will trigger OOM Kill.
Actual Finding: According to the test results , it was observed that for a container process trying to allocate large chunks of memory, once the memory.high level is reached, it doesn’t progress further and stays stuck indefinitely. Upon investigating further, it was observed that when memory usage within a cgroup reaches the memory.high level, the kernel initiates memory reclaim as expected. However, the process gets stuck because its memory consumption rate is faster than what the memory reclaim can recover. This creates a livelock situation where the process rapidly consumes the memory reclaimed by the kernel causing the memory usage to reach memory.high level again, leading to another round of memory reclamation by the kernel. By increasingly slowing growth in memory usage, it becomes harder and harder for workloads to reach the memory.max intervention point. (Ref: https://lkml.org/lkml/2023/6/1/1300 )
Note: The original plan suggested using PSI with memory.high to implement userspace OOM policies. With the kernel 5.9+ fix preventing livelock, this is no longer required. PSI metrics are used only for memory throttling debugging and observability. See Monitoring Requirements for the updated approach.
Summary
This KEP introduces Memory Quality of Service (QoS) support for Kubernetes using cgroups v2 memory controller features. It maps pod memory requests to memory.min (guaranteed memory protection from reclaim) and calculates memory.high (throttling threshold) based on a configurable throttling factor. This enables better memory isolation and protection for containerized workloads.
Motivation
In traditional cgroups v1 implementation in Kubernetes, we can only limit CPU resources, such as cpu_shares / cpu_set / cpu_quota / cpu_period, memory QoS has not been implemented yet. cgroups v2 brings new capabilities for memory controller and it would help Kubernetes enhance memory isolation quality.
Goals
- Provide guarantees around memory availability for pod and container memory requests and limits
- Provide guarantees around memory availability for node resource
- Make use of new cgroup v2 memory knobs (
memory.min/memory.low/memory.high) for pod and container level cgroup - Make use of new cgroup v2 memory knobs (
memory.min) for node level cgroup
Non-Goals
- Additional QoS design
- Support other resources QoS
- Consider QOSReserved feature
Proposal
This proposal uses memory controller of cgroups v2 to support memory qos for guaranteeing pod/container memory requests/limits and node resource.
Currently we only use memory.limit_in_bytes=sum(pod.spec.containers.resources.limits[memory]) with cgroups v1 and memory.max=sum(pod.spec.containers.resources.limits[memory]) with cgroups v2 to limit memory usage. resources.requests[memory] is not yet used by either cgroups v1 or cgroups v2 to protect memory requests. About memory protection, we use oom_scores to determine the order of killing container processes when OOM occurs. Besides, kubelet can only reserve memory from node allocatable at node level, there is no other memory protection for node resources.
So some memory protection is missing, which may cause:
- Pod/Container memory requests can’t be fully reserved, page cache is at risk of being recycled
- Pod/Container memory allocation is not well protected, and allocation latency may occur frequently when node memory nearly runs out
- Memory overcommit of container is not throttled, which may increase the risk of node memory pressure
- Memory resource of node can’t be fully retained and protected
Cgroups v2 introduces a better way to protect and guarantee memory quality.
| File | Description |
|---|---|
| memory.min | memory.min specifies a minimum amount of memory the cgroup must always retain, i.e., memory that can never be reclaimed by the system. This protects the cgroup’s memory from reclaim pressure. If the system cannot free enough memory because too much is protected by memory.min across cgroups, the OOM killer will be invoked. We map it to requests.memory for Guaranteed pods. Burstable pods use memory.low instead (see below). |
| memory.max | memory.max is the memory usage hard limit, acting as the final protection mechanism: If a cgroup’s memory usage reaches this limit and can’t be reduced, the system OOM killer is invoked on the cgroup. Under certain circumstances, usage may go over the memory.high limit temporarily. When the high limit is used and monitored properly, memory.max serves mainly to provide the final safety net. The default is max. We map it to limits.memory as consistent with existing memory.limit_in_bytes for cgroups v1. |
| memory.low | memory.low is the best-effort memory protection, a “soft guarantee” that if the cgroup and all its descendants are below this threshold, the cgroup’s memory won’t be reclaimed unless memory can’t be reclaimed from any unprotected cgroups. In Alpha v1.36, this is used for Burstable pod/container request protection. |
| memory.high | memory.high is the memory usage throttle limit. This is the main mechanism to control a cgroup’s memory use. If a cgroup’s memory use goes over the high boundary specified here, the cgroup’s processes are throttled and put under heavy reclaim pressure. The default is max, meaning there is no limit. We use a formula to calculate memory.high depending on limits.memory/node allocatable memory and a memory throttling factor. |
This proposal uses requests.memory for memory request protection. In Alpha v1.36, for Guaranteed pods/containers, requests.memory is set to memory.min, and for Burstable pods/containers, requests.memory is set to memory.low. limits.memory is set to memory.max (this is consistent with existing memory.limit_in_bytes for cgroups v1, we do nothing because cgroup_v2
has implemented for that).
We also introduce memory.high for container cgroup to throttle container memory overcommit allocation.
Note: memory.high is set for container-level cgroup, and not for pod-level cgroup. If a container in a pod sees a spike in memory usage, it could result in total pod-level memory usage to reach memory.high level set at pod-level cgroup. This will induce throttling in other containers as the pod-level memory.high was hit. Hence to avoid containers from affecting each other, we set memory.high for only container-level cgroup.
Alpha v1.22
It is based on a formula:
memory.high=(limits.memory or node allocatable memory) * memory throttling factor,
where default value of memory throttling factor is set to 0.8
e.g. If a container has requests.memory=50, limits.memory=100, and we have a throttling factor of .8, memory.high would be 80. If a container has no memory limit specified, we substitute limits.memory for node allocatable memory and apply the throttling factor of .8 to that value.
It must be ensured that memory.high is always greater than memory.min.
Node reserved resources(kube-reserved/system-reserved) are also considered. It is tied to --enforce-node-allocatable and memory.min will be set properly.
Brief map as follows:
| type | memory.min | memory.high |
|---|---|---|
| container | requests.memory | limits.memory/node allocatable memory * memory throttling factor |
| pod | sum(requests.memory) | N/A |
| node | pods, kube-reserved, system-reserved | N/A |
Alpha v1.27
The formula for memory.high for container cgroup is modified in Alpha stage of the feature in K8s v1.27. It will be set based on formula:
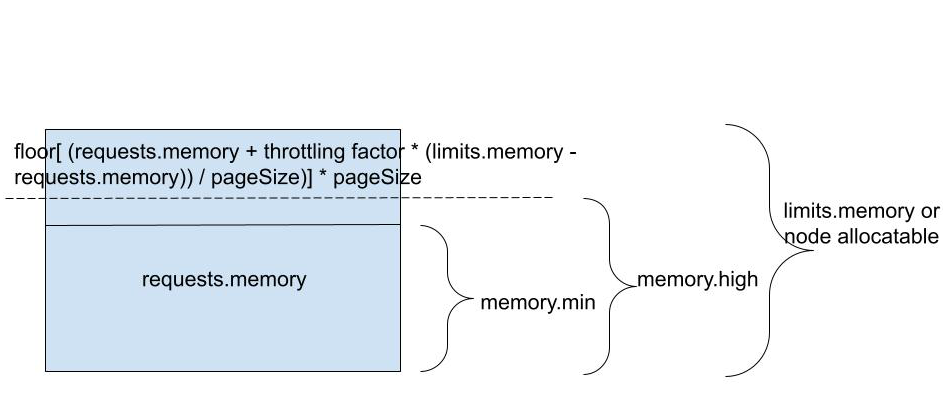
memory.high=floor[(requests.memory + memory throttling factor * (limits.memory or node allocatable memory - requests.memory))/pageSize] * pageSize, where default value of memory throttling factor is set to 0.9
Note: If a container has no memory limit specified, we substitute limits.memory for node allocatable memory and apply the throttling factor of .9 to that value.
