KEP-2332: Pruning for Custom Resources
Pruning for Custom Resources
Table of Contents
Summary
CustomResources store arbitrary JSON data without following the typical Kubernetes API behaviour to prune unknown fields. This makes CRDs different, but also leads to security and general data consistency concerns because it is unclear what is actually stored in etcd.
This KEP proposes to add pruning of all fields which are not specified in the OpenAPI validation schemas given in the CRD.
Pruning will be opt-in in v1beta1 of apiextensions.k8s.io via
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
spec:
preserveUnknownFields: false
...
i.e. CRDs created in v1beta1 default to disabled pruning.
Pruning will be enabled for every CRD created in v1 and we will hide preserveUnknownFields in v1 in that case.
Pruning can be disabled for subtrees of CustomResources by setting the x-kubernetes-preserve-unknown-fields: true vendor extension. This allows to store arbitrary JSON or RawExtensions. This will even be possible at the root level, even in v1. Adding that in every to each object in a schema leads to the old behaviour.
Pruning requires structural schemas (as described in KEP Vanilla OpenAPI Subset: Structural Schema
) for all defined versions. Validation will reject the CRD with preserveUnknownFields: false otherwise.
Motivation
- Native Golang based resources do pruning as a consequence of the JSON unmarshalling algorithm. This is has become a fundamental behaviour of Kubernetes API semantics that CustomResources break.
- Pruning enforces consistency of data stored in etcd. Objects cannot suddenly render unaccessible because unexpected data breaks decoding.
- Even if unexpected data in etcd is of the right type and does not break decoding, it has not gone through validation, and probably an admission webhook either does not exist for many CRDs or it won’t have implemented pruning behaviour. Pruning at the decoding step enforces this (scenario: applying a new CR instance with new fields against a cluster with an old CRD manifest).
- Pruning is a counter-measure to security attacks which make use of knowledge of future versions of APIs with new security relevant fields. Without pruning an attacker can prepare CustomResources with privileged fields set. On version upgrade of the cluster, these fields can suddenly become alive and lead to unallowed behaviour.
Goals
- Prune unknown fields from CustomResources silently to match native type behaviour. Unknown means not specified in the OpenAPI validation spec.