The table below runs over the examples with different values requests.memory and 1Mi pageSize:
| limits.memory (1000) | memory throttling factor (0.9) |
|---|---|
| request 0 | 900 |
| request 100 | 910 |
| request 200 | 920 |
| request 300 | 930 |
| request 400 | 940 |
| request 500 | 950 |
| request 600 | 960 |
| request 700 | 970 |
| request 800 | 980 |
| request 900 | 990 |
| request 1000 | 1000 |
Node reserved resources(kube-reserved/system-reserved) are also considered. It is tied to --enforce-node-allocatable and memory.min will be set properly.
Brief map as follows:
| type | memory.min | memory.high |
|---|---|---|
| container | requests.memory | floor[(requests.memory + memory throttling factor * (limits.memory or node allocatable memory - requests.memory))/pageSize] * pageSize |
| pod | sum(requests.memory) | N/A |
| node | pods, kube-reserved, system-reserved | N/A |
Reasons for changing the formula of memory.high calculation in Alpha v1.27
The formula for memory.high has changed in K8s v1.27 as the Alpha v1.22 implementation has following problems:
It fails to throttle when requested memory is closer to memory limits (or node allocatable) as it results in memory.high being less than requests.memory.
For example, if
requests.memory = 85, limits.memory=100, and we have a throttling factor of 0.8, then as per the Alpha implementation memory.high = memory throttling factor * limits.memory i.e. memory.high = 80. In this case the level at which throttling is supposed to occur i.e. memory.high is less than requests.memory. Hence there won’t be any throttling as the Alpha v1.22 implementation doesn’t allow memory.high to be less than requested memory.It could result in early throttling putting the processes under early heavy reclaim pressure.
For example,
requests.memory= 800Mimemory throttling factor= 0.8limits.memory= 1000MiAs per Alpha v1.22 implementation,
memory.high= memory throttling factor * limits.memory = 0.8 * 1000Mi = 800MiThis results in early throttling and puts the processes under heavy reclaim pressure at 800Mi memory usage levels. There’s a significant difference of 200Mi between the memory throttling limit (800Mi) and memory usage hard limit (1000Mi).
requests.memory= 500Mimemory throttling factor= 0.6limits.memory= 1000MiAs per Alpha v1.22 implementation,
memory.high= memory throttling factor * limits.memory = 0.6 * 1000Mi = 600MiThrottling occurs at 600Mi which is just 100Mi over the requested memory. There’s a significant difference of 400Mi between the memory throttle limit (600Mi) and memory usage hard limit (1000Mi).
Default throttling factor of 0.8 may be too aggressive for some applications that are latency sensitive and always use memory close to memory limits.
For example, there are some known Java workloads that use 85% of the memory will start to get throttled once this feature is enabled by default. Hence the default 0.8 memoryThrottlingFactor value may not be a good value for many applications due to inducing throttling too early.
Some more examples to compare memory.high using Alpha v1.22 and Alpha v1.27 are listed below:
| Limit 1000Mi Request, factor | Alpha v1.22: memory.high = memory throttling factor * memory.limit (or node allocatable if memory.limit is not set) | Alpha v1.27: memory.high = floor[(requests.memory + memory throttling factor * (limits.memory or node allocatable memory - requests.memory))/pageSize] * pageSize assuming 1Mi pageSize |
|---|---|---|
| request 500Mi, factor 0.6 | 600Mi (very early throttling when memory usage is just 100Mi above requested memory; 400Mi unused) | 800Mi |
| request 800Mi, factor 0.6 | no throttling (600 < 800 i.e. memory.high < memory.request => no throttling) | 920Mi |
| request 1000Mi, factor 0.6 | max | max |
| request 500Mi, factor 0.8 | 800Mi (early throttling at 800Mi, when 200Mi is unused) | 900Mi |
| request 850Mi, factor 0.8 | no throttling (800 < 850 i.e. memory.high < memory.request => no throttling) | 970Mi |
| request 500Mi, factor 0.4 | no throttling (400 < 500 i.e. memory.high < memory.request => no throttling) | 700Mi |
Note: As seen from the examples in the table, the formula used in Alpha v1.27 implementation eliminates the cases of memory.high being less than memory.request. However, it still can result in early throttling if memory throttling factor is set low. Hence, it is recommended to set a high memory throttling factor to avoid early throttling.
Quality of Service for Pods
In addition to the change in formula for memory.high, we are also adding the support for memory.high to be set as per Quality of Service(QoS) for Pod classes. Based on user feedback in Alpha v1.22, some users would like to opt-out of MemoryQoS on a per pod basis to ensure there is no early memory throttling. By making user’s pods guaranteed, they will be able to do so. Guaranteed pod, by definition, are not overcommitted, so memory.high does not provide significant value.
Following are the different cases for setting memory.high as per QOS classes:
Guaranteed Guaranteed pods by their QoS definition require memory requests=memory limits and are not overcommitted. Hence MemoryQoS feature is disabled on those pods by not setting memory.high. This ensures that Guaranteed pods can fully use their memory requests up to their set limit, and not hit any throttling.
Burstable Burstable pods by their QoS definition require at least one container in the Pod with CPU or memory request or limit set.
Case I: When requests.memory and limits.memory are set, the formula is used as-is:
memory.high = floor[ (requests.memory + memory throttling factor * (limits.memory - requests.memory)) / pageSize ] * pageSizeCase II. When requests.memory is set, limits.memory is not set, we substitute limits.memory for node allocatable memory in the formula:
memory.high = floor[ (requests.memory + memory throttling factor * (node allocatable memory - requests.memory))/ pageSize ] * pageSizeCase III. When requests.memory is not set and limits.memory is set, we set
requests.memory = 0in the formula:memory.high = floor[ (memory throttling factor * limits.memory) / pageSize ] * pageSizeBestEffort The pod gets a BestEffort class if limits.memory and requests.memory are not set. We set
requests.memory = 0and substitute limits.memory for node allocatable memory in the formula:memory.high = floor[ (memoryThrottlingFactor * node allocatable memory) / pageSize ] * pageSize
Alternative solutions for implementing memory.high
Alternative solutions that were discussed (but not preferred) before finalizing the implementation for memory.high are:
Allow customers to set memoryThrottlingFactor for each pod in annotations.
Proposal: Add a new annotation for customers to set memoryThrottlingFactor to override kubelet level memoryThrottlingFactor.
- Pros
- Allows more flexibility.
- Can be quickly implemented.
- Cons
- Customers might not need per pod memoryThrottlingFactor configuration.
- It is too low-level detail to expose to customers.
- Pros
Allow customers to set MemoryThrottlingFactor in pod yaml.
Proposal: Add a new field in API for customers to set memoryThrottlingFactor to override kubelet level memoryThrottlingFactor.
- Pros
- Allows more flexibility.
- Cons
- Customers might not need per pod memoryThrottlingFactor configuration.
- API changes take a lot of time, and we might eventually realize that the customers don’t need per pod level setting.
- It is too low-level detail to expose to customers, and it is highly unlikely to get an API approval.
- Pros
[Preferred Alternative]: Considering the cons of the alternatives mentioned above, adding support for memory QoS looks more preferable over other solutions for following reasons:
- Memory QoS complies with QoS which is a wider known concept.
- It is simple to understand as it uses kubelet-level configuration (
memoryThrottlingFactor,memoryReservationPolicy) rather than per-pod settings. - It doesn’t require Pod API changes, keeping the low-level cgroup details abstracted from workload authors.
Beta v1.28 - Cancelled
The feature was planned to graduate to Beta in v1.28 but was backed out due to a livelock issue:
workloads hitting memory.high on kernels < 5.9 would hang indefinitely instead of progressing
toward OOM. The kernel’s memory reclaim rate couldn’t keep up with allocation rate, causing
processes to stall at near-zero CPU with no forward progress.
Root cause: When memory usage hits memory.high, the kernel triggers synchronous reclaim. On kernels < 5.9, if the workload’s allocation rate exceeded the reclaim rate, the process would enter a livelock where it repeatedly allocating, hitting the limit, reclaiming, allocating again and never reaching memory.max where OOM would terminate it cleanly.
Resolution: Kernel 5.9+ (October 2020) resolved this with commit b3ff929 , which ensures forward progress even when allocation rate exceeds reclaim rate.
See the Previous Status (v1.28) for the original investigation and test results documenting this behavior.
Alpha v1.36
Status: The livelock issue that blocked v1.28 has been resolved—kernel 5.9+ (October 2020) contains a fix that prevents indefinite throttling at memory.high.
Changes from Alpha v1.27:
- No changes to memory.high formula
- Kubelet adds a kernel version check for 5.9+ to mitigate the livelock issue. If the kernel version < 5.9, the Kubelet logs a warning because such kernels may exhibit livelocks at
memory.high. - Burstable pod/container request protection now uses
memory.low, while Guaranteed continues to usememory.min. - Add node-level metrics for observability:
kubelet_memory_qos_node_memory_min_bytes: Gauge for total cgroup v2memory.minin bytes for Guaranteed pods. Note: The kubepods root cgroupmemory.minis set to guaranteed + burstable requests (parent must cover children’s protection), but this metric reports only the Guaranteed portion.kubelet_memory_qos_node_memory_low_bytes: Gauge for total cgroup v2memory.lowin bytes for Burstable pods.
- Add
memoryReservationPolicyenum to KubeletConfiguration (default:None). When set toTieredReservation, kubelet setsmemory.minfor Guaranteed containers and pods, setsmemory.lowfor Burstable containers and pods. This provides independent control over memory protection:memoryReservationPolicy: None→ disablesmemory.min/memory.lowprotectionmemoryThrottlingFactor: 1.0→ effectively disables early throttling (memory.high = limit)- Operators can combine both for full opt-out while keeping the feature gate enabled
- Comprehensive documentation of failure modes and troubleshooting
- Verified feature interactions with In-Place Pod Resize (KEP-1287 ), DRA (KEP-4381 ), and Swap (KEP-2400 ) Note: While PSI is valuable for monitoring, implementing userspace OOM policies (such as systemd-oomd integration for graceful eviction) is outside the scope of this KEP.
Kernel Requirement:
Linux kernel 5.9+ is required for correct memory.high behavior. See Prerequisite
for details.
| Kernel Version | Status | Notes |
|---|---|---|
| < 5.9 | Not Recommended | May exhibit livelock at memory.high |
| 5.9+ | Supported | Contains livelock fix (commit b3ff92916af3) |
Container Runtime Requirement:
| Runtime | Minimum Version |
|---|---|
| containerd | 1.6.0 |
| CRI-O | 1.22 |
Beta v1.37
Status: Beta graduation criteria met. Rollback cleanup is fully implemented. Benchmark testing validates node stability under sustained memory pressure. No regressions reported from Alpha v3 (v1.36) users.
Changes from Alpha v1.36:
memoryThrottlingFactordefault changed from0.9tonil. Whennil, kubelet does not setmemory.highfor any containers. Operators opt intomemory.highthrottling by explicitly settingmemoryThrottlingFactorto a value in (0, 1.0] (e.g.,0.9). This ensures no behavior change for existing workloads on upgrade to v1.37.- No changes to memory.high formula or
memoryReservationPolicymapping - Rollback cleanup fully implemented: when the MemoryQoS feature gate is disabled, cgroup v2 memory knobs are cleaned up as follows:
memory.minon the kubepods root cgroup is reset to 0 at kubelet startup (kubernetes/kubernetes#138903 )memory.lowon the Burstable QoS cgroup is reset to 0 at kubelet startup (kubernetes/kubernetes#138903 )- Per-container
memory.highis set tomaxin the container resource config so that it is cleared when the container runtime applies the config. This takes effect on newly created containers, restarted containers, and existing containers updated via InPlacePodResize (KEP-1287 ). For already-running containers with no restart or resize, stalememory.highvalues persist until the next container restart or InPlacePodResize update (kubernetes/kubernetes#139377 )
- Rollback e2e test re-enabled (previously skipped due to systemd unit property side effects, see kubernetes/kubernetes#138485 )
- Pod-level and container-level
memory.min/memory.lowvalues persist after feature disable but are effectively neutralized because parent cgroup protection is set to 0 (cgroup v2 memory protection is hierarchical — parent=0 wins) - Benchmark testing:
- Alpha v1.36: tiered reservation,
memory.highthrottle behavior, and kubelet overhead (benchmark report ) - Rollback safety and BestEffort
memory.highfix validation (beta benchmark report )
- Alpha v1.36: tiered reservation,
User Stories (Optional)
Memory Sensitive Workload
Some workloads are sensitive to memory allocation and availability, slight delays may cause service outage. In this case, a mechanism is needed to ensure the quality of memory. We must provide guarantee in both of the following aspects:
- Retain memory requests to reduce allocation latency
- Protect memory requests from being reclaimed
Node Availability
The stability of kubelet node is very important to users. As the key resource of the node, the availability of memory is the key factor for the stability of the node. We should do something to protect node reserved memory.
Comparison with Memory Manager
The Memory Manager is a new component of kubelet ecosystem proposed to enable single-NUMA and multi-NUMA guaranteed memory allocation at topology level. Memory QoS proposal mainly uses cgroups v2 to improve the quality of memory requests, thereby improving the memory qos of Guaranteed and Burstable pods and even entire node.
See also https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/1769-memory-manager
memory.low vs memory.min
In cgroups v2, memory.low is designed for best-effort memory protection which is more like “soft guarantee” and won’t be reclaimed unless memory can’t be reclaimed from any unprotected cgroups. memory.min is a bit aggressive. It will always retain specified amount of memory and it can never be reclaimed. When requirement is not satisfied, system OOM killer will be invoked.
Notes/Constraints/Caveats (Optional)
Container Type Handling:
- Init containers: Run sequentially before app containers. Their memory requests are NOT summed with app containers for pod-level memory.min since they don’t run concurrently. Each init container gets its own memory.min while running.
- Sidecar containers (KEP-753): Restartable init containers that run concurrently with app containers. Their memory requests ARE included in pod-level memory.min calculation.
- Ephemeral containers: Debug containers with no resource requests. They do not affect memory.min. For Guaranteed pods, ephemeral containers don’t change QoS class and the pod remains exempt from memory.high.
Other Considerations:
- Pod overhead (RuntimeClass): Pod overhead is included in pod-level memory.min calculation. The
ResourceConfigForPod()function callsPodRequests()which includes overhead by default. This means overhead memory receives memory.min protection at the pod cgroup level. - In-Place Pod Resize (KEP-1287): When container memory requests/limits are resized in-place, memory.min/memory.low and memory.high are recalculated during the next cgroup reconciliation cycle. When MemoryQoS is disabled, InPlacePodResize clears stale
memory.hightomaxon already-running containers that were created while MemoryQoS was enabled. - Swap (KEP-2400): When swap is enabled, memory.high triggers reclaim which may push pages to swap rather than throttle allocations. This is expected behavior.
- memory.min overcommit: The scheduler ensures sum(pod_requests) ≤ node_allocatable before placing pods. Since memory.min = requests.memory, memory.min overcommit is prevented at scheduling time. In edge cases (e.g., node allocatable decreases after pods are scheduled), if sum of memory.min exceeds physical memory, the kernel may OOM kill to honor guarantees.