- Allow to opt-out of pruning via the OpenAPI validation spec for a whole subtree of JSON objects.
Non-Goals
- Add a strict mode to the REST API which rejects objects with unknown fields.
Proposal
We assume the CRD has structural schemas (as defined in KEP Vanilla OpenAPI Subset: Structural Schema ).
We propose to
- derive the value-validation-less variant of the structural schema (trivial by definition of structural schema) and
- recursively follow the given CustomResource instance and the structural schema, removing fields from the former if they are not specified in the
propertiesof the latter. Skip field removal in that recursion step (not for children) ifadditionalPropertiesis defined in the schema. - return a deserialization error if the CustomResource instance JSON value and the type in the structural schema do not match
- fields of
metav1.TypeMeta(apiVersionandkind) andmetav1.ObjectMetaat the object root are implicitly specified.metav1.ObjectMetais always pruned.
Note that in (2) additionalProperties: <any-schema> stops field removal on that level. This includes additionalProperties: false, compare examples (4) and (5).
We do this in the serializer just after the binary payload has been unmarshalled into an map[string]interface{} for the request body and when reading from etcd, compare the yellow boxes in the following figure:
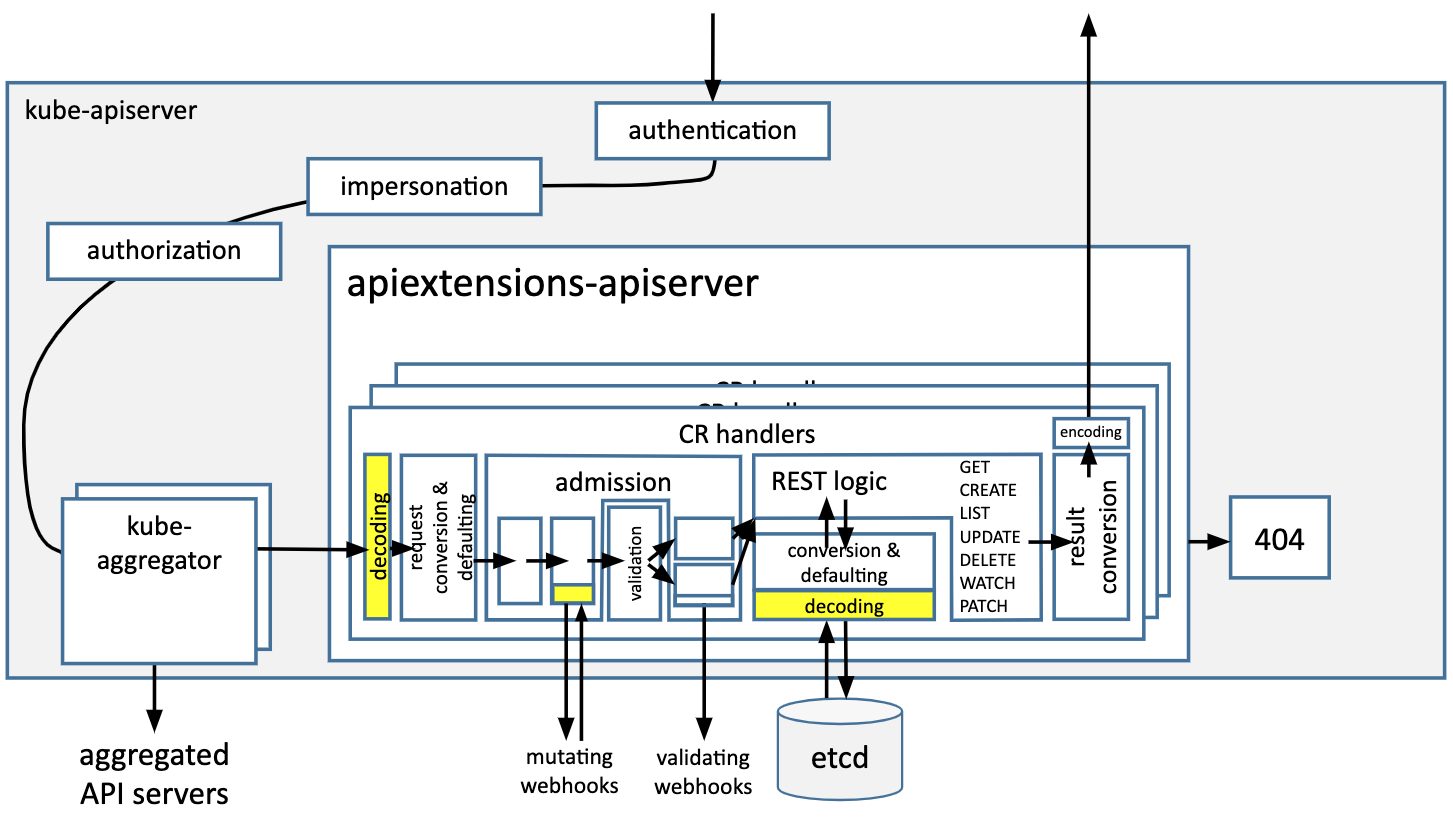
We will also prune after mutating webhooks have been run.
Excluding values from Pruning
There are cases where parts of an object are verbatim JSON, i.e. without any applied schema and especially without a complete specification which allows to apply pruning.
The vendor extension x-kubernetes-preserve-unknown-fields: true proposed in (as defined in the KEP Vanilla OpenAPI Subset: Structural Schema
) serves exactly this purpose, with the following semantics:
The whole JSON subtree X at the level of x-kubernetes-preserve-unknown-fields: true and below is excluded from pruning, with the following exceptions:
- pruning starts again at
Yin the subtree of children ofXifYis specified byproperties. - pruning starts again in the
metadatachild ofYin the subtree ofXifYis specified byx-kubernetes-embedded-resource: true.
We do not allow x-kubernetes-preserve-unknown-fields: false.
Note that (1) does not apply if X and Y are the same, compare examples (7) and (8) below.
Examples
unspecified
type: objectEverything is pruned, i.e.