- memoryThrottlingFactor validation: Default is
nil(nomemory.highset). When explicitly set, valid range is (0, 1.0]. Values outside this range are rejected by kubelet configuration validation. Setting to 1.0 effectively disables early throttling (memory.high = limit). - memoryReservationPolicy: When set to
TieredReservation, kubelet setsmemory.minfor Guaranteed containers/pods, andmemory.lowfor Burstable containers/pods. Default isNone. - TieredReservation and Guaranteed pods with page-cache-heavy workloads: When
memoryReservationPolicy: TieredReservationis configured, Guaranteed pods havememory.minset equal tomemory.max(since requests = limits). Per the kernel cgroup v2 documentation ,memory.minspecifies memory that “can never be reclaimed by the system” and “the cgroup’s memory won’t be reclaimed under any conditions.” Whenmemory.minequalsmemory.max, the kernel cannot reclaim page cache within the cgroup to make room for new allocations, causing OOM kills when the cgroup reachesmemory.max. This does not affect Burstable pods becausememory.lowis soft protection and the kernel still reclaims page cache within the cgroup when it approachesmemory.max. With the defaultmemoryReservationPolicy: None(v1.36+),memory.minis set to 0 for all pods, so page cache is freely reclaimable and no additional OOM risk is introduced. Users who opt intoTieredReservationshould ensure Guaranteed pods with page-cache-heavy workloads size their memory limits to include headroom for page cache. - pageSize: The formula uses the system’s base page size (typically 4KiB on x86_64, configurable on ARM64). Hugepages are not used for the pageSize calculation
Risks and Mitigations
The main risk of this proposal is throttling applications too early.
We intend to mitigate this by (1) setting a memory.high that is closer to the
limit and (2) only throttling when usage > request.
Blast Radius: In Alpha (v1.36), the MemoryQoS feature gate is disabled by default. In Beta (v1.37), the feature gate is enabled by default. On upgrade to v1.37, memory.high is not set by default to protect existing workloads on upgrade. memoryThrottlingFactor defaults to nil; operators opt into memory.high throttling by explicitly setting a value in (0, 1.0] (e.g., 0.9, leaving 10% headroom before throttling). Memory protection (memory.min/memory.low) is not applied unless memoryReservationPolicy is set to TieredReservation (default is None). Mitigations:
- Operators can set
memoryReservationPolicy: None(default) to disable memory.min/memory.low protection - Guaranteed pods are exempt from memory.high throttling
- Operators should test with the feature explicitly enabled before production upgrades
Design Details
Prerequisite
- Kernel 5.9+ with cgroups v2 unified hierarchy (kernel 5.9 includes livelock fix)
- CRI runtime supports cgroups v2 Unified Spec for container level
- Kubelet enables
--enforce-node-allocatable=<pods, kube-reserved, system-reserved>
Feature Gate
In Beta (v1.37), the MemoryQoS feature gate is enabled by default. To disable it, set --feature-gates=MemoryQoS=false, and ensure memoryReservationPolicy is not set or is set to None.
When enabled, the following KubeletConfiguration fields control behavior:
memoryThrottlingFactor(float, range (0, 1.0], default 0.9): Controls memory.high calculation. Set to 1.0 to effectively disable early throttling.memoryReservationPolicy(enum, defaultNone): Controls whether request protection is applied. Set toTieredReservationto enablememory.minfor Guaranteed andmemory.lowfor Burstable workloads.
Mapping Rules
Container/Pod
- If container sets
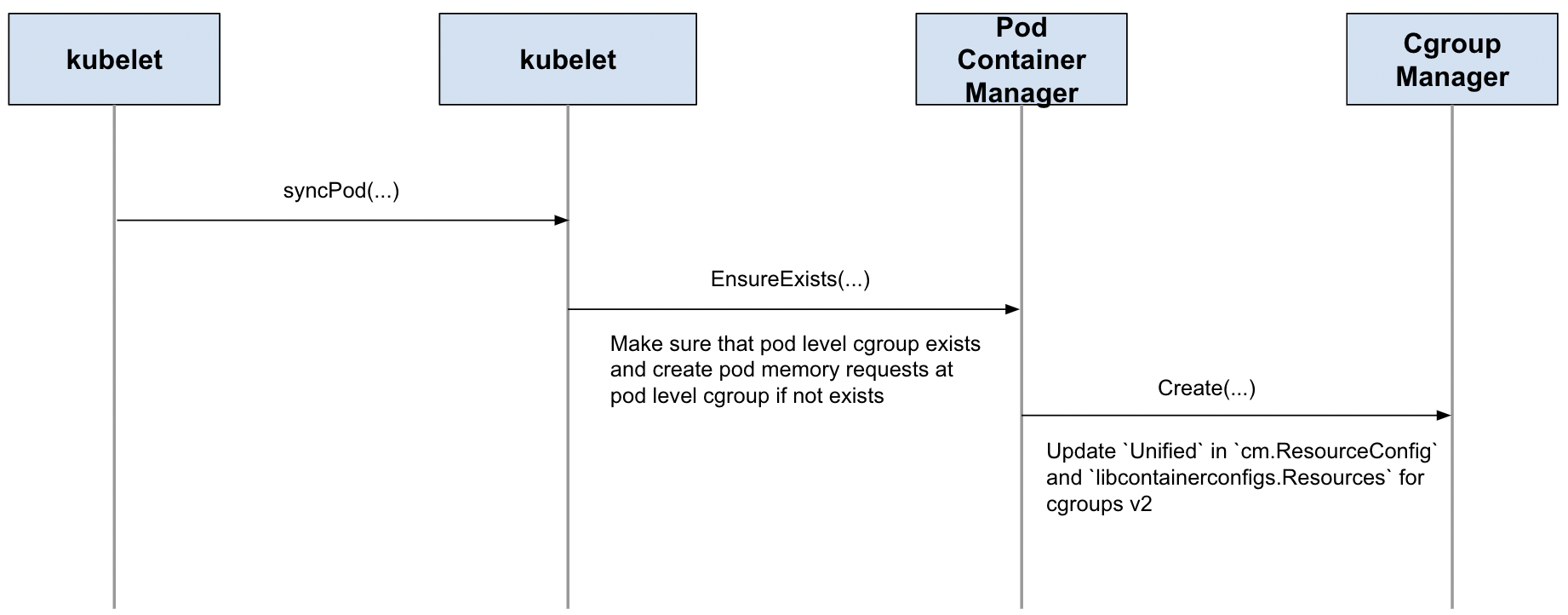
requests.memory, we setmemory.min=pod.spec.containers[i].resources.requests[memory]forGuaranteedcontainer level cgroups, andmemory.low=pod.spec.containers[i].resources.requests[memory]forBurstablecontainer level cgroups - If any containers in pod set
requests.memory, we set pod-level memory protection asmemory.min=sum(pod.spec.containers[i].resources.requests[memory])forGuaranteedpods, andmemory.low=sum(pod.spec.containers[i].resources.requests[memory])forBurstablepods - If container sets
limits.memory, we setmemory.high=floor[(requests.memory + memoryThrottlingFactor * (limits.memory - requests.memory))/pageSize] * pageSizefor container level cgroup ifmemory.high>memory.min - If container doesn’t set
limits.memory, we substitutenode allocatable memoryforlimits.memoryin the formula above - If kubelet sets
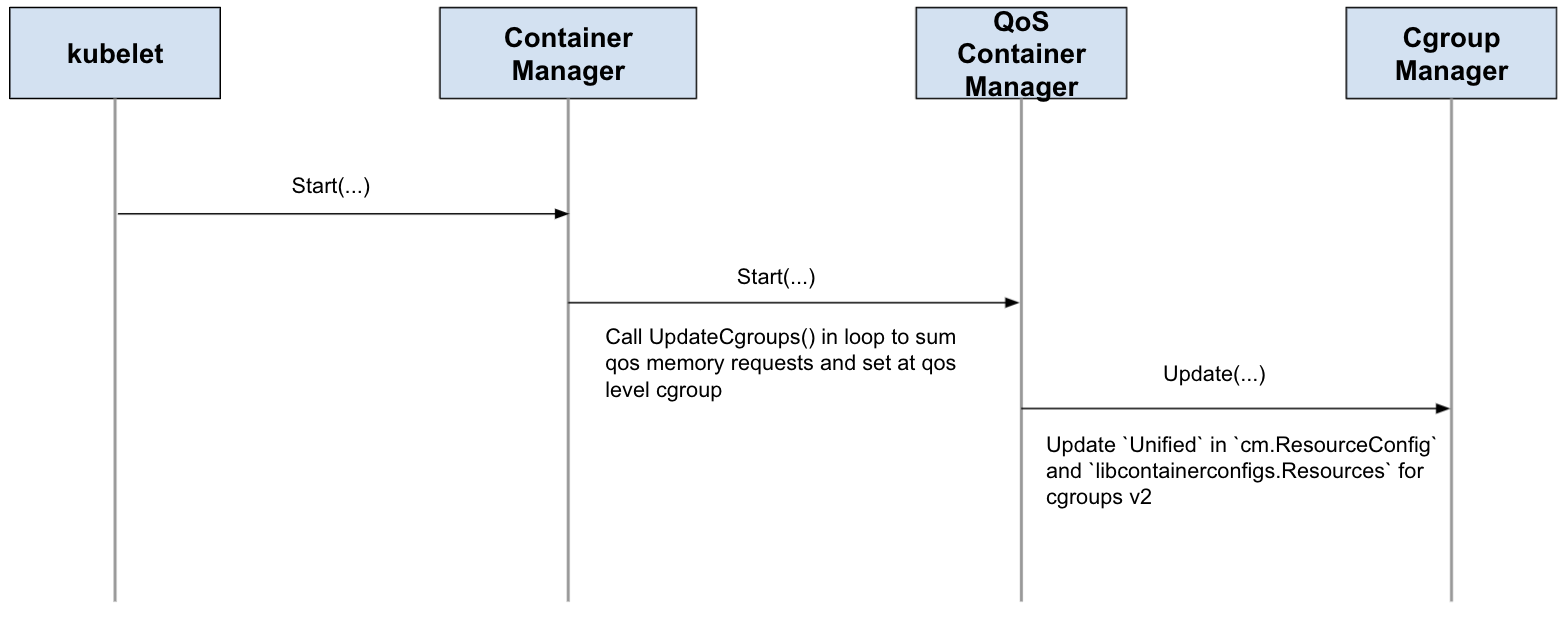
--cgroups-per-qos=true, the kubepods root cgroup sets memory.min = sum(guaranteed_requests) + sum(burstable_requests) so the parent covers both hard and soft protection for its children. The Burstable QoS cgroup sets memory.low = sum(burstable_requests) for soft protection - There are no changes regarding memory limit, that is
memory.max=memory_limits(same as existing cgroup v2 implementation)
Node
- If kubelet sets
--enforce-node-allocatable=kube-reserved,--kube-reserved=[a]and--kube-reserved-cgroup=[b], we setmemory.min=[a]for node level cgroup[b] - If kubelet sets
--enforce-node-allocatable=system-reserved,--system-reserved=[a]and--system-reserved-cgroup=[b], we setmemory.min=[a]for node level cgroup[b] - If kubelet sets
--enforce-node-allocatable=pods, we setmemory.min=sum(pod[i].spec.containers[j].resources.requests[memory])for kubepods cgroup
Interactive
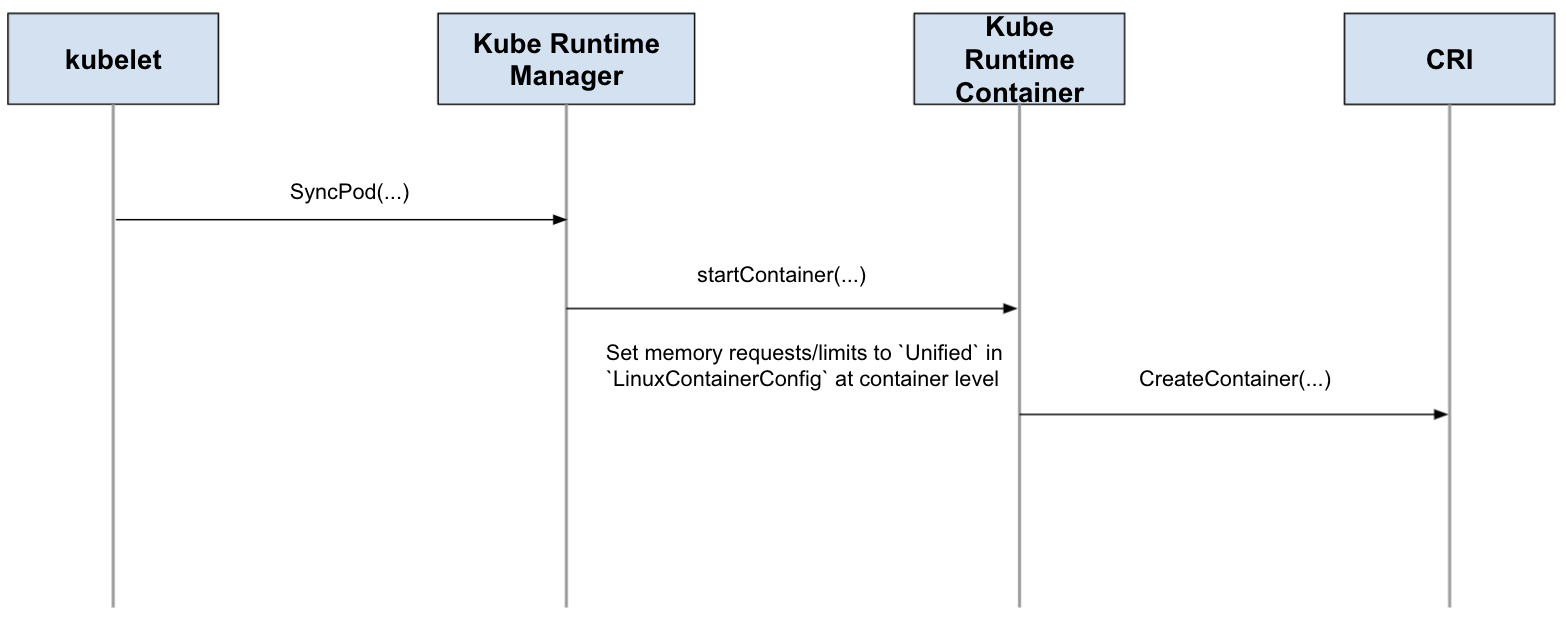
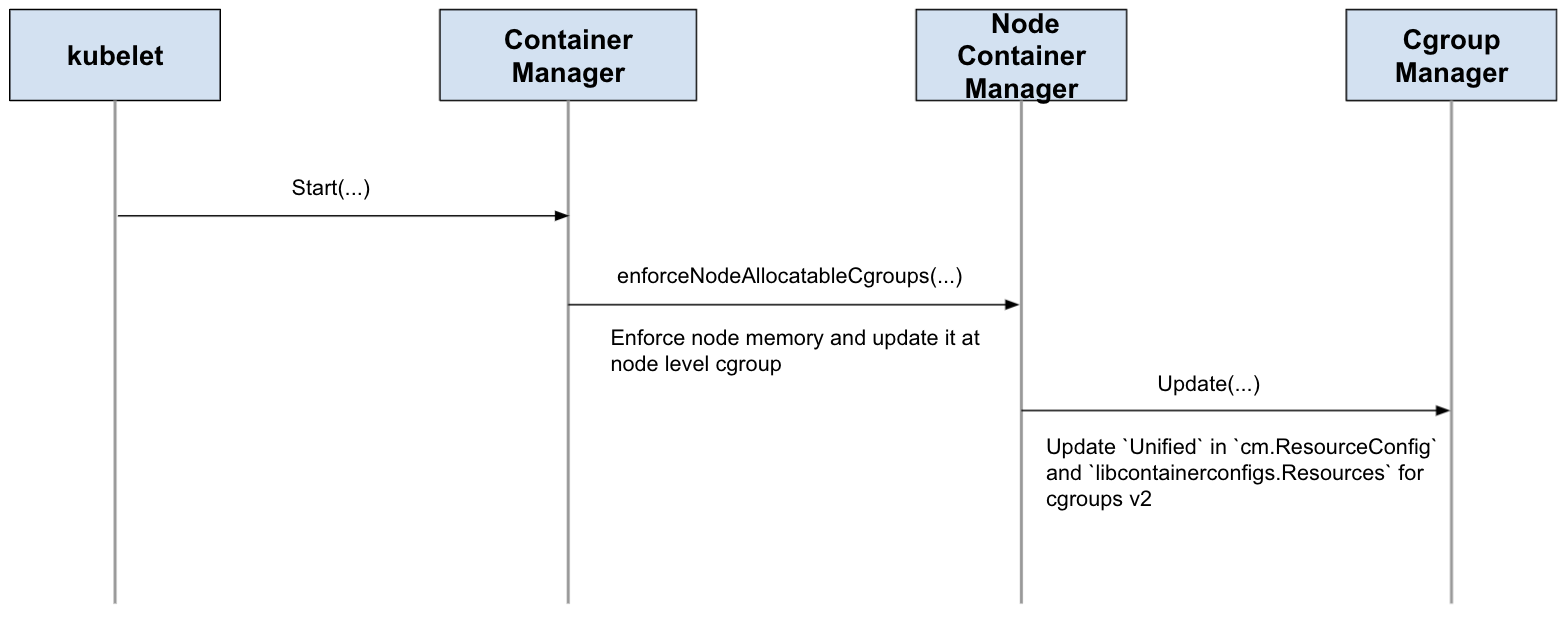
New Unified field will be added in both CRI and QoS Manager for cgroups v2 extra parameters. It is recommended to have the same semantics as opencontainers/runtime-spec#1040
- container level:
Unifiedadded inLinuxContainerResources - pod/node level:
Unifiedadded incm.ResourceConfig
Workflow
Container
Pod
QoS
Node
Cgroup Hierarchy
Note: Paths shown use cgroupfs driver format. For systemd cgroup driver (common in production), paths use slice notation:
- cgroupfs:
/cgroup2/kubepods/burstable/pod<UID>/ - systemd:
/sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<UID>.slice/
Container/Pod (cgroupfs format):
// Container
/cgroup2/kubepods/pod<UID>/<container-id>/memory.min=pod.spec.containers[i].resources.requests[memory] // Guaranteed
/cgroup2/kubepods/burstable/pod<UID>/<container-id>/memory.low=pod.spec.containers[i].resources.requests[memory] // Burstable
/cgroup2/kubepods/burstable/pod<UID>/<container-id>/memory.high=floor[(requests.memory + memoryThrottlingFactor * (limits.memory - requests.memory))/pageSize] * pageSize // Burstable
// Pod
/cgroup2/kubepods/pod<UID>/memory.min=sum(pod.spec.containers[i].resources.requests[memory]) // Guaranteed
/cgroup2/kubepods/burstable/pod<UID>/memory.low=sum(pod.spec.containers[i].resources.requests[memory]) // Burstable
// QoS ancestor cgroups
/cgroup2/kubepods/memory.min=sum(guaranteed_requests + burstable_requests) // parent covers all children
/cgroup2/kubepods/burstable/memory.low=sum(burstable_pod_requests) // soft protection
/cgroup2/kubepods/burstable/memory.min=0 // keeps kernel default, not explicitly written