{ "foo": 42, "json": {"bar": 43} }is pruned to
{}propertiesat top-leveltype: object properties: foo: type: objectEverything other than
foois pruned, i.e.{ "foo": { "abc": 42 }, "json": {"bar": 43} }is pruned to
{ "foo": {} }propertiesat multiple levelstype: object properties: foo: type: object properties: bar: type: objectEverything other than
fooandbaris pruned, i.e.{ "foo": { "bar": { "abc": 42 }, "def": 43 }, "json": {"ghi": 44} }is pruned to
{ "foo": { "bar": {} } }additionalPropertieswith a non-empty schematype: object properties: foo: type: object additionalProperties: type: objectEverything directly inside of
foostays (it is considered a string map), but objects further down are pruned again because they are unspecified, i.e.{ "foo": { "abc": {"x": 42}, "def": {"y": 43} }, "json": {"ghi": 44} }is pruned to
{ "foo": { "abc": {}, "def": {} } }additionalProperties: falsetype: object properties: foo: type: object additionalProperties: falseEverything directly inside of
foostays (it is considered a string map), but objects further down are pruned again because they are unspecified, i.e.{ "foo": { "abc": {"x": 42}, "def": {"y": 43} }, "json": {"ghi": 44} }is pruned to
{ "foo": { "abc": {}, "def": {} } }but validation will fail. We consider the semantical meaning of
falseas value validation, not structural.arbitrary JSON
type: object properties: json: x-kubernetes-preserve-unknown-fields: true nullable: trueInside of
.jsonnothing is pruned, i.e.{ "foo": 42, "json": {"bar": 43} }is pruned to
{ "json": {"bar": 43} }JSON, but with properties at the same level
type: object properties: json: type: object x-kubernetes-preserve-unknown-fields: true nullable: true properties: bar: type: objectInside of
.jsonnothing is pruned, including everything inbar, i.e.{ "foo": 42, "json": { "bar": { "abc": 43 }, "def": 44 } }is pruned to
{ "json": { "bar": { "abc": 43 }, "def": 44 } }JSON, but with properties at the same and lower levels
type: object properties: json: type: object x-kubernetes-preserve-unknown-fields: true nullable: true properties: bar: type: object properties: inner: type: integerThe
propertiesforbar“resets” pruning to normal behaviour, i.e.{ "foo": 42, "json": { "bar": { "inner":43, "abc": 44 }, "def": 45 } }is pruned to
{ "json": { "bar": { "inner": 43 }, "def": 45 } }additionalPropertieswithin JSONtype: object properties: json: type: object x-kubernetes-preserve-unknown-fields: true nullable: true additionalProperties: type: objectThe
additionalPropertiesdisables pruning at its level,x-kubernetes-preserve-unknown-fields: truealready has the same effect. Inside of the additional propertiesx-kubernetes-preserve-unknown-fields: truekeeps being effective, i.e.{ "foo": 42, "json": { "bar": { "inner":43, "abc": 44 }, "def": 45 } }is pruned to
{ "json": { "bar": { "inner":43, "abc": 44 }, "def": 45 } }embedded resource
type: object
properties:
object:
type: object
nullable: true
x-kubernetes-embedded-resource: true
x-kubernetes-preserve-unknown-fields: true
Here, inside of .object nothing is pruned with the exception of unknown fields under .object.metadata, i.e.
{
"foo": 42,
"object": {
"bar": 43,
"abc": 44,
"metadata": {
"name": "example",
"garbage": 45
}
}
}
is pruned to
{
"object": {
"bar": 43,
"abc": 44,
"metadata": {
"name": "example"
}
}
}
- implicit
metav1.TypeMetaandmetav1.ObjectMeta
type: object
Pruning takes place, but apiVersion, kind, metadata and known fields under metadata are preserved, i.e.
{
"apiVersion": "example/v1",
"kind": "Foo",
"metadata": {
"name": "example",
"garbage": 43
},
"foo": 42
}
is pruned to
{
"apiVersion": "example/v1",
"kind": "Foo",
"metadata": {
"name": "example"
}
}
Opt-in and Opt-out of Pruning on CRD Level
We will add a preserveUnknownFields flag to CustomResourceDefinitionSpec of apiextensions.k8s.io/v1beta1 (and later v1):
type CustomResourceDefinitionSpec struct {
...
// PreserveUnknownFields disables pruning of object fields which are not
// specified in the OpenAPI schema. apiVersion, kind, metadata and known
// fields inside metadata are excluded from pruning.
// Defaults to true in v1beta1, and will default to false in v1.
// Setting this field to false is considered an beta API.
PreserveUnknownFields *bool
}
I.e. for apiextensions.k8s.io/v1beta1 this will default to true for backwards compatibility.
For apiextensions.k8s.io/v1 we will change the default to false and forbid true during creation and updates if it has been false before. In v1 the only way to opt-out from pruning is via setting x-kubernetes-preserve-unknown-fields: true in the schema.
We will hide preserveUnknownFields in v1 objects if it is not true.
When CRD authors switch on pruning for an existing CRD, they are supposed to make their users trigger a data migration of existing objects in etcd, be it via an external migration mechanism, an operator rewriting all objects or manual procedures.
References
- Old pruning implementation PR https://github.com/kubernetes/kubernetes/pull/64558 , to be adapted
- OpenAPI v3 specification
- JSON Schema
Test Plan
blockers for alpha:
We default preserveUnknownFields to true and hence switch off the whole code path doing pruning. This reduces risk for everybody not using this feature.
- we add unit tests for the general pruning algorithm
- we add apiextensions-apiserver integration tests to
- verify that the pruning feature is actually off if
preserveUnknownFieldsis true. - verify that
preserveUnknownFieldsis defaulted to true. - verify that pruning happens if
preserveUnknownFieldsis false, for all versions in the CRD according to the schema of the respective version. - verify that
metadata,apiVersion,kindare preserved ifpreserveUnknownFieldsis false and there is no schema given in the CRD.