Node:
/cgroup2/<kube-reserved-cgroup,system-reserved-cgroup>/memory.min=<kube-reserved,system-reserved>
Cgroup v2 Support
After Kubernetes v1.19, kubelet can identify cgroups v2 and do the conversion. Since v1.0.0-rc93
, runc supports Unified to pass through cgroups v2 parameters. So we use this variable to pass cgroup v2 memory knobs when cgroups v2 mode is detected. After Kubernetes v1.36, kubelet also warns if MemoryQoS is enabled on kernels older than 5.9.
Container Runtime Interface (CRI) Changes
We need add new field Unified in CRI api which is basically passthrough for OCI spec Unified field and has same semantics: opencontainers/runtime-spec#1040
type LinuxContainerResources struct {
...
Unified map[string]string `json:"unified,omitempty"`
}
Test Plan
[X] I/we understand the owners of the involved components may require updates to existing tests to make this code solid enough prior to committing the changes necessary to implement this enhancement.
Overall Test plan:
Unit tests cover container/pod/node level cgroup functionality with containerd and CRI-O. Node e2e tests (added in v1.27+) validate that MemoryQoS cgroup settings are correctly applied.
Prerequisite testing updates
Unit tests
pkg/kubelet/cm:02/09/2026-67.2
Integration tests
n/a: MemoryQoS is validated through node e2e tests which run against a real kubelet and real cgroups v2 filesystem. Integration tests cannot verify cgroup file values (memory.min, memory.low, memory.high) since they run without a real node. See e2e tests
below.
e2e tests
Node e2e tests validate that MemoryQoS cgroup settings are correctly applied at container, pod, QoS-class, and node levels, including memory protection (memory.min/memory.low), throttling (memory.high), rollback cleanup, and memoryReservationPolicy switching.
Graduation Criteria
Alpha Graduation (v1.36 - Alpha v3)
- cgroup_v2
is in
GA(graduated in v1.25) - Kernel 5.9+ required for correct memory.high behavior (livelock fix)
memoryReservationPolicyKubeletConfiguration field for independent control over memory.min protection- New metrics:
kubelet_memory_qos_node_memory_min_byteskubelet_memory_qos_node_memory_low_bytes
- Memory QoS is covered by unit and e2e-node tests
- Memory QoS supports containerd 1.6+ and CRI-O 1.22+
Beta Graduation
- All Alpha v3 criteria met
- Benchmark testing validates node stability under sustained memory pressure with
sum(memory.min)near capacity - Observability via cgroup files (memory.min, memory.high, memory.events) and existing cadvisor metrics (container_oom_events_total)
- Rollback cleanup behavior is implemented and validated (including reenabling the rollback e2e test)
- Production feedback from Alpha v3 users confirms no regressions
GA Graduation
- Memory QoS has been in Beta for at least 2 releases
- Memory QoS sees adoption in production environments
- Memory QoS is covered by conformance tests
Upgrade / Downgrade Strategy
If MemoryQoS enabled, verify kernel version compatibility (5.9+ recommended) before upgrade.
Version Skew Strategy
Kubelet and Kernel Skew: This feature requires kernel 5.9+. The Kubelet will check the kernel version, if the kernel is < 5.9, will log a warning that may exhibit livelocks at memory.high. Operators can set memoryThrottlingFactor: 1.0 to disable early throttling or memoryReservationPolicy: None (default) to disable memory.min/memory.low protection.
Kubelet and CRI skew: If the CRI does not support the Unified cgroup v2, upgrade containerd to 1.6+ or CRI-O to 1.22+.
Production Readiness Review Questionnaire
Feature Enablement and Rollback
v1.37 status: rollback cleanup is fully implemented. When the MemoryQoS feature gate is disabled:
- QoS class level
memory.min(kubepods root cgroup) andmemory.low(Burstable QoS cgroup) are reset to 0 at kubelet startup (kubernetes/kubernetes#138903 ) - Per-container
memory.highis set tomaxin the container resource config so that it is cleared when the container runtime applies the config. This takes effect on newly created containers, restarted containers, and existing containers updated via InPlacePodResize. For already-running containers with no restart or resize, stalememory.highvalues persist until the next container restart or InPlacePodResize update (kubernetes/kubernetes#139377 ) - Pod-level and container-level
memory.min/memory.lowvalues persist but are effectively neutralized because parent cgroup protection is set to 0 (cgroup v2 memory protection is hierarchical — parent=0 wins)
How can this feature be enabled / disabled in a live cluster?
- Feature gate (also fill in values in
kep.yaml)- Feature gate name: MemoryQoS
- Components depending on the feature gate: kubelet
Does enabling the feature change any default behavior?
Yes, when memoryReservationPolicy is set to TieredReservation (default is None), the kubelet will set memory.min for Guaranteed pod/container level cgroups and memory.low for Burstable pod/container level cgroups. The MemoryQoS feature gate also sets memory.high for burstable and best effort containers, which may slow memory allocation when usage reaches memory.high. memory.min on the kubepods root QoS cgroup and memory.low on the Burstable QoS cgroup will be set when --cgroups-per-qos is satisfied. memory.min for node level cgroups will be set when --enforce-node-allocatable is satisfied.
Can the feature be disabled once it has been enabled (i.e. can we roll back the enablement)?
Set featuregate MemoryQoS: false to stop memory protection writes. The kubelet stops writing memory.min/memory.low/memory.high for new pods and containers. On kubelet startup, QoS class level memory.min (kubepods root cgroup) and memory.low (Burstable QoS cgroup) are reset to 0. Per-container memory.high is set to max in the container resource config and is cleared when the container runtime applies the config — this takes effect on newly created containers, restarted containers, and existing containers updated via InPlacePodResize. For already-running containers with no restart or resize, stale memory.high values persist until the next container restart or InPlacePodResize update. Pod-level and container-level memory.min/memory.low values persist but are effectively neutralized because parent cgroup protection is set to 0 (cgroup v2 memory protection is hierarchical — parent=0 wins).
What happens if we reenable the feature if it was previously rolled back?
For newly created pods, the kubelet will reconcile memory.min/memory.low/memory.high with related cgroups.
QoS class level and pod level memory.min/memory.low are reconciled during the next QoS cgroup manager update cycle.
Existing container level memory.min/memory.low/memory.high will keep their current values until the container is restarted.
Are there any tests for feature enablement/disablement?
Yes, unit and e2e tests cover feature enabled behavior. When enabled, and memoryReservationPolicy: TieredReservation, tests verify memory.min/memory.low/memory.high for workloads and node cgroups are set correctly. Tests also cover memoryReservationPolicy: None behavior.
Rollback cleanup is fully implemented and the rollback e2e test has been re-enabled (see kubernetes/kubernetes#138903 ):
When transitioning from enabled to disabled, tests verify QoS class level memory.min/memory.low reset to 0 at kubelet startup. Tests also verify per-container memory.high is reset to max during InPlacePodResize updates (see kubernetes/kubernetes#139377
). Tests also cover the memoryReservationPolicy: None configuration to verify memory.min/memory.low is set to 0.
Note: Pod-level and container-level memory.min/memory.low values persist after rollback but are effectively neutralized because cgroup v2 memory protection is hierarchical (parent=0 wins).
Rollout, Upgrade and Rollback Planning
In Beta (v1.37), the MemoryQoS feature gate is enabled by default. No explicit opt-in is required. The feature uses two KubeletConfiguration fields:
memoryThrottlingFactor(float, default 0.9): Controls memory.high calculationmemoryReservationPolicy(enum, defaultNone): Controls whether memory protection is applied. Set toTieredReservationto enable memory.min for Guaranteed and memory.low for Burstable workloads.
It doesn’t require any special opt-in by the user in their PodSpec. The kubelet reconciles memory.min/memory.low/memory.high with related cgroups depending on whether the feature gate is enabled and the configuration values.
How can a rollout or rollback fail? Can it impact already running workloads?
When the feature gate is enabled and kubelet restarts, the kubelet reconciles cgroup settings for all pods. This means:
- Existing pods will have
memory.min/memory.low/memory.highset during the next cgroup reconciliation cycle - Node-level
memory.minwill be set immediately on kubelet startup - Impact is gradual as pods are reconciled, not instantaneous
What specific metrics should inform a rollback?
- Increased OOM kills on nodes where feature is enabled (
container_oom_events_totalvia cadvisor) container_memory_working_set_bytesfrom cadvisor shows memory approaching limits- memory.events high counter (from cgroup files) shows throttle events
- PSI memory.pressure (if kernel supports it) shows stall time
- Application-level P99 latency (if instrumented) correlated with throttling
- Containers stuck with near-zero CPU usage despite “Running” status (symptom of livelock on kernel < 5.9)
Were upgrade and rollback tested? Was the upgrade->downgrade->upgrade path tested?
Yes. Manual testing was performed:
- Upgrade: Enabling
MemoryQoS,memoryReservationPolicy: TieredReservationon a running kubelet correctly setsmemory.min/memory.low/memory.highon new pods and updates node-level cgroups - Rollback: Disabling MemoryQoS stops new MemoryQoS writes. QoS class level
memory.minandmemory.loware cleared to 0 at kubelet startup. Per-containermemory.highis set tomaxin the container resource config and is cleared when the container runtime applies the config on newly created containers, restarted containers, or existing containers updated via InPlacePodResize. For already-running containers with no restart or resize, stalememory.highvalues persist until the next container restart or InPlacePodResize update. - Upgrade->downgrade->upgrade: On re-enable, cgroup values are correctly reconciled; stale values from the prior enable cycle are overwritten.
Is the rollout accompanied by any deprecations and/or removals of features, APIs, fields of API types, flags, etc.?
No
Monitoring Requirements
How can an operator determine if the feature is in use by workloads?
When memoryReservationPolicy: TieredReservation is configured, an operator could run ls /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<SOME_ID>.slice on a node with cgroupv2 enabled to confirm the values of memory.min (Guaranteed) and memory.low (Burstable) files are non-zero, which indicates that the feature is in use by workloads. For example, for a Burstable pod: cat /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod<SOME_ID>.slice/memory.low. If it returns a value > 0, the feature is active.
An operator can use kubelet metric kubelet_memory_qos_node_memory_min_bytes and kubelet_memory_qos_node_memory_low_bytes to observe protected memory bytes on a node.
With the default configuration (memoryReservationPolicy: None), an operator can check if memory.high is set below max on a Burstable or BestEffort container to confirm the feature is active.
How can someone using this feature know that it is working for their instance?
- Other (treat as last resort)
- Details: Operators can verify Memory QoS is working by inspecting cgroup v2 files
in the container’s cgroup hierarchy. Check
memory.minandmemory.highvalues are set according to the pod’s requests and limits. Thememory.eventsfile shows breach counters forhigh(throttling events) andlow/minprotection events.
- Details: Operators can verify Memory QoS is working by inspecting cgroup v2 files
in the container’s cgroup hierarchy. Check
What are the reasonable SLOs (Service Level Objectives) for the enhancement?
- Pod startup latency SLO should not be affected (cgroup setup adds negligible overhead)
- Application throughput may decrease for memory-intensive Burstable/BestEffort workloads due to memory.high throttling—this is by design to prevent OOM
- Node stability should improve as memory.min protects guaranteed memory from reclaim
What are the SLIs (Service Level Indicators) an operator can use to determine the health of the service?