- verify that the pruning feature is actually off if
blockers for beta:
- we implement and verify that
x-kubernetes-embedded-resourceandx-kubernetes-preserve-unknown-fieldswork as expected. - we add apiextensions-apiserver integration tests to
- verify that pruning happens on incoming request payloads, on read from storage and after calling mutating admission webhooks.
blockers for GA:
- we verified that performance of pruning is adequate and not considerably reducing throughput.
Graduation Criteria
- the test plan is fully implemented for the respective quality level
Upgrade / Downgrade Strategy
We aim at implementing this feature right away as beta:
- in order to get users’ exposure to the feature with real CustomResourceDefinitions
- because the API surface is tiny such that we don’t expect change in that area
- the pruning algorithm is simple enough that we feel confident with thourough test coverage that the risk is small.
Hence, we assume to be at beta in 1.15 and GA in 1.16 guided by the graduation criteria, leading the following upgrade/downgrade strategy:
setting
preserveUnknownFieldsto false is considered beta quality in 1.15.downgrading to 1.14 will lose
preserveUnknownFields: false, but that’s acceptable for beta.downgrading from 1.16 (where pruning might be GA) to 1.15 will keep the same behaviour as we don’t feature gate
preserveUnknownFields: false.upgrading from 1.14 will default to
preserveUnknownFields: trueand hence changes no behaviour.upgrading from 1.15 will keep the value and hence change no behaviour.
when v1 of
apiextensions.k8s.iois added, we will keep the old pruning behaviour for CRDs created in v1beta1 withpreserveUnknownFields: true, but forbidpreserveUnknownFields: truefor every newly create v1 CRD. Hence, we keep backwards compatibility.Technically, it is still possible to get the old behaviour even in v1 by setting
x-kubernetes-preserve-unknown-fields: trueat the root level and in eachpropertiesstatement. But we enforce the definition of a schema, at least with this minimal contents.
Version Skew Strategy
- kubectl is not aware of pruning in relevant way
- posting
preserveUnknownFields: falsebeta quality CRDs to an old server will disable pruning. But that’s acceptable.
Alternatives Considered
in GDoc which preceded this KEP we considered a number of alternatives, including using a skeleton schema approach. We decided against that because of its complex semantics. In contrast, the structural schema of the KEP Vanilla OpenAPI Subset: Structural Schema is the natural output of schema generators deriving a schema from Golang structs. This matches the behavior of pruning through JSON unmarshalling, independently of any value validation the developer adds on top.
we could allow nested
x-kubernetes-preserve-unknown-fields: false, i.e. to switch on pruning again for a subtree. This might encourage non-Kubernetes-like API types. It is unclear whether there are use-cases we want to support which need this. We can add this in the future.we could allow per-version opt-in/out of pruning via
preserveUnknownFieldsinCustomResourceDefinitionVersion. For the goal of data consistency and security a CRD with semi-enabled pruning does not make much sense. The main reason to not enable pruning will probably be the lack of a complete structural schema. If this is added for one version, it should be possible for all other versions as well as it is less a technical, but a CRD development life-cycle question.we intensively considered avoiding a new
x-kubernetes-preserve-unknown-fieldsvendor extension in favor of recursiveadditionalPropertiessemantics. We decided against because:None of OpenAPI v3 schema constructs have effects recursively. We would conflict with that pattern.
E.g.
additionalProperties: falseinvalidates unknown fields only at its level in OpenAPI v3, for example:type: object additionalProperties: false properties: foo: {}(note: this is not allowed in CRDs, but in OpenAPI v3) forbids
{"foo":{},"abc":42}, but not{"foo":{"abc":42}}. A recursive interpretation for pruning would diverge from this pattern.Another example:
additionalProperties: minimum: 42forbids
{"foo":10}, but not{"foo":{"bar":10}}.we stop pruning even for
additionalProperties: falseor any other additional properties schema. We considered to prune forfalse, but not fortrue. We decided against because:- it is unclear what should happen with pruning for non-empty schemas between
falseandtrue. - it is infeasible to compute whether an arbitrary schema is empty (and hence equivalent to
false) or not. Semantically empty schemas andfalseshould behave the same behaviour. This includes pruning.
By not pruning for any explicit value of
additionalProperties(includingfalse) we follow our principle of not trying to consider full semantics of OpenAPI including value validation when doing structural operations like pruning.Compare example (5): CustomResource validation will eventually forbid unpruned values. The semantical meaning of the schema
falseis considered non-structural and therefore not relevant for pruning.- it is unclear what should happen with pruning for non-empty schemas between