- Metrics
- Metric name:
container_oom_events_total(existing cadvisor metric)- Aggregation method: rate() to detect OOM kill spikes
- Components exposing the metric: kubelet (via cadvisor)
- Metric name:
container_memory_working_set_bytes(existing cadvisor metric)- Aggregation method: compare against memory.high threshold to detect throttling
- Components exposing the metric: kubelet (via cadvisor)
- Metric name:
kubelet_memory_qos_node_memory_min_bytes- Aggregation method: gauge
- Components exposing the metric: kubelet
- Metric name:
kubelet_memory_qos_node_memory_low_bytes- Aggregation method: gauge
- Components exposing the metric: kubelet
- Metric name:
container_memory_events_high_total- Aggregation method: rate() to detect memory.high throttle event spikes
- Components exposing the metric: kubelet (via cadvisor)
- Metric name:
container_memory_events_max_total- Aggregation method: rate() to detect memory limit exceeded events
- Components exposing the metric: kubelet (via cadvisor)
- Metric name:
- Other
Details: Monitor cgroup files directly for throttling events:
memory.eventsfile showshighcounter (throttle events)- Compare
memory.currentvsmemory.highto detect near-throttle conditions - PSI provides observability to determine if the workload is undergoing significant memory throttling:
# Check container memory pressure cat /sys/fs/cgroup/.../memory.pressure # full avg10 > 5 indicates significant throttling
Are there any missing metrics that would be useful to have to improve observability of this feature?
No.
Dependencies
Does this feature depend on any specific services running in the cluster?
Linux kernel 5.9+
- Usage description: Required for correct memory.high behavior (contains livelock fix)
- Impact of its outage on the feature: N/A - kernel is always available
- Impact of its degraded performance or high-error rates on the feature: Kernels 4.5-5.8 have cgroups v2 but lack the livelock fix, which can cause workloads to hang indefinitely when hitting memory.high
Container runtime with cgroup v2 support
- Usage description: Runtime must support setting memory.min and memory.high cgroup v2 parameters
- Impact of its outage on the feature: Feature cannot be used without cgroup v2 runtime support
- Impact of its degraded performance or high-error rates on the feature: N/A - runtime either supports cgroup v2 or it doesn’t
Scalability
Will enabling / using this feature result in any new API calls?
No new API calls will be generated.
Will enabling / using this feature result in introducing new API types?
No.
Will enabling / using this feature result in any new calls to the cloud provider?
No.
Will enabling / using this feature result in increasing size or count of the existing API objects?
No.
Will enabling / using this feature result in increasing time taken by any operations covered by existing SLIs/SLOs?
No.
Will enabling / using this feature result in non-negligible increase of resource usage (CPU, RAM, disk, IO, …) in any components?
No.
Can enabling / using this feature result in resource exhaustion of some node resources (PIDs, sockets, inodes, etc.)?
No, resources like PIDs, sockets, inodes will not be affected. However, additional memory throttling can be experienced which is intended by this feature.
Troubleshooting
How does this feature react if the API server and/or etcd is unavailable?
This feature operates entirely at the kubelet level:
- Existing cgroup settings persist
- Running pods continue with their memory.min/memory.low/memory.high values
- Memory protection is maintained for existing pods
- New pods cannot be scheduled (standard Kubernetes behavior when API server unavailable)
What are other known failure modes?
Livelock at memory.high (kernel < 5.9)
- Detection: Container CPU usage near zero despite “Running” status;
cat /sys/fs/cgroup/.../memory.pressureshowsfull avg10 > 10sustained - Mitigations: Upgrade to kernel 5.9+; disable MemoryQoS feature gate; increase container memory limits
- Diagnostics: Check kernel version with
uname -r; verify < 5.9; checkmemory.eventshigh counter incrementing rapidly - Testing: E2E tests require kernel 5.9+ environments
- Detection: Container CPU usage near zero despite “Running” status;
memory.min protection ineffective
- Detection: Pod memory drops below requests.memory under pressure
- Mitigations: Verify parent cgroup has memory.min set:
cat /sys/fs/cgroup/kubepods.slice/memory.min - Diagnostics: Walk cgroup hierarchy checking memory.min at each level; verify kubelet logs for QoS manager errors
- Testing: Unit tests verify parent cgroup configuration
Cgroups v2 not available
- Detection: Feature silently disabled;
memory.min/memory.highfiles don’t exist - Mitigations: Boot with
systemd.unified_cgroup_hierarchy=1 - Diagnostics:
stat /sys/fs/cgroup/cgroup.controllersfails;mount | grep cgroupshows cgroup v1 - Testing: Feature detection skips MemoryQoS on cgroups v1 systems
- Detection: Feature silently disabled;
Runtime doesn’t support unified map
- Detection: memory.min/memory.low/memory.high not set despite feature enabled
- Mitigations: Upgrade containerd to 1.6+ or CRI-O to 1.22+
- Diagnostics: Check runtime version; compare CRI request (kubelet logs -v=6) with actual cgroup values
Cgroups v2 available but kernel < 5.9
- Detection: Workloads hitting memory.high may exhibit livelock (high CPU, no progress, near-zero memory allocation rate)
- Mitigations: Upgrade kernel to 5.9+ or disable feature gate
- Diagnostics: Check kernel version with
uname -r; kernels 4.5-5.8 have cgroups v2 but lack the livelock fix - Note: Kubelet logs a startup warning when MemoryQoS is enabled with kernels older than 5.9.
Systemd unit property side effects during QoS reconciliation
- Detection: When feature is enabled, unrelated cgroup settings (for example,
cpu.max) reset after kubelet cgroup update cycles. - Mitigations: Disable MemoryQoS feature gate, or set
memoryReservationPolicy: Noneto stop QoS cgroup reconciliation writes. See kubernetes/kubernetes#138431 . - Diagnostics: Compare pre/post values in
/sys/fs/cgroup/kubepods.slice/*around kubelet cgroup update intervals - Note: The rollback cleanup now injects
memory.min=0/memory.low=0into existing startup cgroup update calls rather than adding new reconciliation calls, avoiding the side effects when the feature is disabled (kubernetes/kubernetes#138903 )
- Detection: When feature is enabled, unrelated cgroup settings (for example,
What steps should be taken if SLOs are not being met to determine the problem?
- Verify feature enablement:
ps aux | grep kubelet | grep MemoryQoS - Check cgroups v2:
cat /sys/fs/cgroup/cgroup.controllers - Check kernel version:
uname -r(should be 5.9+) - Verify cgroup values are set:
POD_UID=$(kubectl get pod <name> -o jsonpath='{.metadata.uid}' | tr '-' '_') cat /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod${POD_UID}.slice/*/memory.min - Check for throttling:
cat /sys/fs/cgroup/.../memory.events | grep high - If issues persist, set
memoryReservationPolicy: None(disable memory.min/memory.low) ormemoryThrottlingFactor: 1.0(disable early throttling) in KubeletConfiguration and restart kubelet
Implementation History
- 2020/03/14: initial proposal
- 2020/05/05: target Alpha to v1.22
- 2023/03/03: target Alpha v2 to v1.27
- 2023/06/14: target Beta to v1.28
- 2026/03/17: Alpha v3 updates for v1.36: kernel compatibility warning, node metrics, and
memoryReservationPolicyfor independent memory reservation control - 2026/06/01: Beta updates for v1.37: rollback cleanup fully implemented (
memory.min/memory.lowcleared at kubelet startup,memory.highcleared on container creation/restart/InPlacePodResize), rollback e2e test re-enabled
Drawbacks
The main drawbacks are concerns about unintended memory throttling and additional complexity due to utilization of several new cgroup v2 based memory controls (i.e., memory.min, memory.high).
However, we believe that impact of unintended throttling will be minimized due to a high throttling factor (see above) and the additional complexity is justified due to the additional resource management benefits
Alternatives
Please refer to alternatives mentioned above in the proposal section, which discusses the alternatives and changes from the original alpha design to the newly updated alpha design.
Infrastructure Needed (Optional)
N/A, no new infrastructure is needed, this KEP aims to reuse the existing node e2e jobs and framework.